Query Execution
這篇筆記會介紹 DBMS 中 query execution 的相關概念,從處理模型到平行化的技術等等。
Query Execution
在 DBMS 中,如果我們要執行一段 SQL 查詢,通常會經過以下幾個步驟 :
- Parsing : 將 SQL 查詢轉換成 parse tree
- Binding : 將 parse tree 中的 table 和 column 名稱與資料庫中的實際名稱對應起來
- Optimization : 將 parse tree 轉換成 query plan
- Execution : 執行 query plan 並返回結果
其中,query plan 是一個由 operator 組成的 DAG (有向無環圖),例如 scan、join、aggregation 等等。 這些 operator 會按照一定的順序執行,最後 root operator 的輸出就是查詢的結果。
單純逐一執行每個 operator 會產生大量中間結果,導致效能下降,因此 DBMS 引入了 pipeline 的概念。 pipeline 是一段連續的運算元序列,資料可以在不經過中介儲存的情況下持續流動。
然而,並不是每個 operator 都可以 pipeline,有些 operator 就需要等所有資料都到齊才能繼續,這些就是 pipeline brokers,如 join、subquery、sort 等等。
Processing Models
Processing model 定義了 DBMS 中 operator 之間資料流動的方式,主要有以下三種 :
- Iterator Model
- Materialization Model
- Vectorized / Batch Model
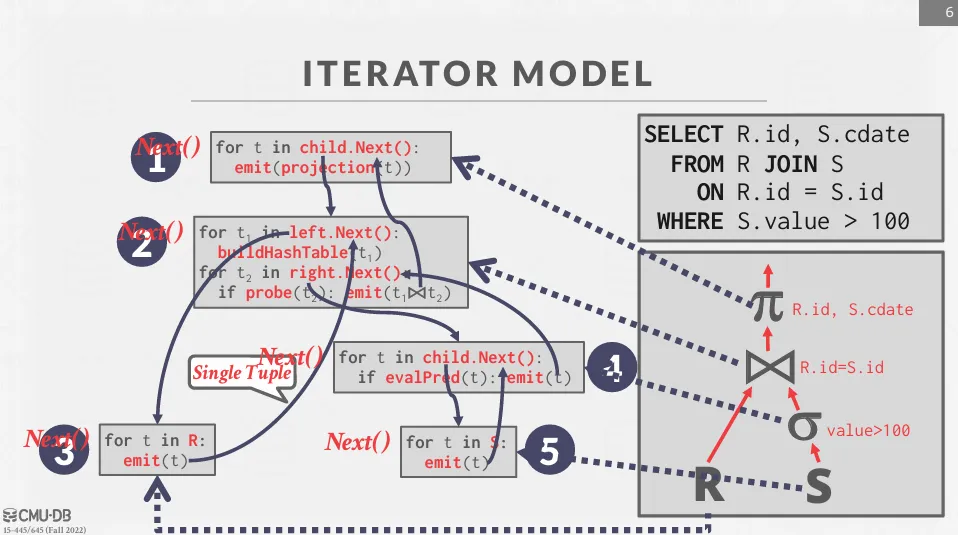
Iterator Model
Iterator 模型,也被稱為 volcano model 或 pipeline model。
這個模型的核心是讓每個 operator 都實現一個 Next() 函數,使查詢計畫中的每個節點在需要資料時,能夠向其子節點請求下一個 tuple (如果資料已經回傳完畢則返回 null)。
這個模型的優點在於實現了 pipelining,可以減少中間結果的儲存,並且可以很好的結合 LIMIT 操作,缺點就是對 OLAP 系統就不太友好。
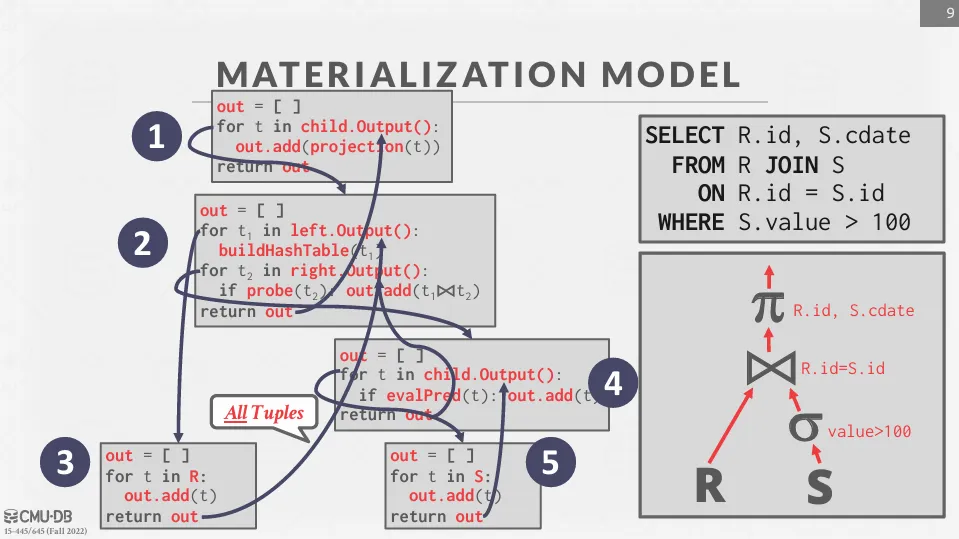
Materialization Model
每個 operator 都有一個 Output() 函數,會一次性處理完所有子節點的資料並全部返回。
這種方法更適合 OLTP 系統,因為 OLTP 通常只須回傳少量資料,可以減少調用 Next 函數的次數。
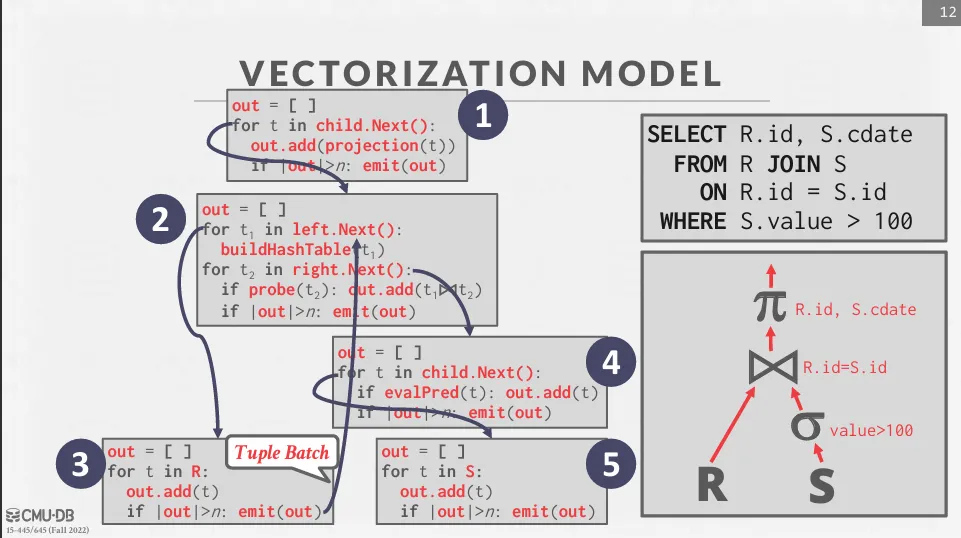
Vectorized / Batch Model
