Database Recovery
本篇主要延續上一節的內容,討論故障發生後,要如何恢復資料庫的狀態。
ARIES
ARIES (Algorithms for Recovery and Isolation Exploiting Semantics) 是 IBM 在 1990 年代初期為 DB2 系統開發的一種恢復演算法,儘管不是每個 DBMS 都嚴格依照 ARIES 的規範實現,但 ARIES 的基本思想和許多技術細節仍然被廣泛使用。
ARIES 有三個關鍵概念 :
- WAL : 在資料庫實際寫入變更之前,先將所有變更記錄到穩定的存儲中,必須使用 steal / no-force
- Repeating History During Redo : 在系統重新啟動時,重演崩潰前的所有操作,將資料庫恢復到崩潰前的確切狀態
- Logging Changes During Undo : 在進行 undo 操作時,將這些撤銷操作記錄到日誌中。如果在 undo 期間發生再次崩潰,系統可以確保這些撤銷操作不會被重複執行
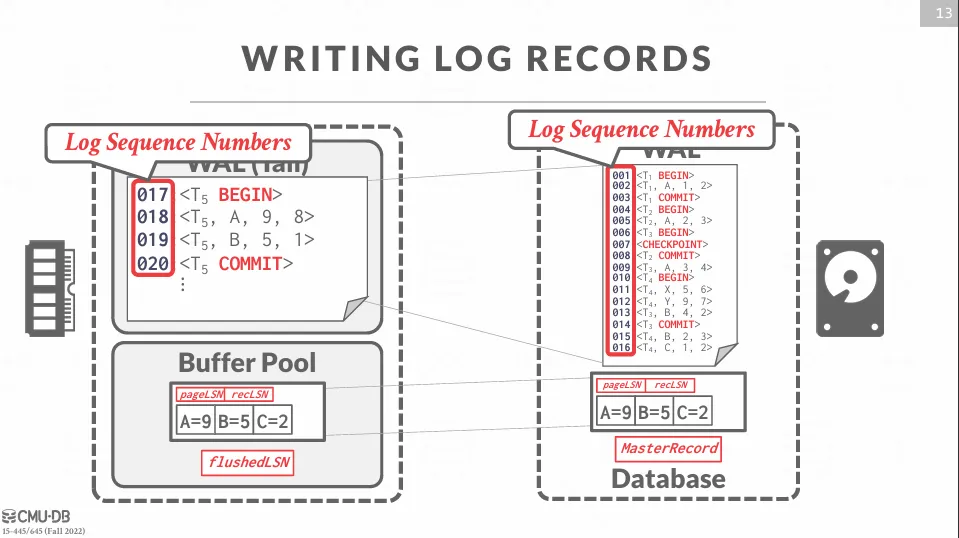
Log Sequence Numbers
WAL 中的每條紀錄都需要包含一個唯一的序列號,稱為 LSN (Log Sequence Number),各個元件都需要紀錄屬於他們的 LSN。
- LSN : 全局唯一的序列號,用來標識每個日誌記錄,每次日誌寫入時,LSN 會遞增
- flushedLSN : 表示已經寫入到硬碟的最後一條日誌的 LSN
- pageLSN : 表示該頁面上最後一次修改的日誌的 LSN
- recLSN : 自頁面上次被寫入硬碟後,最早的一次更新操作的 LSN
- lastLSN : 某個交易最後一次寫入日誌的 LSN
- MasterRecord : 最近一次 checkpoint 的 LSN

在頁面寫入硬碟前,DBMS 會確保該頁面的 pageLSN 小於等於 flushedLSN,這樣可以保證日誌記錄已經安全地記錄在硬碟上。
Normal Execution
大部分的交易都會包括一系列的讀寫操作,然後 commit 或是 abort。
這裡我們先來討論假如沒有發生故障,交易是如何執行的,我們會有四個假設來簡化討論 :
- 所有的 log file 都能放進一個 page 中
- 寫入硬碟是原子性的
