Internet Protocol
Introduction
IP 是整個網路中最廣為人知的協議,它位於第三層網路層,是網路能夠串連起來的基礎。
網路並不是由一個單一的系統所構成,而是由非常多獨立的網路組合而成,也就是所謂的 Network of Networks。 在這個巨大的網路集合中,每個網路內部都有不同的規則以及連接方式,而我們不可能統一所有的硬體來讓網路能互相連結,因此,需要有一個標準來讓這些網路彼此能互相溝通,而這個標準就是 IP。
IP 協議中包含了三個重要的概念 :
- packet switch : 網路拋棄了傳統的 circuit switch 方式,而是將資料分割成 packet,每個 packet 都是獨立的單位,這使得路由器在處理封包時不需要關心其他封包的狀況
- address : IP 為每個連上網路的設備提供了一個地址,使網路中的每一個設備都能被準確定位
- best effort model : IP 並不保證封包一定會送達,也不保證不會失序或重複發送,這個決定看似不是很好,但正是因為放棄了這些保證,使得網路可以輕易的擴張
IP Address
在 IP 協議中,有 IPv4 跟 IPv6 兩種不同的地址,其中 IPv4 的地址長度是 32 bit (255.255.255.255),而 IPv6 則是 128 bit (2001:0db8:85a3:0000:0000:8a2e:0370:7334),IPv6 是為了解決 IPv4 地址不夠的問題而誕生的。
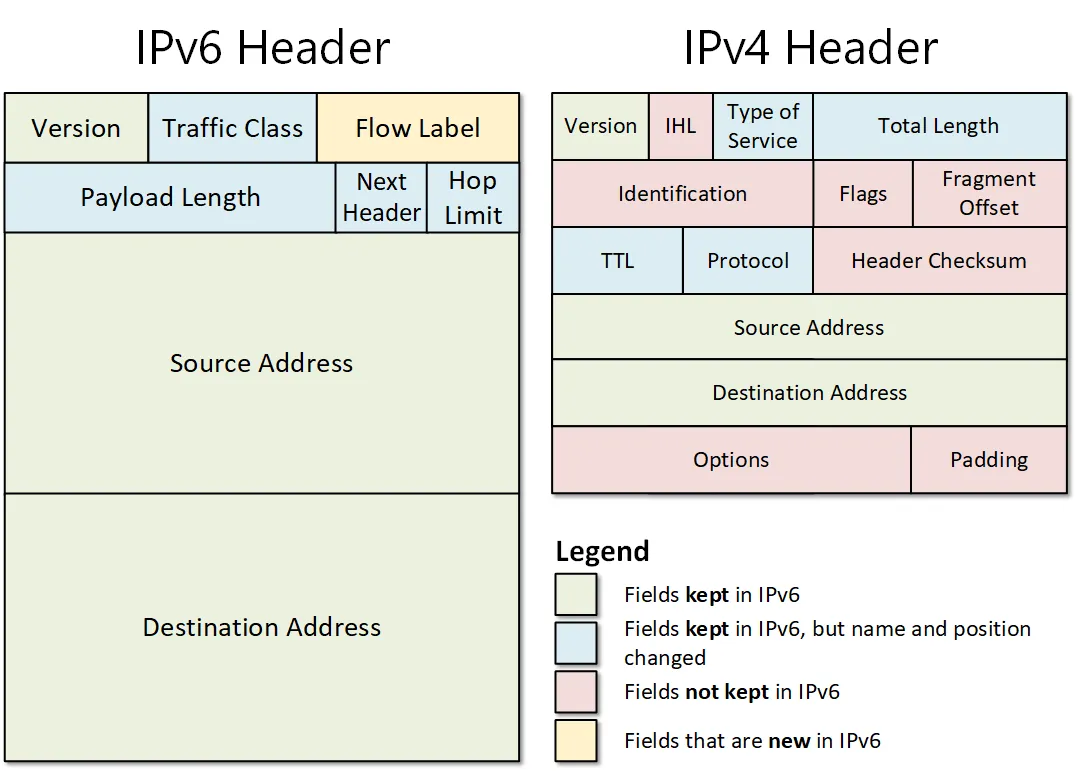
IPv4
Version: 用來表示是 IPv4 還是 IPv6IHL: 定義標頭有多長,預設是 5 (20 Bytes),最大是 15 (60 Bytes)Type of Service: 用來標記封包的優先權,現代被 DSCP 跟 ECN 所使用Identification: 是來自哪個大封包Flags: 是否允許切封包以及是不是最後一個封包Fragment Offset: 這個封包在原本的哪個位置TTL: 存活時間,每經過一個路由器就 -1,防止封包在網路上無限傳Protocol: 告訴接收端裡面的封包是哪個協議 (1=ICMP, 6=TCP, 17=UDP)Header Checksum: 用於檢查標頭是否損壞Source Address: 來源 IPDestination Address: 目標 IP
其中 Identification、Flags、Fragment Offset 是用於分片的欄位,當一個大的封包通過一個較窄的網路時,路由器就需要幫忙拆分封包。
IPv6
Version: 同 IPv4 的 VersionTraffic Class: 同 IPv4 的 Type of ServiceFlow Label: 用於標記是同一個 TCP 連線的封包Payload Length: Data 的大小 (不含 header)Next Header: IPv6 採用鏈狀的形式來擴充標頭,每個擴充標頭都會有這個欄位,直到指向最後一個標頭Hop Limit: 同 IPv4 的 TTLSource Address: 來源 IPDestination Address: 目標 IP
其中 Flow Label 的設計比較有意思,雖然前面說 IP 並不保證封包不會亂序,但實際上為了效能考量還是會盡可能的保證順序來避免 TCP 重傳,以往這個操作需要讀取到第四層的 port 號來判斷,現在可以直接透過 IP + flow label 來判斷,減少拆包的耗時。
透過欄位可以知道,IPv6 跟 IPv4 最大的差別是 :
- 移除 checksum,因為 TTL 在每一跳都會減少,導致 checksum 在每一跳都要重算相當耗時,再加上原本第四層跟第二層也都有檢查機制,因此就在第三層移除了這個檢查
- 移除分片,如果因為封包太大過不去則會直接回傳錯誤並交給發送端重新處理
From IPv4 to IPv6
既然 IPv4 跟 IPv6 有完全不一樣的結構,那麼在這個過渡的期間要怎麼讓所有的網路設備都可以理解 IPv6 的封包就是一個需要考慮的問題。
最常見的方式是使用 tunnel 來將完整的 IPv6 封包放到 IPv4 裡面,讓封包變成 IPv4 Header + IPv6 Header + Data 的形式,並同時把 IPv4 的 Protocol 改成 41,告訴接收端裡面是 IPv6。 但這樣帶來的問題是可能會使封包的大小超過 MTU,從而導致需要分片。
Subnet
早期的網路使用 Class 的方式來管理 IP 的分配,主要分為 :
- class A (/8) : = 16,777,216
- class B (/16) : = 65,536
- class C (/24) : = 256
但這麼做有很多的問題,像是如果有公司需要申請 1000 個網址,那它就只能申請 class B,導致了六萬個網址的浪費,因此後來提出的 CIDR 使用了 subnet mask 的概念,不再分配 ABC,而是直接使用 /22 來獲得 1000 個網址。
舉例來說,有一個 IP 192.168.1.130 的遮罩是 255.255.255.128 (/25),這就代表前 25 位決定了他在哪個子網,而後 7 位就是指在這個子網的哪個設備。
