Distributed OLAP Database Systems
這篇筆記會延續上一篇的內容,繼續介紹分散式資料庫系統,並且重點放在 OLAP 系統上。
Decision Support System (DSS)
決策支持系統是用於協助組織的管理層、運營層和規劃層進行決策的應用程式。 DSS 通過分析存儲在資料庫中的歷史數據,幫助人們針對未來的問題和挑戰做出明智的決策。
OLAP and OLTP
資料庫有兩種使用場景,OLTP 和 OLAP。
OLTP 負責與正在運行中的應用程序交互,再透過異步的方式將數據同步到 OLAP 系統中作分析。
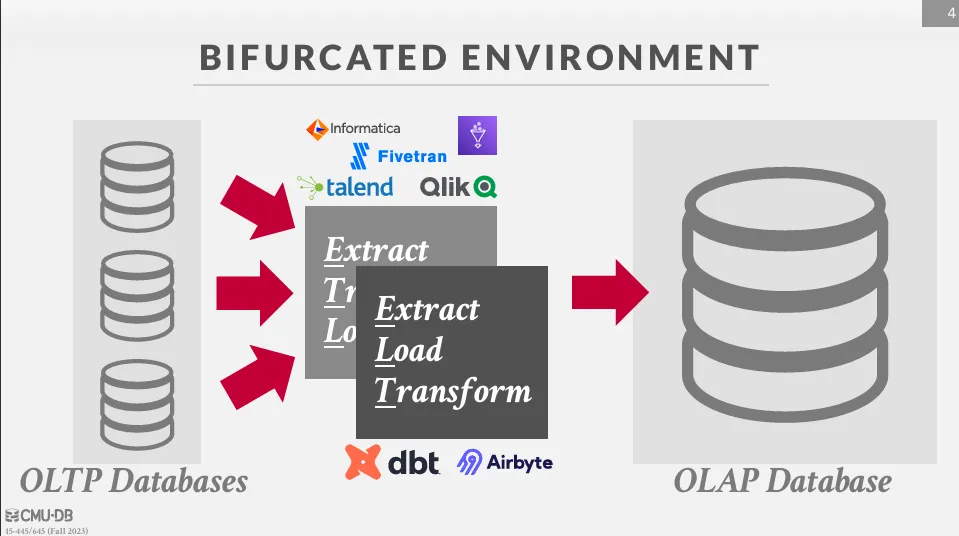
OLTP 資料庫中的資料會通過一些流程將資料轉移到 OLAP 資料庫中,主要有兩種方式 :
- ETL (Extract, Transform, Load) : 傳統的處理方式,需要一個中間層來處理資料的轉換
- ELT (Extract, Load, Transform) : 現代的處理方式,直接將資料載入 OLAP 資料庫中,然後在資料庫中進行轉換
在資料轉換的過程中,我們不只是簡單的搬移資料,通常還會對表的結構進行轉換,來提高分析的效能,常見的 scheme 有以下兩種 :
- Star Schema
- Snowflake Schema
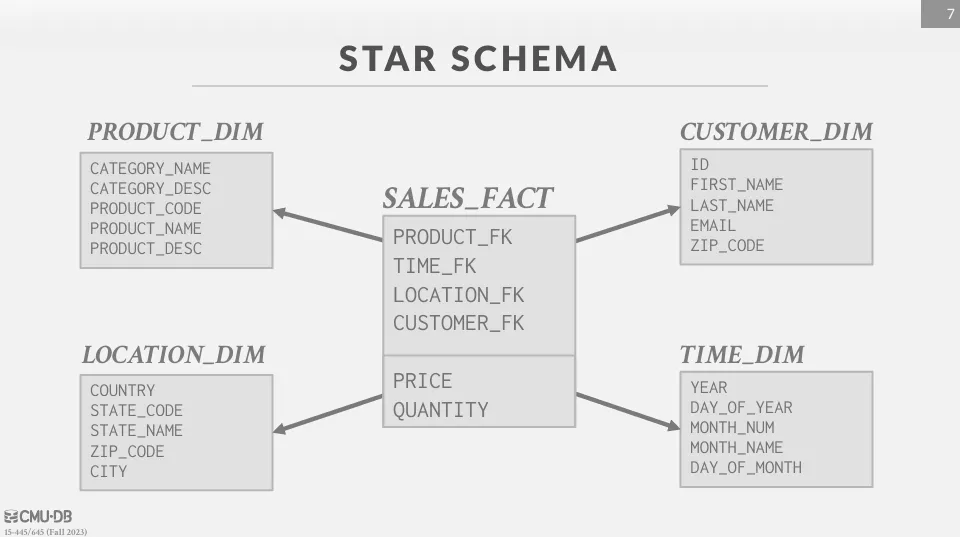
Star Schema
Star schema 主要分成兩種表,fact table 和 dimension table。
Fact table 通常儲存應用程式的核心事件以及指標,而 dimension table 則是對 fact table 的描述,兩者會通過 foreign key 進行關聯,且只能允許一層關聯。
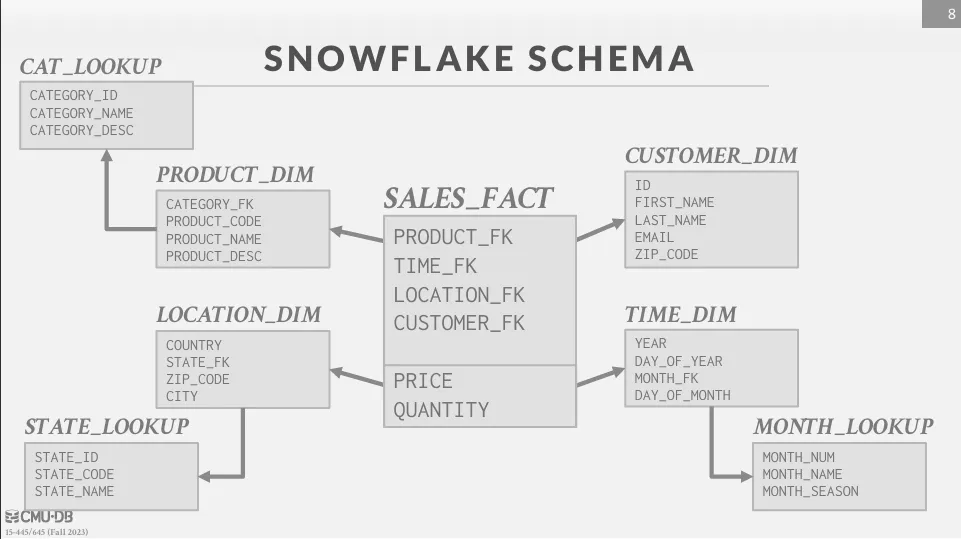
Snowflake Schema
Snowflake schema 與 star schema 類似,但 dimension table 可以進一步分解成多個表,這樣可以減少重複的資料。
Star vs Snowflake