- 使用 SS2PL 且不使用 MVCC
- 使用 WAL,且是 steal / no-force 策略
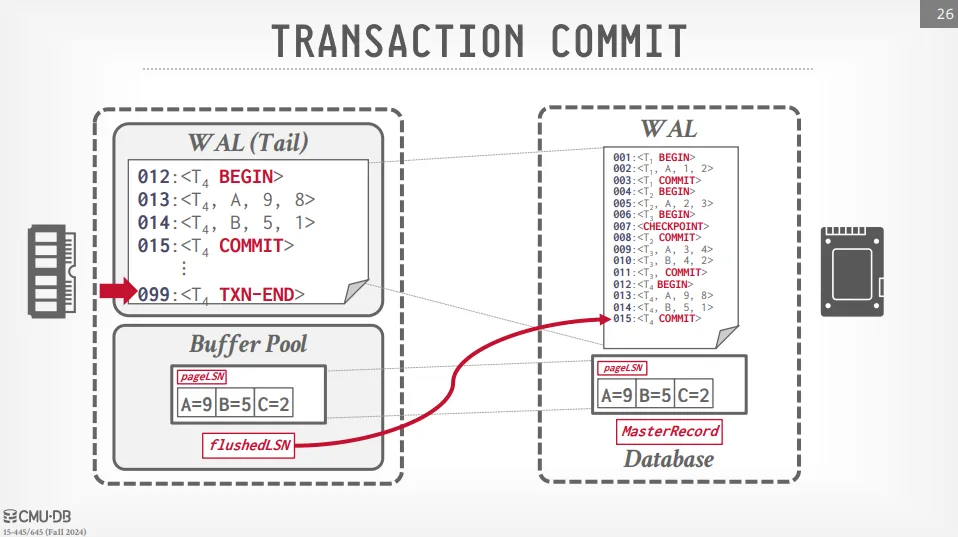
Transaction Commit
執行 commit 的順序如下 :
- 將 COMMIT 寫入 WAL buffer
- 將 WAL buffer 寫入硬碟
- 修改 flushedLSN 為 COMMIT 的 LSN
- 寫入一個 TXN-END 告訴系統該交易已經結束 (包括釋放鎖跟清除 ATT),這個操作不需要立即寫入硬碟
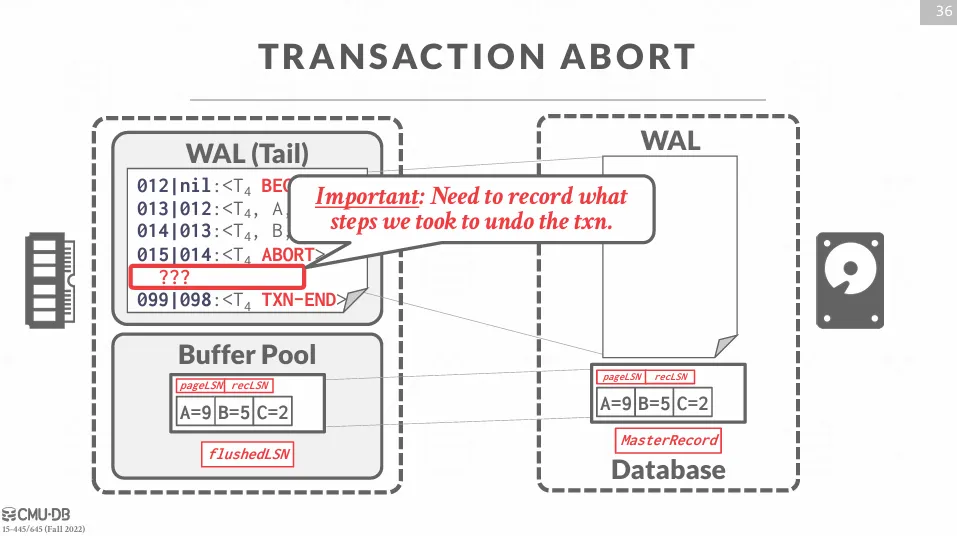
Transaction Abort
要處理 abort 的情況,我們就必須找到與該交易有關的所有日誌記錄以及執行順序,為了提高效率,同一個交易中的每個 log 都會紀錄上一個 log 的 LSN,即 prevLSN。
執行 abort 的順序如下 :
- 將 ABORT 寫入 WAL buffer
- 按照格式為
LSN | prevLSN的 linked list,倒序回滾所有的 log - 為了防止回滾再次故障,需要將回滾的 log 寫入 WAL
- 回滾完之後,寫入 TXN-END 紀錄
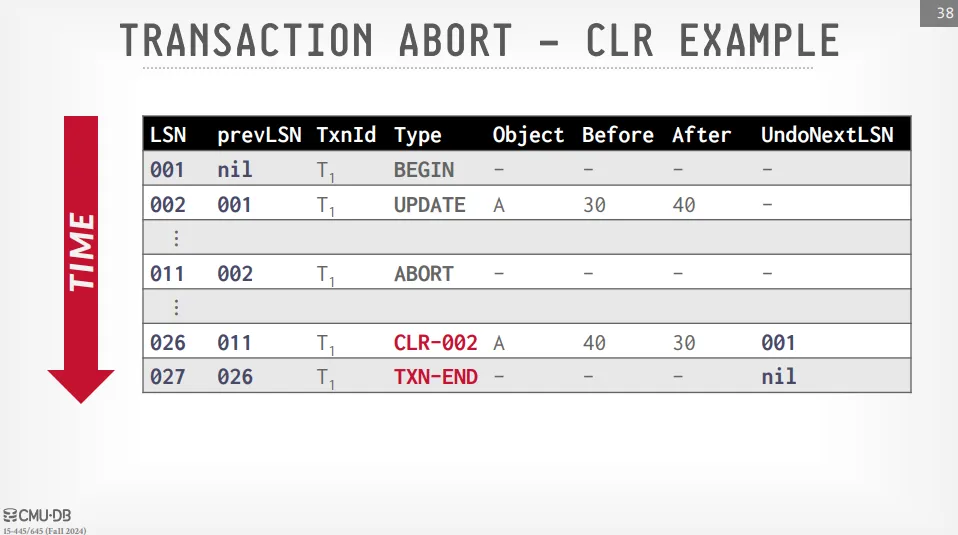
Compensation Log Record
Compensation Log Record (CLR) 是一種描述撤銷前一次更新操作的日誌記錄。 它包含更新日誌記錄的所有字段,並額外包含一個 UndoNextLSN 指標,指向下一個需要撤銷的 LSN。
需要注意的是,CLR 不需要被 undo,因為它們本質上是對先前操作的補償。
Checkpoint
在 DBMS 中,checkpoint 可以用於減少系統崩潰後需要回放的日誌量,以加速恢復過程。
Non-Fuzzy Checkpoint
在 non-fuzzy checkpoint 中,DBMS 會暫停所有交易的執行,以確保能夠將一致性快照寫入硬碟中,具體步驟如下 :
- 暫停新的交易啟動
- 等待所有活躍交易執行完畢
- 將所有 dirty page 寫入硬碟
這種方式可以保證資料的一致性,但是會導致系統暫停,顯然不是個好方法。
Slightly Better Checkpoints