而當封包進入到路由器時,路由器就會察看它的路由表並依據最長前綴來匹配。
而有些 IP 則有一些特殊的意義,如 10.0.0.0/8、172.16.0.0/12、192.168.0.0/16 就是專供內部網路使用,而 127.0.0.0/8 則不會離開網路卡 (127.0.0.1 常用於 localhost)。
IP related protocol
到目前為止,我們已經了解了 IP 的格式以及用途,接下來會介紹一些與 IP 相關的常見協議。
DHCP
DHCP 的全名是 Dynamic Host Configuration Protocol,顧名思義,它可以動態分配 IP 跟一些相關的設定。
在早期沒有 DHCP 的時候,電腦獲取 IP 的方式是使用像 RARP 或是 BOOTP 的協議來取得 IP,但這兩個協議都有一些缺點 :
- RARP 只能分配 IP 地址,無法提供其他資訊
- BOOTP 基於 RARP 改善了只能分配 IP 的缺點,但仍然需要手動綁定 MAC 地址跟 IP 地址
由於後來可以聯網的設備越來越多,管理員無法手動一一管理這些配對,因此就出現了 DHCP,相當於自動把一個 IP 租給你一段時間。
DHCP 的步驟如下 :
- 電腦發送 DHCP 廣播
- DHCP Server 回覆 IP
- 由於可能收到多組回覆,因此電腦挑要的那個 IP 回覆確定
- DHCP Server 回覆確定
除了 IP 之外,DHCP 還會回傳 Default Gateway 跟 DNS Server 等等的資訊,可以透過 ipconfig 查看。
ipconfig /all
Wireless LAN adapter Wi-Fi:
Connection-specific DNS Suffix . :
Description . . . . . . . . . . . : Intel(R) Wi-Fi 6 AX201 160MHz
Physical Address. . . . . . . . . : 70-D8-23-B6-7A-1F
DHCP Enabled. . . . . . . . . . . : Yes
Autoconfiguration Enabled . . . . : Yes
IPv6 Address. . . . . . . . . . . : 2402:7500:59a:faf6:fc83:a05:5a31:5b4e(Preferred)
Temporary IPv6 Address. . . . . . : 2402:7500:59a:faf6:54df:6c46:ce41:a700(Preferred)
Link-local IPv6 Address . . . . . : fe80::b9d:feaf:a050:97e8%19(Preferred)
IPv4 Address. . . . . . . . . . . : 10.126.52.186(Preferred)
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Lease Obtained. . . . . . . . . . : Friday, January 16, 2026 8:16:27 AM
Lease Expires . . . . . . . . . . : Friday, January 16, 2026 10:16:22 AM
Default Gateway . . . . . . . . . : fe80::d4f6:bdff:fe18:86b8%19
10.126.52.171
DHCP Server . . . . . . . . . . . : 10.126.52.171
DHCPv6 IAID . . . . . . . . . . . : 309385251
DHCPv6 Client DUID. . . . . . . . : 00-01-00-01-2C-8E-E0-8A-08-BF-B8-15-4A-8C
DNS Servers . . . . . . . . . . . : 8.8.8.8
1.1.1.1
2402:7500:59a:faf6::db
NetBIOS over Tcpip. . . . . . . . : Enabled
IPv4 Address: 電腦被分配到的 IP 位址Subnet Mask: 子網路遮罩Default Gateway: 預設閘道,當封包不是發送到本地網路時,會送到這個位址DNS Servers: DNS 伺服器的位址,用來解析網域名稱
NAT
IPv4 是一個誕生在 1980 年代的協議,當時認為 次方的 IP 地址 (43 億) 足以讓全世界所有的設備都連上網路,但不曾想網路在後來出現了爆炸性的增長,導致 IP 地址快速接近枯竭。 而當時的 IPv6 才剛處於起步狀態,因此迫切的需要一個臨時解決方案來處理地址耗盡的問題,而 NAT (Network Address Translation) 正是在這樣的背景下誕生的。
NAT 的做法是不需要每台電腦都有一個固定的 IP,而是把 IP 分成公有 IP 跟私有 IP,每個機構或家庭只需要一個公有 IP 即可。
當有網路請求出去的時候,路由器會自動記錄一組映射 (ip:port),如將本地網路的 10.126.52.186:8080 映射成 49.218.144.209:22222,返回時也是一樣,這樣就能大幅減少公有 IP 的需求。
