Database Logging
資料庫在運行時可能會發生各種故障,如果中斷了事務的運作,就可能產生資料不一致的問題,這時候就需要故障恢復機制來保證資料的完整,主要會分成兩個部分來討論 :
- 在正常操作時進行一些準備工作,以確保系統能夠從故障中恢復 (本節)
- 故障發生後,用來恢復資料庫狀態的操作,以確保交易的原子性、一致性與持久性 (下一節)
Failure Classification
世界上並不存在完全可靠的系統,因此我們需要考慮各種可能的故障情況。
Transaction Failures
這種類型的故障發生在交易過程中,由於某些錯誤導致交易被中止 :
- Logical Errors : 交易中的某些操作導致了錯誤,例如餘額不足
- Internal State Errors : 交易中的某些操作導致了系統錯誤,例如 deadlock
System Failures
這種故障發生在承載 DBMS 的底層軟硬體出現非預期的問題時 :
- Software Failure : DBMS 軟體的實現出現問題,如除以零
- Hardware Failure : DBMS 所在的硬體出現錯誤,如斷電
Storage Media Failure
這種故障發生在物理存儲設備受到損壞並且無法修復時,通常無法修復,只能從備用的硬碟恢復。
Buffer Pool Management Policies
在我們修改資料時,DBMS 需要先把資料讀到記憶體中,然後根據請求進行修改,最後再將修改後的資料寫回硬碟。 在這個過程中,DBMS 需要保證以下兩點 :
- 一旦提交後,交易的修改就應該是永久的
- 如果中止,交易的修改不應該被持久化
如果真的遇到了故障,DBMS 可以使用 redo 和 undo 來恢復資料庫的狀態,redo 是將已提交的交易重新應用到資料庫中,而 undo 則是回滾未提交的交易。
DBMS 如何處理 undo / redo 主要取決於 buffer pool management policies,有兩種策略 :
- Steal Policy : DBMS 是否允許將未提交的更改寫入硬碟