Non-fuzzy checkpoint 的問題在於暫停所有交易並且等待所有活躍交易執行完畢,而在 slightly better checkpoint 中,我們只暫停需要 write latch 的交易,不需要等待所有活躍交易執行完畢。
這種做法的流程如下 :
- 暫停新的和需要修改的交易
- 紀錄內部狀態 (ATT、DPT)
- 將所有 dirty page 寫入硬碟
- 寫入一個
CHECKPOINT並帶上 ATT 和 DPT 的內容
在這個過程中,我們需要以下兩個資訊 :
- Active Transaction Table (ATT) : 追蹤當前正在運行的交易,包括 txn_id、status (Running、Committing、Candidate for Undo)、lastLSN,只要沒有
TXN-END就會在 ATT 中 - Dirty Page Table (DPT) : 記錄 buffer pool 中已被修改但尚未寫入硬碟的頁面,包括 recLSN

這種方法比第一個方法更好,但是仍然需要暫停寫的交易。
Fuzzy Checkpoint
Fuzzy checkpoint 放棄了把所有東西都寫入硬碟的想法,允許在 checkpoint 過程中交易繼續執行。
這種做法的流程如下 :
- 寫入一個
CHECKPOINT-BEGIN記錄 - 並拍攝 ATT 和 DPT 的快照
- 後台線程將所有在 DPT 中的 dirty page 寫入硬碟
- 全部完成後,寫入一個
CHECKPOINT-END記錄,並記錄一開始的 ATT 和 DPT - 並更新 MasterRecord 指向
CHECKPOINT-BEGIN

ARIES Recovery
ARIES 恢復協議是一種在故障後恢復數據的常見方法,總共分為三個階段 :
- Analysis Phase
- Redo Phase
- Undo Phase

Analysis Phase
Analysis Phase 的目標是搞清楚故障時的系統狀態,並重建 ATT 和 DPT。
DBMS 會從 MasterRecord 找到指向最後一個 CHECKPOINT-BEGIN 的 LSN,並從該 LSN 開始掃描日誌,直到日誌的末尾。
在掃描日誌時,DBMS 會執行以下操作 :
- 如果發現
TXN-END,則在 ATT 中移除該交易 - 遇到其他交易時,將其加入 ATT 並設為 UNDO
