Distributed OLTP Database Systems
在上一篇筆記中,我們討論了基本的分散式資料庫系統,但仍然有很多細節沒有討論到。
這篇會討論一些分散式 OLTP 系統的細節,像是 :
- 如果其中有節點發生故障怎麼處理
- 如果訊息在網路上延遲怎麼處理
- 是否需要所有節點都同意才能 commit 一個 transaction
我們假設所有的節點都是可信任的,不然就需要採用 Byzantine Fault Tolerance 的方法。
Replication
DBMS 可以將資料複製到多個節點上以實現高可用性。
在實現上,有幾個重要的考慮因素 :
- Replication Configuration
- Propagation Scheme
- Propagation Timing
- Update Method
Replication Configuration
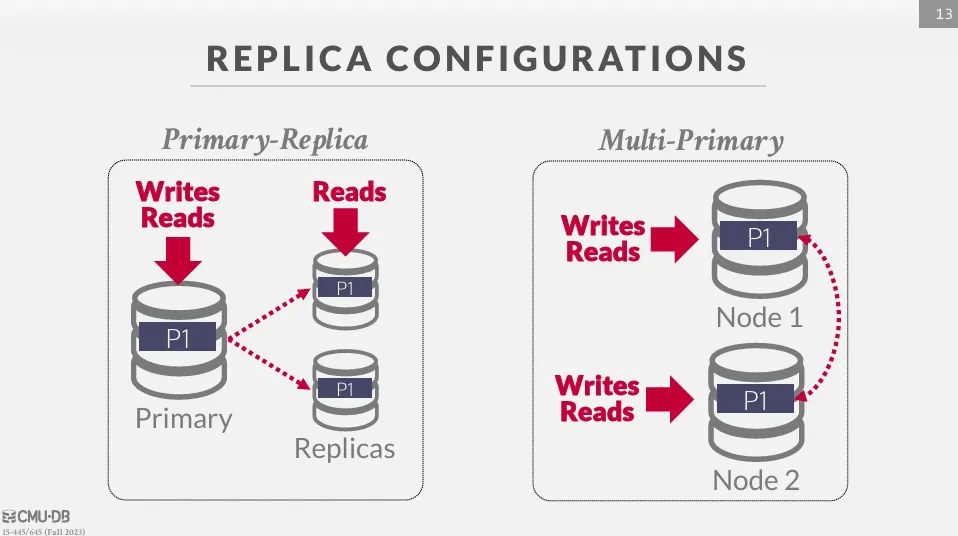
為了了確保資料的高可用性,DBMS 通常會將資料複製到多個節點上,這些節點可以分佈在不同的地理位置,以防止單點故障 (SPOF)。 主要可以分為兩種方式 :
- Primary-Replica : 所有關於寫的操作都會先寫到 primary node,primary node 更新完後再通知其他 replica node 更新,而只讀的資料可以直接從 replica node 讀取。如果 master 節點崩潰,則由共識算法選擇新的 master 節點
- Multi-Master : 每個節點都可以更新資料,但節點之間需要透過 atomic commit protocol 來確保一致性
K-safety