Vectorized / Batch Model 是一種 iterator 和 materialization 的混合模型,在調用 Next() 函數時,會一次性回傳一批 tuple,可以根據硬體條件來調整 batch 的大小。
這種方式適合於 OLAP 系統,可以減少調用 Next() 函數的次數,並且可以使用 SIMD 指令集來批量處理 tuple。
Plan Processing Direction
除了回傳資料的方式外,DBMS 還可以選擇資料流動的方向,主要有以下兩種 :
- Top-to-Bottom (Pull-based) : 由 root operator 開始向下請求資料,是更常見的做法
- Bottom-to-Top (Push-based) : 由 leaf operator 開始向上推送資料
Access Methods
Aaccess method 是指 DBMS 從 table 中獲得資料的方式,主要有以下幾種 :
- Sequential Scan
- Index Scan
- Multi-Index Scan
Sequential Scan
Sequential scan 指的是 DBMS 逐行讀取 table 中的所有資料,通常效能會較差。
有許多的優化方法可以提升 sequential scan 的效能,有一些在之前的章節中已經提過了,如 :
- Prefetching
- Buffer Pool Bypass
- Late Materialization
- Heap Clustering
- Parallelization (本節)
- Data Skipping (本節)
Data Skipping
有兩種方法可以實現 data skipping :
- Approximate Queries (有損的) : 使用部分子集來近似整個資料集的結果,如想要計算平均值,可以只使用部分資料來計算
- Zone Maps (無損的) : 在每個 page 上維護一個 metadata (如平均值、最大最小值),可以快速判斷是否包含需要的資料或是是否需要訪問這個 page
Index Scan
DBMS 會選擇一個索引來幫助查詢,目標是找到可以過濾掉最多資料的索引,這樣可以減少需要讀取的 tuple 數量。
舉例來說,假設有一個 table employees,包含以下欄位 :
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
department VARCHAR(100)
);
CREATE INDEX idx_age ON employees(age);
CREATE INDEX idx_department ON employees(department);
我們要查詢以下的 SQL 指令 :
SELECT * FROM employees
WHERE age > 30 AND department = 'Sales';