這兩種 schema 都有各自的優缺點,star schema 簡單直觀,但可能會有大量的重複資料,而 snowflake schema 可以減少重複資料,但可能會增加 join 的複雜度。
Execution Model
分散式資料庫管理系統的執行模型定義了在查詢執行過程中,系統如何在不同節點之間進行通信,通常有兩種方式 :
- Pushing a Query to Data
- Pull Data to Query
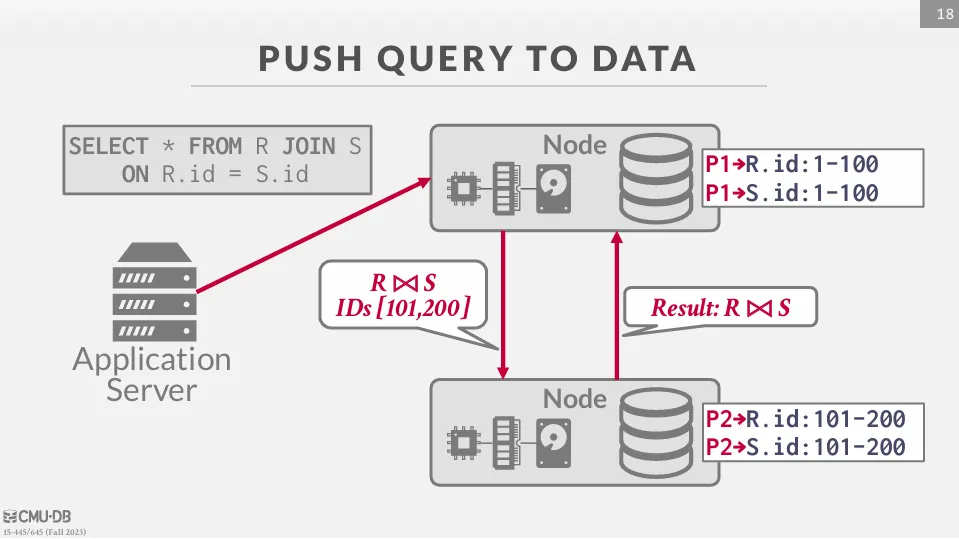
Pushing a Query to Data
在這種方法中,DBMS 將查詢 (或部分查詢) 推送到包含所需資料的節點,並在當地執行過濾和處理,最大限度地減少網路上的數據傳輸。
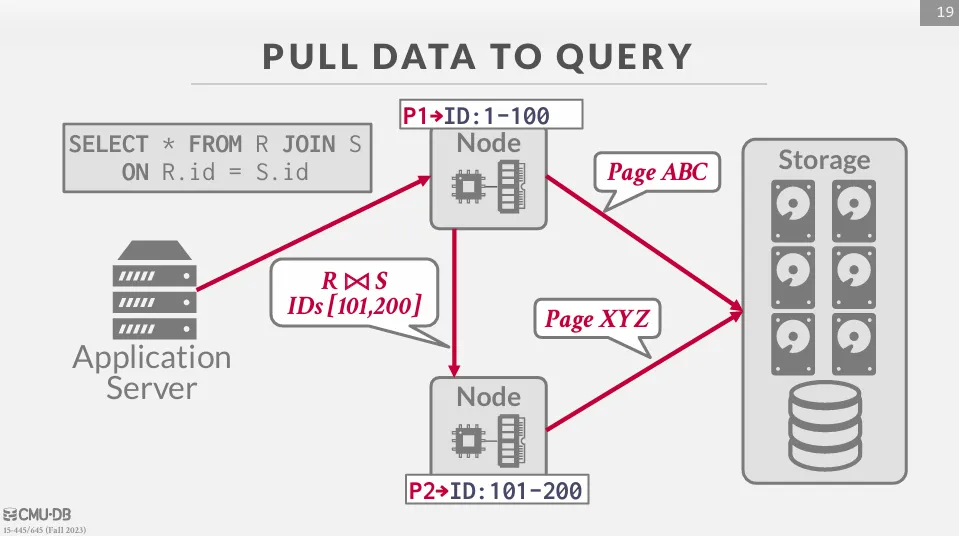
Pull Data to Query
在這種方法中,DBMS 將需要處理的資料拉取到執行查詢的節點,通常是 shared-disk 的架構才會這麼做,因為所有節點都可以存取相同的資料。
Query Fault Tolerance
節點從遠端來源接收的資料會被緩存在緩衝池中,方便進行查詢,也可以暫時持久化到臨時文件中。 Ephemeral Pages 在重新啟動後不會被持久化,因此如果在查詢執行期間節點發生崩潰,分散式 DBMS 需要考慮如何處理長時間執行的 OLAP 查詢。
大多數的分散式 OLAP 在設計時假設節點在查詢執行期間不會失敗。如果查詢執行過程中某個節點失敗,那麼整個查詢將會失敗,必須從頭開始執行,這對於需要數天才能完成的 OLAP 查詢來說代價高昂。 因此 DBMS 可以在查詢執行過程中對中間結果進行快照,以便在節點失敗時能夠恢復。 然而,這一操作非常昂貴,因為將資料寫入硬碟的速度較慢。
Query Planning
在分散式環境中,query planning 的過程變得更加複雜,因為資料分佈在多個節點上,並且每個節點的計算和儲存資源可能有所不同。 因此,查詢計畫不僅需要考慮到傳統的優化技術,還需要考慮到節點之間資料的移動成本和延遲。