K-safety 是用來衡量資料庫的容錯能力的閾值,K 值表示每個物件必須始終可用的副本數量,如果副本數量低於這個閾值,DBMS 會停止系統。
Propagation Scheme
當交易在資料庫上提交時,DBMS 會決定是否需要等待該交易傳播到其他節點後再向應用程式客戶端發送確認,主要有兩種方式 :
- Synchronous Propagation : 主節點將更新發送到從節點,並等待它們確認已完全應用更改後,再通知客戶端更新成功。這種方法確保了強一致性,不會丟失任何數據
- Asynchronous Propagation : 主節點在本地更新完後立即向應用程式返回確認,而不等待從節點更改完成。可能會導致讀取過期數據,但如果可以容忍某些數據丟失,這種方式是一種有效的優化

Propagation Timing
主節點甚麼時候將更新發送到從節點的策略,主要有兩種方式 :
- Continuous Propagation : DBMS 在生成 log 後立即發送 log 給從節點,其中包括提交和中止消息
- On Commit Propagation : DBMS 只有在交易提交後才將該交易的 log 發送到從節點,避免了為 abort 的交易傳送 log,但會導致同步效率較低
Active vs Passive
根據如何將更改應用到從節點上,複製可以分為兩種方式 :
- Active-Active : 交易在每個從節點上獨立執行,最後 DBMS 檢查每個節點上的結果是否一致,以確保交易正確提交
- Active-Passive : 交易在一個節點上執行,然後將總體更改傳播到從節點
Atomic Commit Protocols