- Force Policy : DBMS 是否要求將提交的更改寫入硬碟,或是只需要確保 log 被寫入硬碟
在實務上,我們通常會選擇 steal / no-force 來進行管理,no-steal / force 的問題在於這樣能處理的交易大小受到 buffer pool 大小的限制。
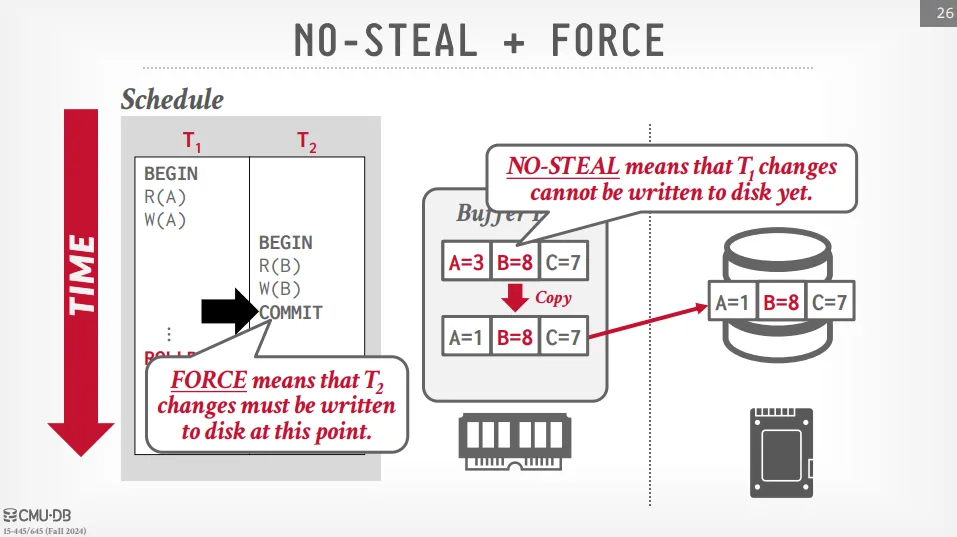
Steal Policy
如果選擇 steal,若 T1 rollback,則需要把已經進行持久化的資料重新修改回原本的狀態再存回硬碟,這種方法在不發生故障的情況下可以提高效率。
如果選擇 no-steal,若 T1 rollback,DBMS 不需要進行任何操作,這種方法在發生故障時效率較高。
Force Policy
如果選擇 force,當交易提交時,DBMS 需要立即將修改寫回硬碟,一致性較高。
如果選擇 no-force,當交易提交時,DBMS 可以選擇延遲將資料批量寫回硬碟,效率較高。
Shadow Paging
在 buffer pool 的策略上,最容易實作的就是 no-steal / force 的組合,在交易被中止時不需要 undo 資料,提交後也不需要 redo 資料,唯一的問題是無法處理超過 buffer pool 大小的資料。
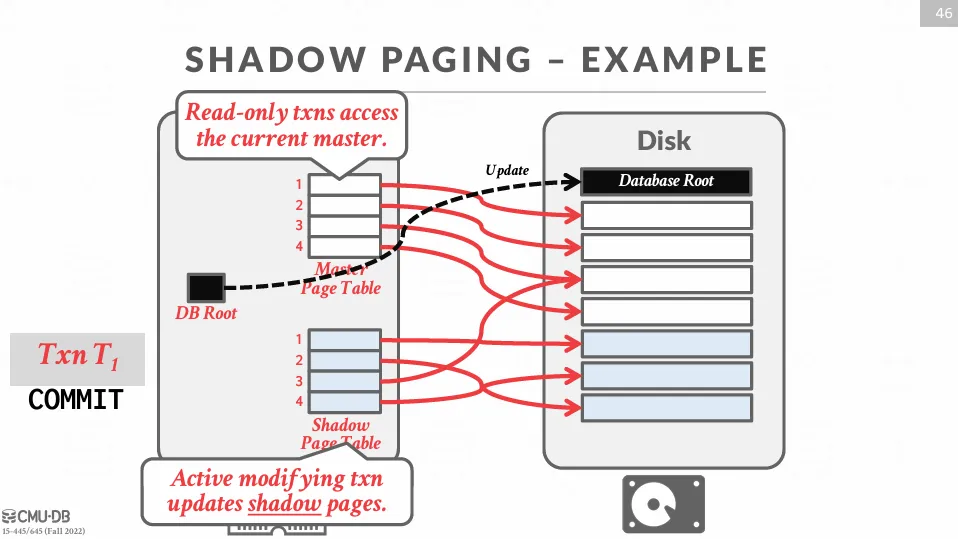
而 shadow paging 就是一種使用 no-steal / force 的代表,它會維護兩份獨立的資料版本 :
- Master : 包含了所有已提交的交易變更,是目前被所有讀取操作使用的資料庫版本
- Shadow : 包含了未提交的交易變更的臨時資料庫版本,所有的更新操作都會在這個陰影版本中進行
下圖中,左邊是記憶體中的位置,右邊是硬碟中的位置。
當寫入的交易發生時,DBMS 會生成一份 shadow page,並在 shadow page 上進行修改,並將 DB root 的指針指向 shadow page,同時將資料都存在硬碟上。