在 single node 時所提到的優化技術仍然適用於分散式環境,像是 :
- Predicate Pushdown
- Early Projections
- Optimal Join Orderings
在分散式系統中有兩種粒度可以進行優化 :
- Physical Operators : 先生成一個單一的全域查詢計畫,然後將物理運算符分配給不同的節點,將其拆分為針對特定分區的計畫片段,一般 DBMS 會使用這種方法
- SQL : 將原始的 SQL 改寫成適合在各個節不同點上執行的 SQL
Distributed Join Algorithm
在分散式系統中,同一個表中的 tuple 可能會在不同的節點上,因此在進行聯接操作時,需要考慮到不同的場景。
接下來會討論下面這條 SQL 在不同的場景下的執行方式。
SELECT *
FROM R
JOIN S ON R.id = S.id
Scenario 1
在這個場景中,一個表被複製到每個節點,而另一個表則按鍵分區到各個節點。
每個節點在本地執行聯接操作,然後將結果發送到 coordinating node 進行聚合。

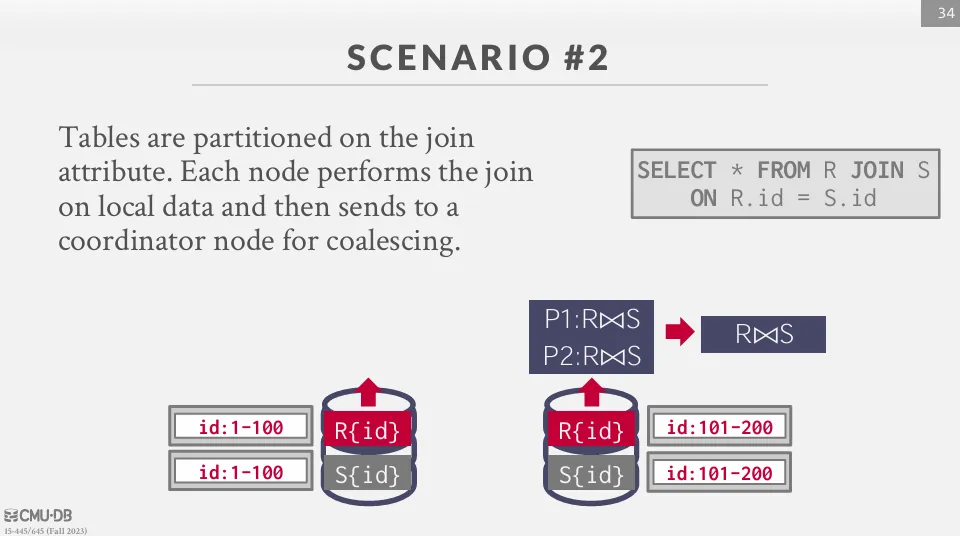
Scenario 2
在這個場景中,兩個表都按 join attribute 進行分區。
每個節點執行本地聯接操作,然後發送到一個節點進行合併。
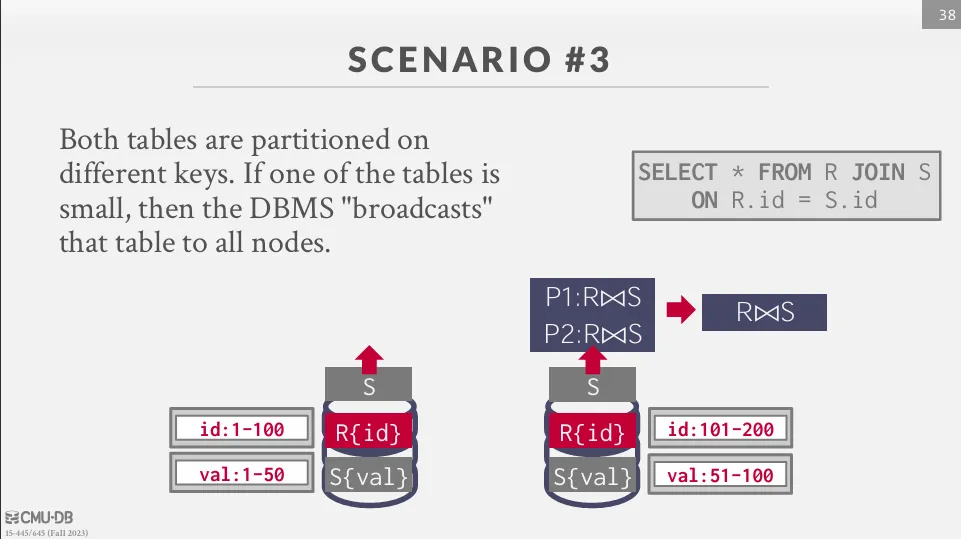
Scenario 3
在這個場景中,兩個表按不同的鍵進行分區。
如果其中一個表較小,DBMS 可以將該表廣播到所有節點,並在本地進行 join,最終將結果發送到一個節點聚合,這種情況被稱為 Broadcast Join。
Scenario 4
在這個場景中,兩個表都未按 join key 進行分區。
DBMS 需要重新分配這些表,將它們根據 join key 進行 shuffle,然後在本地執行聯接,最終將結果發送到 coordinating node。

Semi-Join
半聯接是一種聯接操作,其結果只包含來自左表的欄位。 DBMS 可以使用 semi join 來最小化聯接過程中傳輸的資料量。