在多個節點上執行交易時,DBMS 需要確保所有節點都同意提交或中止交易,以確保資料的一致性,這就是原子提交協議 (Atomic Commit Protocols) 的作用。
通常來說,這種協議需要保證以下幾點 :
- Stability : 決定後不可更改
- Consistency : 所有節點一致
- Liveness : 協議能持續推進
常見的協議包括 :
- Two-Phase Commit (2PC)
- Three-Phase Commit (3PC)
- Paxos
- Raft
- Zookeeper Atomic Broadcast (ZAB)
- Viewstamped Replication
這裡主要討論 2PC 和 Paxos。
Two-Phase Commit (2PC)
2PC 是一個經典的分散式交易提交協議,分為兩個階段 :
- Prepare Phase
- Commit Phase
2PC Success
首先應用程式會向協調者發送提交請求之後進入準備階段 (prepare phase)。
協調者向參與節點發送 prepare 請求,詢問它們是否可以提交當前交易
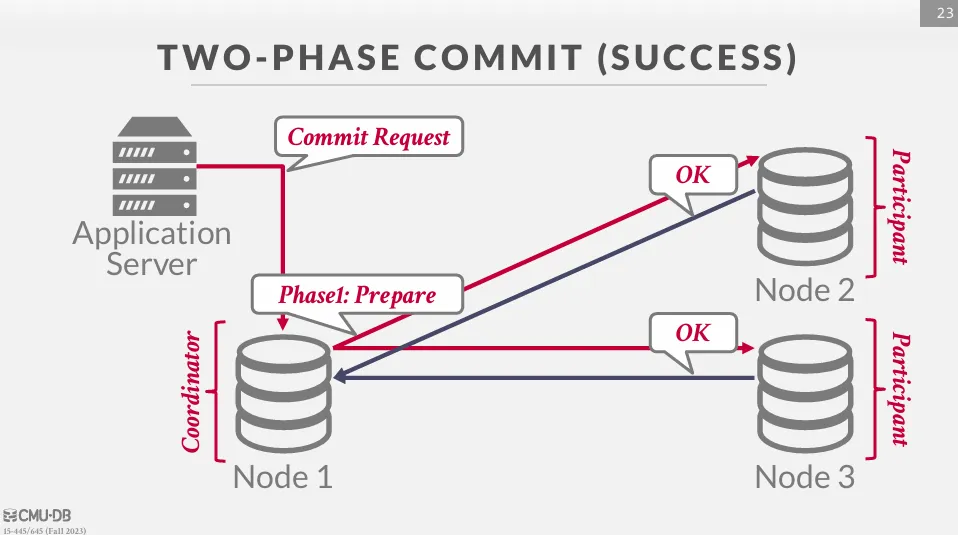
等待所有節點回覆 OK 後,則進入提交階段 (commit phase)。
協調者會向所有參與者發送提交消息,通知它們提交交易。
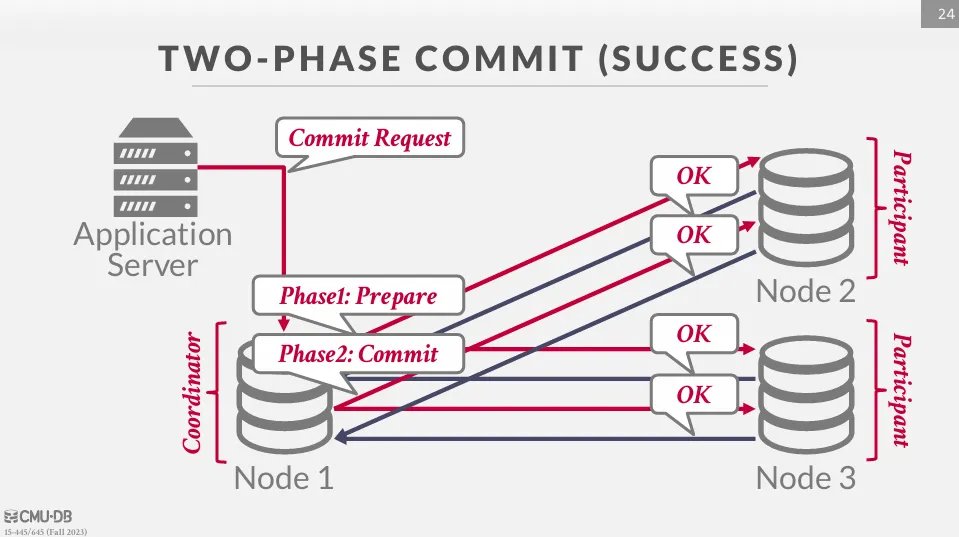
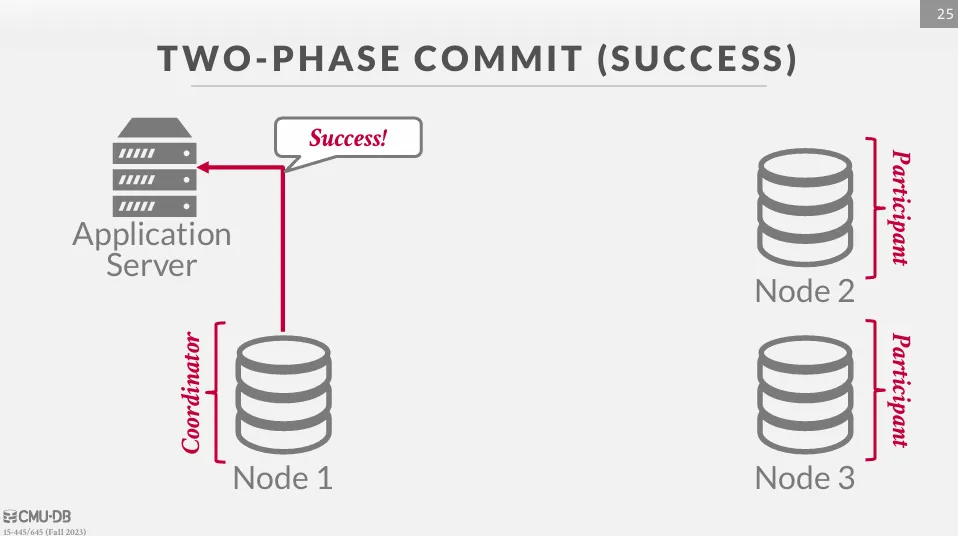
等待所有交易提交後,協調者向應用程式回覆提交成功。
2PC Abort
在準備階段時,如果有任何一個節點無法執行,則應該回覆 ABORT 給協調者。