ARP
在網路分層的時候有提到過,網路的第二層需要 MAC 地址來幫助轉發,而 ARP 就是透過 IP 地址尋找 MAC 地址的協議。
ARP 的步驟如下 :
- 發送人會先檢查自己本地的 ARP 表,如果沒有就會發送 ARP 廣播
- 收件人收到廣播後就會回傳自己的 MAC 地址
- 發送人將收到的 MAC 地址存到自己的 ARP 表中
可以使用 arp -a 查看自己的 arp 表。
arp -a
Interface: 10.126.52.186 --- 0x13
Internet Address Physical Address Type
10.126.52.171 d6-f6-bd-18-86-b8 dynamic
10.126.52.255 ff-ff-ff-ff-ff-ff static
224.0.0.22 01-00-5e-00-00-16 static
224.0.0.251 01-00-5e-00-00-fb static
224.0.0.252 01-00-5e-00-00-fc static
239.255.255.250 01-00-5e-7f-ff-fa static
255.255.255.255 ff-ff-ff-ff-ff-ff static
ICMP
前面提到過,IP 協議只負責盡最大努力將封包傳送到目的地,它不保證一定會送到,也不會告訴你中途發生了甚麼,而有時我們又需要這些資訊來幫助我們排查問題,這時候就需要用到 ICMP (Internet Control Message Protocol) 協議。
ICMP 也是一個屬於網路層的協議,但它與 TCP / UDP 協議相同,都是包在 IP 協議之中,其中 Type 跟 Code 兩個欄位會包含一些有用的資訊,詳細可以參考維基百科。
當路由器收到一個無法處理的封包,如太長或找不到目標時,就會丟棄該封包並回傳一個 ICMP 封包告訴發送端,而我們就可以透過回傳的資訊來定位問題。
Ping
ping 是一個常用於檢測網路的常用工具,它可以告訴我們網路是否可以連線、封包的遺失率以及延遲。
ping 的做法就是發送一個 ICMP Type 8 (Echo Request) 的封包,並塞到 IP 中發送,接收方收到就會回傳 ICMP Type 0 (Echo Reply) 給發送方。
下面會用 ping 發送 3 次指令給 8.8.8.8,並用 tcpdump 觀察結果 :
ping -c 3 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=115 time=254 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=115 time=196 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=115 time=36.8 ms
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 36.809/162.092/253.769/91.705 ms
sudo tcpdump -v -n -i eth0 icmp
tcpdump: listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
13:28:46.384282 IP (tos 0x0, ttl 64, id 32032, offset 0, flags [DF], proto ICMP (1), length 84)
172.28.35.229 > 8.8.8.8: ICMP echo request, id 801, seq 1, length 64
13:28:46.503464 IP (tos 0x60, ttl 115, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.28.35.229: ICMP echo reply, id 801, seq 1, length 64
13:28:47.385838 IP (tos 0x0, ttl 64, id 32085, offset 0, flags [DF], proto ICMP (1), length 84)
172.28.35.229 > 8.8.8.8: ICMP echo request, id 801, seq 2, length 64
13:28:47.533233 IP (tos 0x60, ttl 115, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.28.35.229: ICMP echo reply, id 801, seq 2, length 64
13:28:48.387770 IP (tos 0x0, ttl 64, id 32091, offset 0, flags [DF], proto ICMP (1), length 84)
172.28.35.229 > 8.8.8.8: ICMP echo request, id 801, seq 3, length 64
