Query Planning & Optimization
由於 SQL 是一種宣告式的語言,所以 DBMS 不會具體知道自己應該要怎麼執行,而是需要將 SQL 語句轉換成可執行的 query plan。
但找到最佳的 query plan 是一個 NP-hard 的問題,因此本節的主要內容就是如何透過演算法在有限的時間內找到一個好的 query plan。
我們使用的策略主要有兩個 :
- Heuristic-based : 使用既定的規則來調整順序
- Cost-based : 依據統計資料來估算成本,選擇 cost 最低的 query plan
而 query plan 主要也有兩種類型 :
- Logical Plan : 查詢中的關係代數表達式
- Physical Plan : 具體的執行策略,如排序的方法、join 的方式等
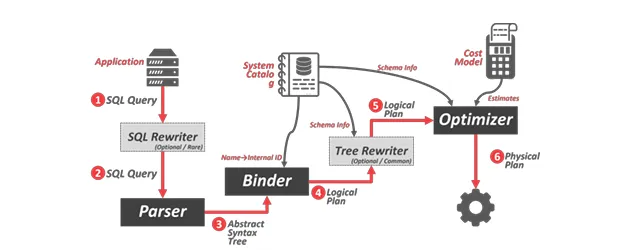
在這個 SQL 語句執行的流程圖中,binder 跟 tree rewriter 會負責將 SQL 語句轉換成 logical plan,而 optimizer 則會透過 system catalog 所提供的資訊來將 logical plan 轉換成 physical plan。
Logical Query Optimization
我們可以先透過一些簡單的規則將 logical plan 進行優化,這些規則通常是基於關係代數的等價轉換。
Selection Optimization
- 盡早執行篩選條件 : 透過篩選條件減少 tuple 數量,特別是在 join 之前
- 重新排序篩選條件 : 將選擇性最高的條件放在前面執行,使後面所需過濾的 tuple 數量更少
- 將複雜的篩選條件拆分 : 拆分篩選條件,如
X = Y AND Y = 3可以拆分成X = 3 AND Y = 3
Projection Optimization
- 刪除不必要的 column : 減少 I/O,舉例來說,如果 SQL 中只有
SELECT name FROM table,那麼我們就應該在一開始只留 name 欄位再做後續操作
Query Rewrite Optimization
- 移除不可能或不必要的篩選條件 : 如
WHERE 1 = 0 - 合併篩選條件 : 如
VAL BETWEEN 1 AND 10 OR VAL BETWEEN 5 AND 15可以合併成VAL BETWEEN 1 AND 15 - 消除子查詢 : 將子查詢攤平 (flatten) 或取消關聯 (de-correlate)
- 拆解和儲存結果至臨時表 : 如果有複雜的子查詢,可以將結果儲存至臨時表並逐一優化
Join Optimization
- Join Reordering : 重新排序 join 的順序,如將資料量較少的 table 當成 outer table
Cost Estimation
除了一些基本的 heuristic 外,有許多操作在 DBMS 中沒有一定的優劣,所以我們需要透過 cost estimation 來估算成本。
查詢成本通常取決於很多因素,如 CPU、硬碟 I/O、記憶體、網絡等。 以 PostgreSQL 來說,他會為每個操作指定一個固定的 CPU 成本 (如 seq_page_cost = 1.0, random_page_cost = 4.0),或是一個固定的 I/O 成本 (如 cpu_tuple_cost = 0.01, cpu_index_tuple_cost = 0.005)。
但大部分的成本依舊取決於在整個 query plan 中我們要讀寫多少 tuple,因此 DBMS 需要維護一些統計資料,如 tuple 數量或最大最小值來幫助估算成本。