在 commit 之後,DBMS 會刪除舊的 master page。
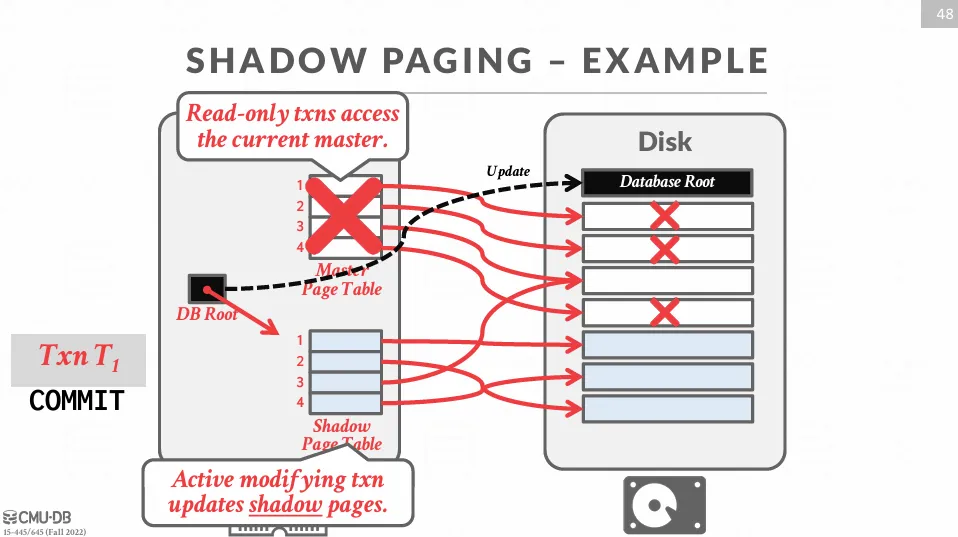
在 shadow paging 的實現中,不管是 undo 還是 redo 都非常簡單,undo 只需要刪除 shadow page,而因為每次都會將資料寫入硬碟,redo 也不需要進行任何操作。
但 shadow paging 的缺點也很明顯 :
- 每次提交需要將頁表、根頁面和所有更新的頁面同步到硬碟中,導致大量的隨機寫入
- 由於要提交的資料可能被分割到不同的頁面中,導致資料碎片化
- 隨著資料的更新,舊的頁面將會失效,所以需要 gc
- 通常來說只支持單一寫入,或者需要將多個交易以批次形式提交,這限制了併發性
在 2010 年以前的 SQLite 也曾採用過類似的 shadow paging 的方法。 如果要修改某個 page,它會先將原始的 page 保存到一個 journal file 中,然後直接修改原始的 page。 如果提交成功,則刪除 journal file,如果中途發生故障,則根據 journal file 將 page 恢復到原始狀態。
Write-Ahead Logging (WAL)
對於 shadow paging 來說,最大的問題就是需要將許多不連續的頁面寫入硬碟,而 WAL 就是一種能夠解決這個問題的方法。
WAL 的核心概念是在資料庫進行變更之前,先將變更寫入一個 log file 並寫入硬碟,然後再修改真正的數據頁面。 這樣可以保證即使發生故障,也可以根據 log file 來進行恢復,通常 WAL 採用的 buffer pool 策略通常是 steal / no-force。
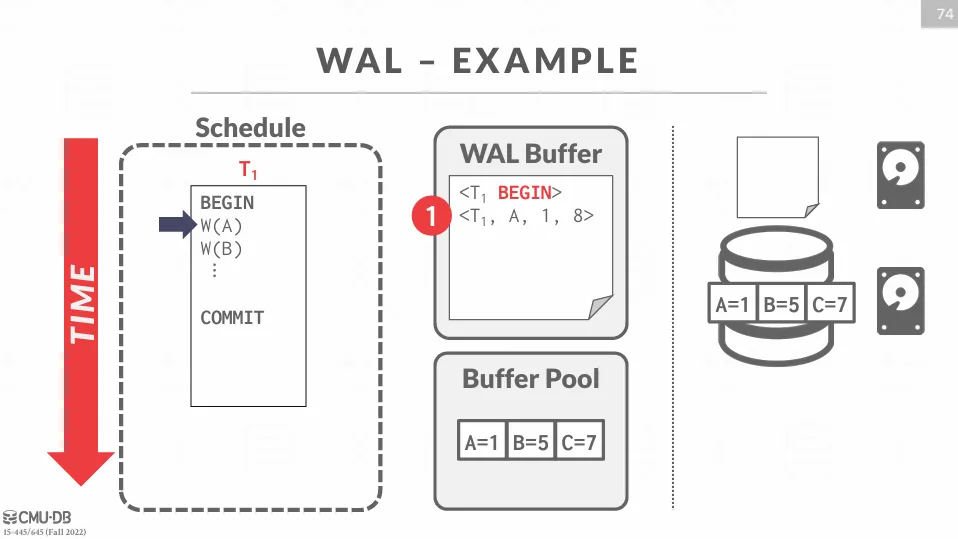
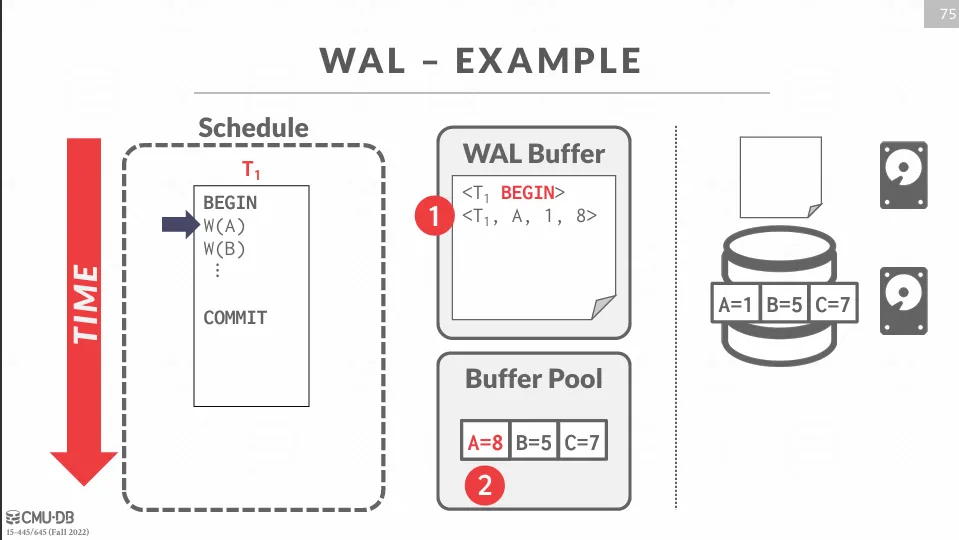
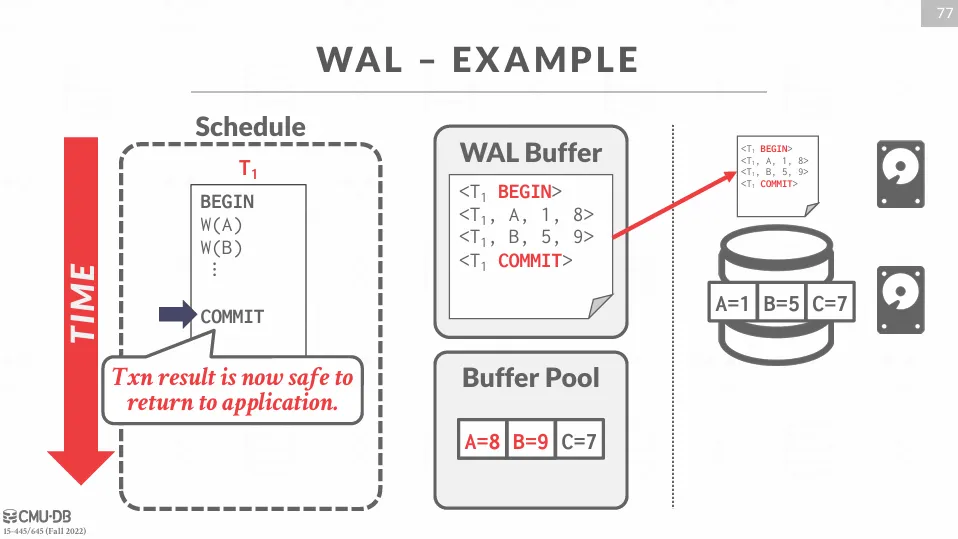
在交易開始時,DBMS 會在 log file 中寫入一條 BEGIN 記錄,結束時需要寫入一條 COMMIT 記錄。