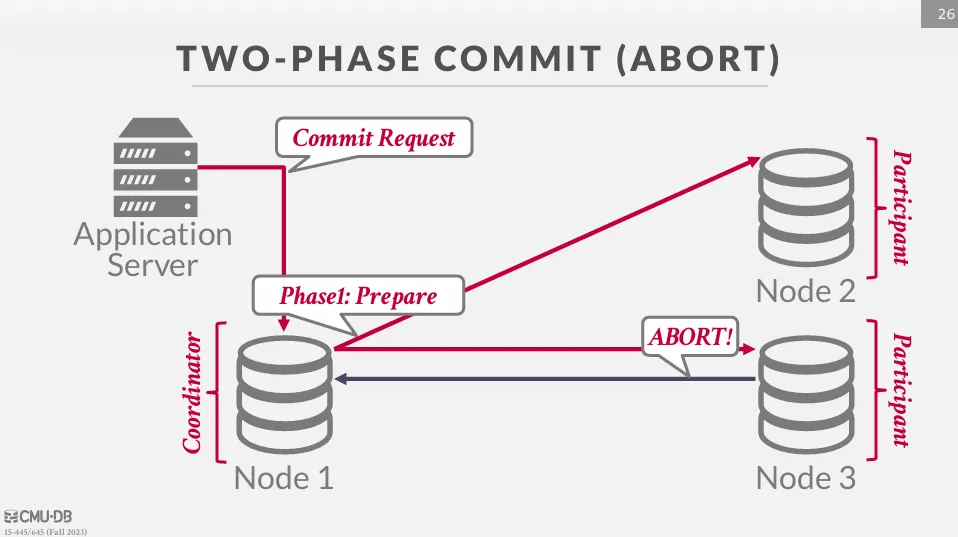
而此時協調者應該向應用程式回覆提交失敗,同時向所有參與者發送中止消息,並且確保所有交易都有回滾。
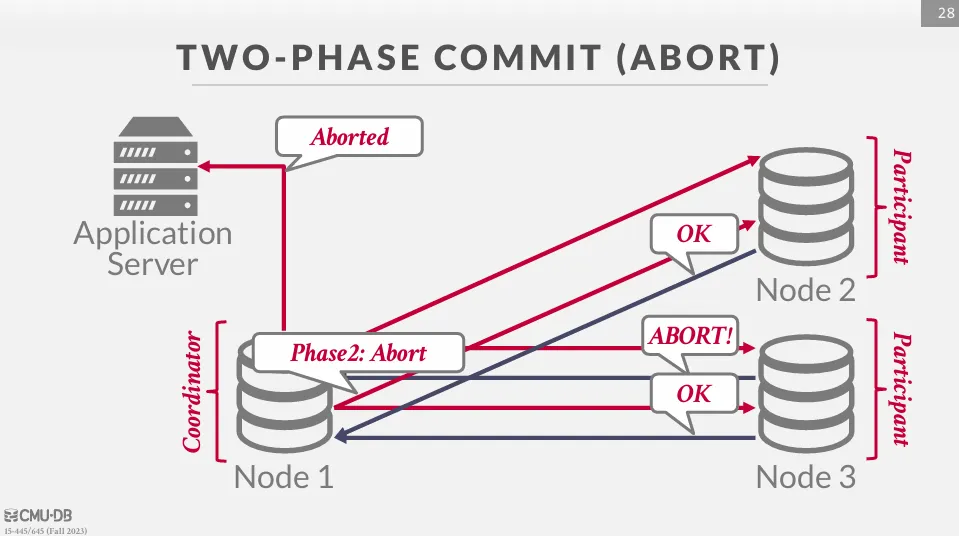
2PC Optimization
- Early Prepare Voting (Rare): 如果發送查詢到已知將是交易中最後一個執行的遠端節點,該節點會連同查詢結果一起返回其準備階段的投票。
- Early Acknowledgement after Prepare (Common): 如果所有節點都在準備階段同意提交交易,協調者可以在提交階段完成前向客戶端發送成功確認
2PC Fault Tolerance
在 Two-Phase Commit 中,每個節點必須將自身在各階段的輸入與輸出記錄到日誌,以便在故障後進行恢復。恢復過程中可能出現的情況如下:
從協調者來看 :
- 故障在準備階段結束前 : 由於沒有任何節點收到 commit 指令,因此可以直接 abort
- 故障在提交階段結束前 : 由於有些節點可能已經收到 commit 指令,因此需要重新發送 commit 指令並等待所有節點回覆
從參與者來看 :
- 故障在準備階段投票前 : 由於沒有回傳任何訊息,因此可以直接 abort,同時協調者也會因為沒有收到回覆而 abort
- 故障在準備階段投票後等待最終決定前 : 聯繫協調者以獲取最終決定,如果協調者也故障,則等待協調者恢復
- 故障在收到最終決定後 : 聯繫協調者以獲取最終決定,同時協調者也會因為沒有收到回覆而不斷重發最終決定