13:28:48.536306 IP (tos 0x60, ttl 115, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.28.35.229: ICMP echo reply, id 801, seq 3, length 64
Traceroute
traceroute 指令可以觀察封包在網路上會經過那些路由器,它是透過 IP 標頭中的 TTL 來實現的。
每當封包經過一個路由器的時候,TTL 就會減一,而 traceroute 就是利用這點。
第一次它會發送 TTL = 1 的封包,等收到超時訊息之後就能確定第一個路由器的 IP,接著他再發送 TTL = 2 的封包,就可以用同樣的方式獲得第二台路由器的 IP,依此類推。
在不同平台上 traceroute 會有不同的實作方式,如在 Windows 中預設是使用 ICMP,而在 Mac / Linux 則是預設使用 UDP。
sudo traceroute -I 1.1.1.1
1 172.28.32.1 (172.28.32.1) 0.244 ms 0.196 ms *
2 * * *
3 * * *
4 * * *
5 * * *
6 * * *
7 60-199-4-177.static.tfn.net.tw (60.199.4.177) 124.436 ms 124.436 ms 124.435 ms
8 60-199-3-194.static.tfn.net.tw (60.199.3.194) 128.461 ms 128.462 ms 128.460 ms
9 60-199-14-97.static.tfn.net.tw (60.199.14.97) 128.236 ms 128.206 ms 128.189 ms
10 60-199-24-138.static.tfn.net.tw (60.199.24.138) 128.171 ms * *
11 * * one.one.one.one (1.1.1.1) 40.160 ms
sudo tcpdump -n -v -i eth0 icmp
tcpdump: listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:10:15.669587 IP (tos 0x0, ttl 1, id 15131, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 1, length 40
17:10:15.669594 IP (tos 0x0, ttl 1, id 15132, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 2, length 40
17:10:15.669603 IP (tos 0x0, ttl 1, id 15133, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 3, length 40
17:10:15.669625 IP (tos 0x0, ttl 2, id 15134, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 4, length 40
17:10:15.669633 IP (tos 0x0, ttl 2, id 15135, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 5, length 40
17:10:15.669641 IP (tos 0x0, ttl 2, id 15136, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 6, length 40
17:10:15.669789 IP (tos 0x0, ttl 128, id 6, offset 0, flags [none], proto ICMP (1), length 88)
172.28.32.1 > 172.28.35.229: ICMP time exceeded in-transit, length 68
IP (tos 0x0, ttl 1, id 15131, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 1, length 40
17:10:15.669789 IP (tos 0x0, ttl 128, id 7, offset 0, flags [none], proto ICMP (1), length 88)
172.28.32.1 > 172.28.35.229: ICMP time exceeded in-transit, length 68
IP (tos 0x0, ttl 1, id 15132, offset 0, flags [none], proto ICMP (1), length 60)
172.28.35.229 > 1.1.1.1: ICMP echo request, id 1105, seq 2, length 40
這裡由於太長就只擷取一部分,但可以觀察到,每個 TTL traceroute 都會發送三次,而路由器也確實有回覆 ICMP time exceeded in-transit。