舉例來說,假設我們有兩個表,Employees (1e) 和 Departments (1k),分別存在 Node A 和 Node B。
我們要找出所有在台北工作的員工,可以使用下面的 SQL 查詢 :
SELECT e.*
FROM Employees e
WHERE e.DeptID IN (
SELECT d.DeptID
FROM Departments d
WHERE d.Location = 'Taipei'
);
這時候我們不用把兩張表傳到同一個節點來做 join,而是先在 Node B 上執行子查詢,找出所有在台北的部門 ID,然後將這些 ID 傳回 Node A。
Cloud System
在現代的雲端環境中,雲端供應商會提供一個完全受控管的資料庫環境。 用戶不再需要擔心底層的硬體採購、軟體安裝、系統維護等繁瑣工作,可以專注於應用程式開發。
現代雲端系統的一個重要趨勢是架構的融合,它們開始模糊傳統 Shared-Nothing 跟 Shared-Disk 架構之間的界線。 例如,像 Amazon S3 這樣的物件儲存服務,允許在將資料複製到計算節點之前進行初步的篩選和處理,這體現了儲存與計算之間更深度的協同作用。
OLAP 資料庫的雲端服務主要分成兩類 :
- Managed DBMS : 將開源的資料庫移到雲端,並做一些小修改
- Cloud-Native DBMS : 為雲原生設計的資料庫,通常基於 shared-disk
Serverless
無伺服器資料庫是一種動態管理計算資源的 DBMS 模式。 當用戶的應用程式處於空閒狀態時,系統會將計算資源釋放,同時將當前進度檢查點存儲到磁碟上。 當應用重新啟動時,系統就會自動恢復之前的狀態,而使用者只需要為實際使用的存儲和計算資源付費。
Data Lake
Data Lake 是一種集中的資料存儲庫,用於儲存大量結構化、半結構化和非結構化數據,無需預先定義架構或轉換為內部格式,可以儲存各種類型的資料,但需要使用者自行轉換和處理。
OLAP Commoditization
過去幾十年間,OLAP 引擎子系統的商品化成為一種趨勢,許多非 DBMS 供應商的組織開始將這些子系統分拆為獨立的開源組件。