由於 2PC 需要等待所有參與節點回覆,任何節點或協調者故障都可能導致 阻塞 (blocking),甚至出現 livelock。 這是 2PC 的主要缺陷,因此在需要更高容錯性與非阻塞特性的系統中,通常會改採用共識協議 (如 Paxos 或 Raft)。
Paxos
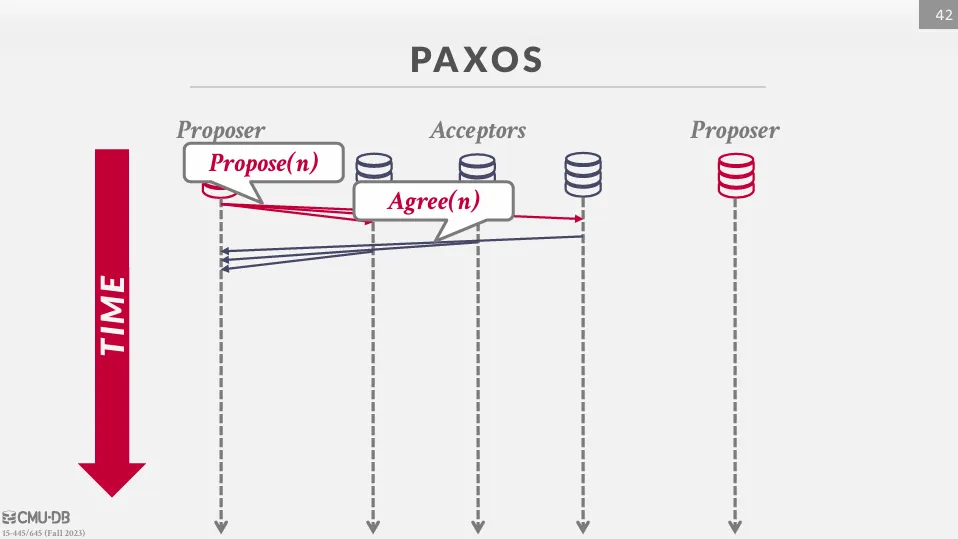
Paxos 是一種共識算法,在這個算法中,提議者會負責提交 commit 或 abort 的指令,而接受者則投票決定是否接受提議,由於不需要每個節點都同意,因此效能上會比 2PC 好。
Paxos 的協調者被稱為提議者 (Proposer),參與者被稱為接受者 (Acceptor)。
首先,應用程式會向 proposer 發送提交請求,然後 proposer 會向 acceptor 發送提議。
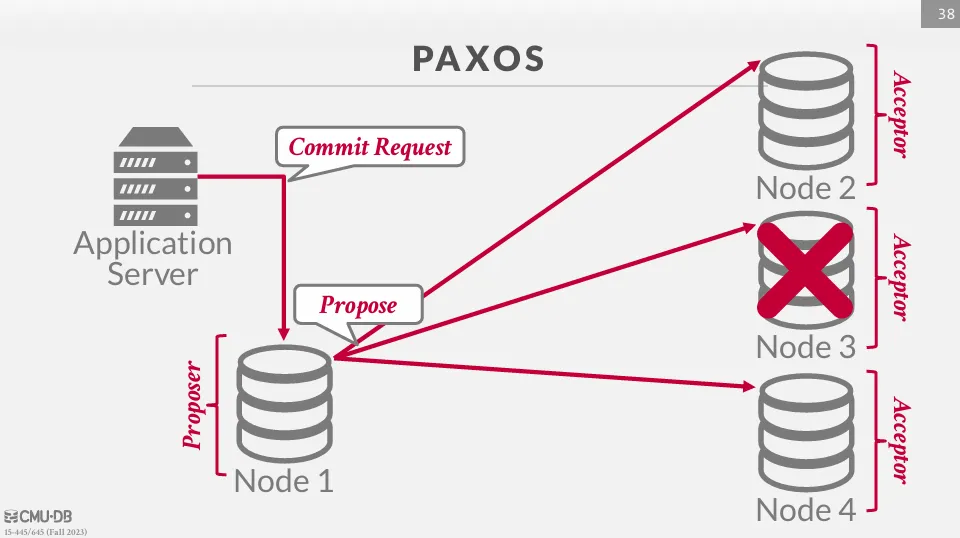
與 2PC 不同的是,Paxos 不需要等待所有節點的回覆,只需要等待過半數的節點同意即可,因此會繼續向 acceptor 發送 commit 請求。
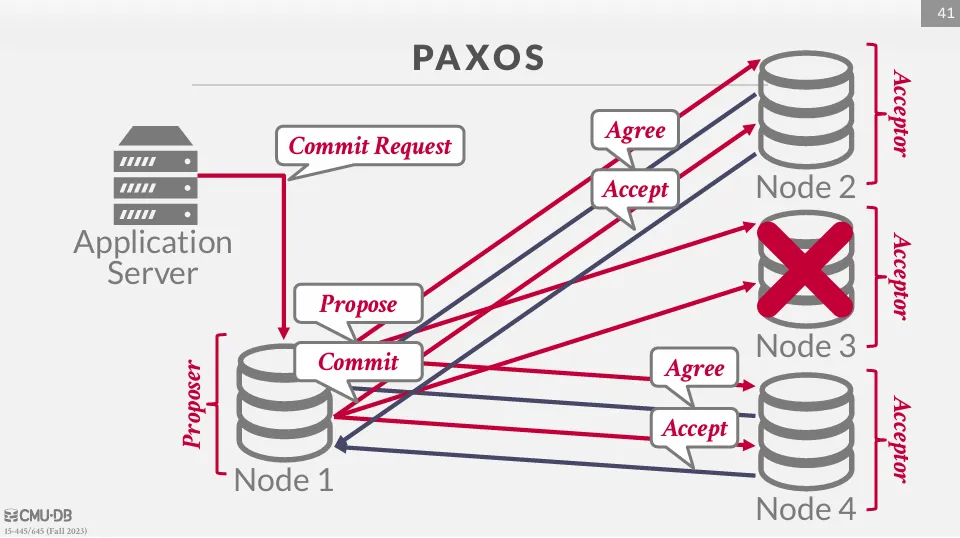
但不同的是,即使在 commit 階段,acceptor 也可以拒絕提議,舉例如下 :
假設有兩個 proposer,proposer 1 在 n 的時間提出協議並被所有人 agree。
這時候 proposer 2 在 n+1 的時間提出協議,接著 proposer 1 發出 commit 請求,由於時間先後順序,acceptor 會拒絕 proposer 1 的提議,之後 proposer 2 會繼續直到提交完成。
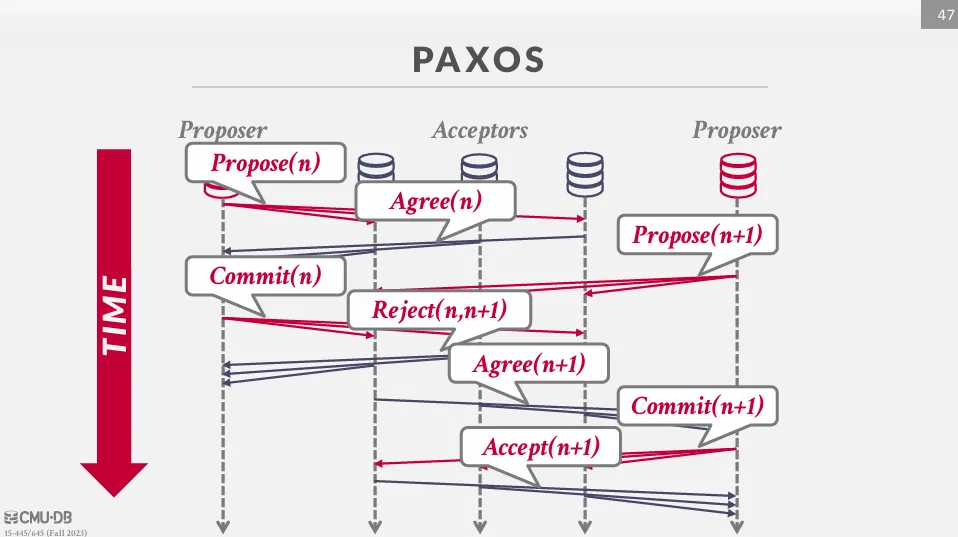