在執行過程中會記錄完整的資訊,包含了 transaction_id、object_id、舊值、新值等。
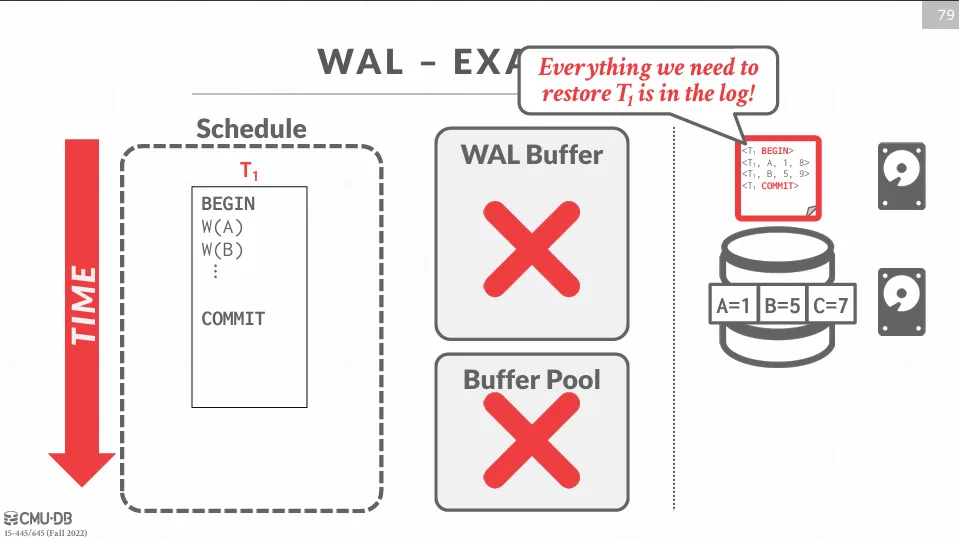
如下面的範例所示,我們會先寫入 WAL buffer 中,接著修改 buffer pool 中的資料,再將 WAL buffer flush 到硬碟中,最後假如斷電了,則可以根據 log file 來進行恢復。
WAL Group Commit
每次都將 log flush 到硬碟可能會成為效能瓶頸,因此我們可以透過 group commit 來提高效能,只在達到一定數量或者一定時間後才進行 flush。
Capture Data Changes (CDC)
WAL 是一份包含了資料庫所有變更歷史的 log file,因此我們可以利用這份 log file 來實時傳送變動給其他系統,這種技術稱為 Capture Data Changes (CDC)。
CDC 可以用於資料同步、ETL 等場景,通過捕捉資料庫的變更事件,將其轉換為適合的格式,並發送到其他系統中,常見的有 Debezium 等等。
Logging Schemes
Log 紀錄的內容可能依據不同的策略而有所不同,主要有以下幾種 :
- Physical Logging
- Logical Logging
- Physiological Logging
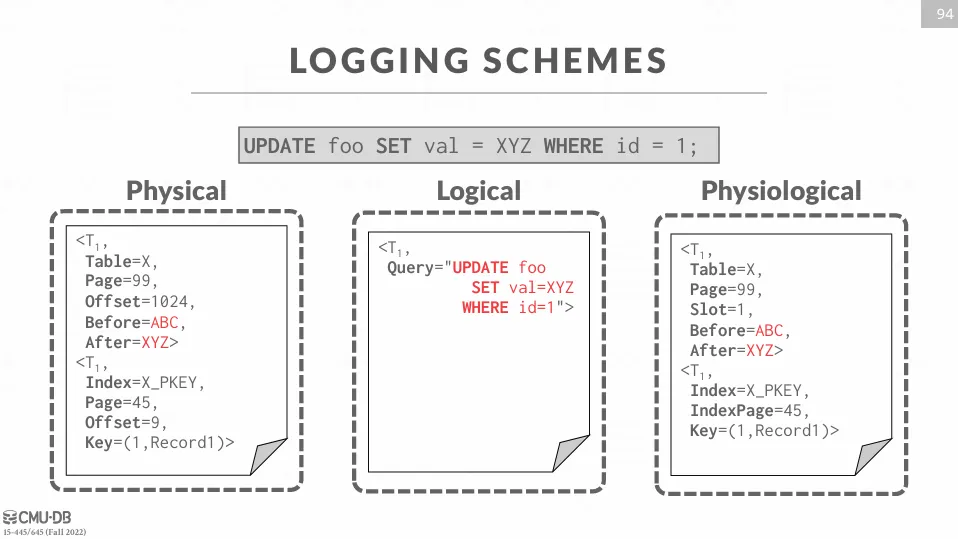
Physical Logging
物理日誌記錄是對資料庫中特定位置的位元級別變更進行記錄。每條日誌會包含 page_id、offset、before-image、after-image。
類似於 git diff 的方式。
Logical Logging
邏輯日誌記錄記錄的是交易執行的高階操作,而不是具體的位元變更。 例如,它會記錄 UPDATE、DELETE 或 INSERT 操作的語句。
Physiological Logging
物理邏輯混合日誌記錄是一種混合方法,將物理和邏輯日誌記錄結合在一起。