Statistics
通常對於一個任意的 table R,DBMS 都會維護以下統計資料 :
- : R 中的 tuple 數量
- : R 中屬性 A 的不同值數量
透過這兩個資訊,我們可以得到 selection cardinality 。
除此之外,以 PostgreSQL 為例,它還會維護以下統計資料 :
- n_distinct : 每個欄位的唯一值數量
- most_common_vals : 每個欄位中最常出現的值
- histogram_bounds : 每個欄位的 histogram 範圍
- correlation : 每個欄位的值與物理儲存順序的相關性
Histograms
真實的資料中幾乎不可能是 uniform 的,因此我們可以使用 histogram 來更好的估算成本,histogram 會將屬性的值域 (range) 分成多個區間 (bucket),並記錄每個區間的 tuple 數量。
Sketches
我們可以使用 probabilistic data structures 來產生近似於 dataset 的資料,如 HyperLogLog、Count-Min Sketch 等等。
Sampling
DBMS 可以針對 table 的部分資料進行 sampling 來估算成本,並在 table 變動超過一定比例時重新進行 sampling,如 PostgreSQL 的 ANALYZE 指令。
Query Plan
在有了 cost estimation 後,optimizer 就可以開始在巨大的 search space 中尋找最佳的 query plan。
Single-Relation Query Plans
對於單表查詢來說,只需要使用簡單的啟發式規則即可,目標是找到最佳的 access method。
- sequential scan
- binary search (with clustered indexes)
- index scan
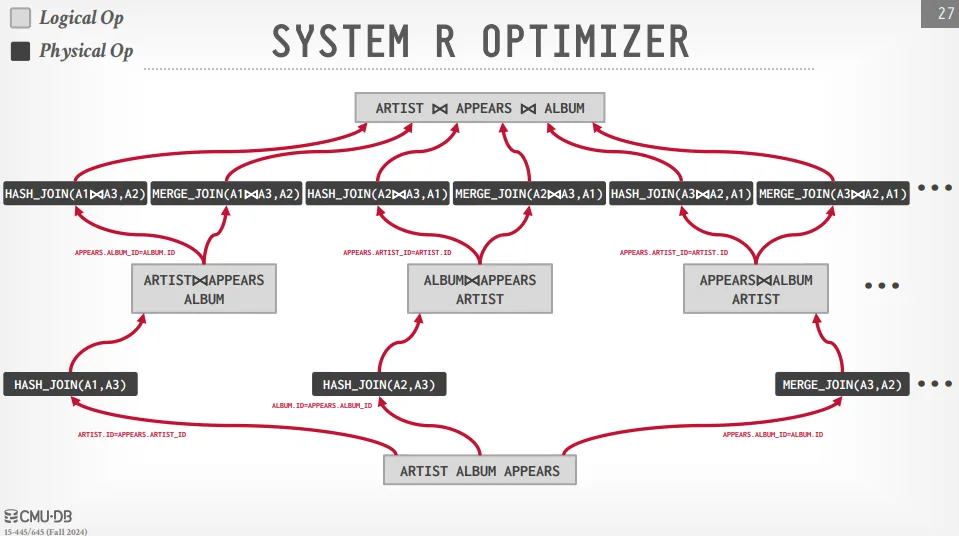
Multi-Relation Query Plans
隨著連結數量的增加,可以選擇的計劃數量會急劇增加,因此我們需要限制搜索空間以便在有限時間內找到最佳計劃,通常有 bottom-up 和 top-down 兩種方法。
Generative / Bottom-up
從單表開始逐步建立更大的計畫,就像是動態規劃 (Dynamic Programming) 一樣。
舉例來說,假設我們要找到三個 table A、B、C 的最佳 join order,步驟會大致如下 :
- 先針對單表找到最佳的 access method,如 sequential scan、index scan
- 兩兩一組,找出最佳的 join order,如 (A hash join B)、(B merge sort join C)、(A hash join C)
- 接著在從上一輪的結果中找出最佳的 join order,如 ((A hash join B) merge sort join C)、((B merge sort join C) hash join A)
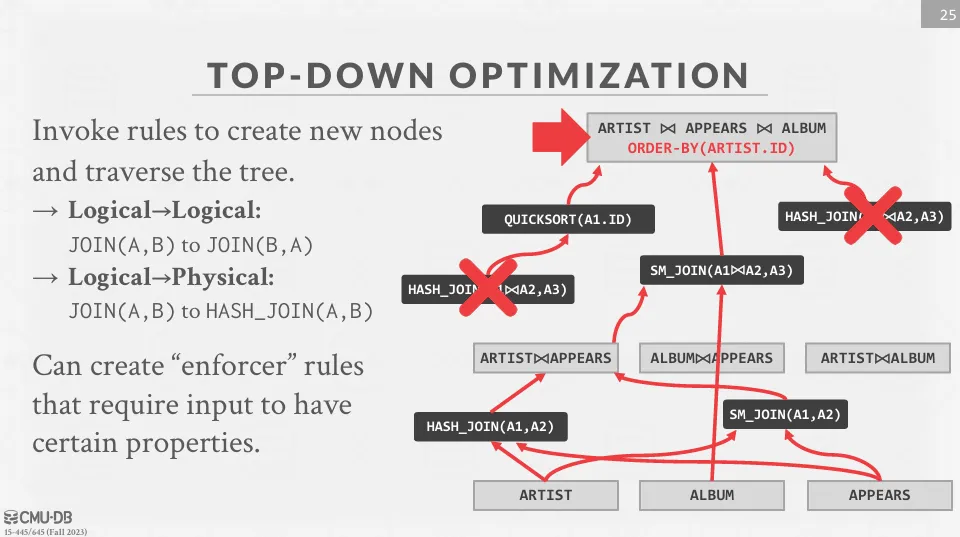
Transformation / Top-down
Optimizer 會從 logical plan 開始,使用 branch and bound 的方法來遍歷樹狀結構,並將 logical operator 轉換成 physical operator。