這樣會導致的問題是有可能同時兩個 proposer 互相組塞,因此我們可以透過 Multi-Paxos 來解決這個問題。
Multi-Paxos
如果系統內常有任意數量的 proposer,達成共識就會有點困難,因此我們可以先透過 Paxos 選出一個主要的提議者,然後由主要提議者來進行提議,並在達到一定時間之後再重新選舉主要提議者。 這樣在一段時間內提交交易就不需要 propose 而是直接進行 commit,這樣就能提高效率。
Consistency Issues (CAP / PACELC)
CAP
CAP 定理指出一個分散式系統無法同時滿足以下三個條件 :
- 一致性 (Consistency) : 對所有節點上的操作來說,一旦寫入完成,所有後續的讀取應該返回該寫入的值或更晚的寫入值
- 可用性 (Availability) : 可用性指的是所有仍在運行的節點都能滿足所有請求的能力。即使部分節點故障,仍然能夠提供服務
- 分區容錯性 (Partition Tolerance) : 分區容錯性意味著即使系統中部分節點間的消息丟失,系統仍能正確運行
PACELC
CAP 定理的現代版本是 PACELC 定理,這個定理進一步考慮了一致性和延遲之間的取捨。
- P (Partition):當在網絡分區時,系統必須在可用性 (A) 和一致性 (C) 之間做出選擇。
- E (Else):即使在系統運行正常且無網絡分區的情況下,也必須在延遲 (L) 和一致性 (C) 之間做出選擇。
CAP vs PACELC
在 RDBMS 中,通常會在重要節點故障時拒絕寫入,以確保一致性,而在 NoSQL 中,通常會接受寫入,常採用的策略是最後一次寫入勝出。