具體來說,它針對單個頁面進行日誌記錄,但不具體記錄頁面中數據的組織方式。 這種方法會基於頁面的 slot number 來識別資料列,但不指定變更在頁面中的確切位置 (offset)。
這種方法也是當下最流行的方法。
Checkpoint
在使用 WAL 時,log 會隨著時間不斷增長,導致在故障恢復時需要回放大量的 log,從而增加恢復時間。 為了避免這種情況,DBMS 會定期進行 checkpoint 操作,將當前的髒頁寫入硬碟,並在 log file 中加上一個 checkpoint 記錄,表示在這個點之前的 log 都已經永久的應用到資料庫中。
以下圖為例,在 checkpoint 之前 commit 完成的交易 T1 已經經被應用到資料庫中了,因此不需要做任何操作。 而在 checkpoint 之後 commit 的交易 T2 則需要進行 redo,未 commit 的交易 T3 則需要進行 undo。

Checkpoint 最需要考慮的問題是多久執行一次。 如果過於頻繁,會導致效能下降,但如果太久才做一次,則會導致恢復時間過長。
以 PostgreSQL 為例,它會在以下情況下觸發 checkpoint :
checkpoint_timeout: 當距離上次 checkpoint 已經過了一定時間 (預設 5 分鐘)max_wal_size: 當 log file 的大小超過了一定的限制 (預設 1GB)- 手動執行 SQL
CHECKPOINT指令
Blocking Checkpoint
Blocking checkpoint 是一種最簡單的 checkpoint 實作方法,步驟如下 :
- 暫停新交易 : 暫停接受新的交易,並等待所有當前活躍的交易完成
- 刷新緩衝區 : 將當前記憶體中的所有日誌記錄和修改過的緩衝區寫到硬碟中
- 記錄 checkpoint : 寫入一個
<CHECKPOINT>記錄到日誌檔案中,並將其寫入硬碟
但一般來說,blocking checkpoint 會導致系統停頓,因此較少使用,我們會在下一節中討論其他更好的方法。