- 如果發現提交紀錄,則在 ATT 中把該交易設為 COMMIT
- 如果發現是更新紀錄且不在 DPT 中,則將其加入 DPT 並設 recLSN 為該紀錄的 LSN

在經過這個階段後,ATT 中剩下的就是故障當時未完成的交易,DPT 中的頁面則是需要在 redo 階段重新應用的頁面。
這邊我有一個地方沒搞懂是為甚麼要在 030 的時候把 P20 加到 DPT 中,猜測可能只是為了保險?
Redo Phase
Redo phase 的目標是重建資料庫故障時的狀態,從 DPT 中最小的 recLSN 對應的日誌記錄開始掃描。
對於每一條日誌或是 CLR,DBMS 都會重新應用更新,除非以下情況之一成立 :
- 受影響的頁面不在 DPT 中
- 受影響的頁面在 DPT 中,但該記錄的 LSN 小於該頁面在 DPT 中的 recLSN
- 受影響頁面的 pageLSN (在硬碟上) 大於等於 LSN
Redo 時,需要重新執行 log 中的操作,將 pageLSN 更新為 LSN,並且不再新增 CLR。 在結束時,DBMS 會將所有狀態為 COMMIT 的交易寫入 TXN-END 日誌記錄,並把它們從 ATT 中移除。
Undo Phase
Undo phase 的目標是回滾所有未完成的交易,使資料庫恢復到一致的狀態。
在這個階段的執行方法如下 :
- 從 ATT 中選擇狀態為 UNDO 的交易
- 從中選擇 lastLSN 最大的交易,並從該交易開始逆序處理所有的 log 並產生 CLR
- 如果該交易的 UndoNextLSN 為 null,則寫入 TXN-END 並將其從 ATT 中移除
- 持續逆序處理 log,直到 ATT 中沒有 UNDO 狀態的交易為止
了解了以上三個步驟後,可以在搭配講義的範例來理解整個過程。 PPT Link
Additional Topics
Q1 : 如果系統在 recovery 的 analysis 階段崩潰要怎麼辦 ?
重新執行 recovery 即可
Q2 : 如果系統在 recovery 的 redo 階段崩潰要怎麼辦 ?
重新執行 recovery 即可
Q3 : 如何在 redo 階段時提升效能 ?
假設系統不會再次崩潰,則可以用異步的方式將所有變更寫入硬碟
Q4 : 如何在 undo 階段時提升效能 ?
使用 Lazy Undo,只有在新的交易需要讀取被回滾的頁面時才進行回滾,以及避免使用 long-running 的交易