這些組件主要包括 System Catalogs、Query Optimizers、File Format / Access Libraries、Execution Engines 等等。
System Catalogs
系統目錄是 DBMS 中保存資料庫結構的元數據的資料庫。 它包含有關資料庫結構的資訊,例如資料表、索引、視圖、資料類型以及使用者和權限等。 系統目錄讓 DBMS 能夠知道如何存取和管理儲存在資料庫中的資料。
- HCatalog
- Google Data Catalog
- Amazon Glue Data Catalog
Query Optimizers
Query Optimizer 是 DBMS 中最困難的部分之一,用於為基於啟發式和基於成本的查詢優化提供擴展性框架。 DBMS 提供轉換規則和成本估算,框架返回邏輯或物理查詢計劃。
- Greenplum Orca
- Apache Calcite
Data File Formats
大多數 DBMS 使用專有的二進制文件格式來存儲資料庫。 系統之間的資料共享通常需要將資料轉換為通用的文本格式 (如 CSV、JSON 和 XML)。 然而,近年來出現了多種開源二進制文件格式,使得跨系統訪問變得更容易。
- Apache Parquet : 來自 Cloudera/Twitter 的壓縮列式存儲格式
- Apache ORC : 來自 Apache Hive 的壓縮列式存儲格式
- Apache CarbonData : 來自華為的帶索引的壓縮列式存儲格式
- Apache Iceberg : 來自 Netflix 的支持架構演化的靈活數據格式
- HDF5 : 用於科學工作負載的多維數組格式
- Apache Arrow : 來自 Pandas/Dremio 的內存壓縮列式存儲格式
Execution Engines
Execution Engine 是資料庫系統中實際執行 SQL 查詢的部分。 當 Query Optimizer 生成了一個最佳的查詢計畫後,執行引擎負責逐步執行這些計畫中的操作。
- Velox
- DataFusion
- Intel OAP