DBMS 可以選擇使用 idx_age 或 idx_department 來加速查詢,假設 idx_department 的選擇性較高 (即 Sales 部門的員工較少),那麼 DBMS 會選擇使用 idx_department。
Multi-Index Scan
有些資料庫支援多索引的查詢,可以透過多個索引來將找出每個對應的 record_id,並且將他們集合起來。 如 PostgreSQL 的 Bitmap Index Scan。
Modification Queries
DBMS 中的 modification 主要包含 INSERT、UPDATE 和 DELETE 三種操作,這些操作除了要修改 table 中的資料外,還需要檢查約束條件並更新相關的索引。
在 UPDATE 跟 DELETE 操作中,child operator 會跟蹤已經處理過的 tuple 並返回 record_id。
而在 INSERT 中有兩種實現方式,一種是自己 materialize tuple,另一種是接收 child operator 的輸出。
在 UPDATE 的過程中,還需要注意 halloween problem。
這個問題是指在更新過程中,由於更新後的 tuple 位置可能會改變,所以可能會更新到已經更新過的 tuple。
如下面這條 SQL 指令 :
UPDATE employees
SET salary = salary * 1.1
WHERE salary > 50000;
如果我們從頭到尾掃描 employees table,當我們更新一個員工的薪水後,這個員工可能會被重新放置在 table 的後面,導致我們再次掃描到這個員工並再次更新他的薪水,這樣就會導致薪水被多次更新。
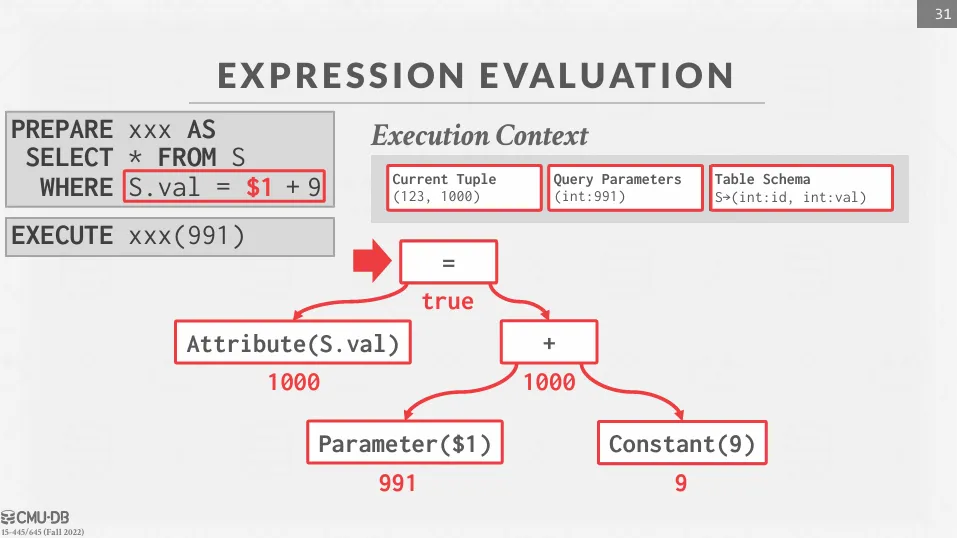
Expression Evaluation
DBMS 會將 WHERE 條件中的表達式轉換成一個 expression tree,遍歷之後產生結果,可以使用 JIT 編譯技術來加速表達式的計算。
JIT (Just-In-Time) 編譯是一種在程式執行時動態將中間表示 (如 bytecode) 編譯成機器碼的技術。這種方法可以結合了解釋執行和預先編譯的優點,提升程式的執行效率。
除此之外,還有兩種常見的優化方法 :
- Constant Folding : 在編譯階段就將常數表達式計算出來
- Sub Expression limitation : 將重複的子表達式提取出來,避免重複計算
Parallel vs Distributed Databases
在前面的討論中,我們都只專注在 single worker 的環境下,但是在現實中,我們會需要多個 worker 來平行處理 query。
在平行或分散式的系統中,資料庫會分布在多個資源中來提高 parallelism,這些資源可以是多個 CPU、多個硬碟、多個機器等,但在使用者的角度,這應該跟一個單一的資料庫是一樣的。
主要可以分成兩種架構 :
- Parallel Database : 物理連結較近,且通訊成本較小
- Distributed Database : 物理上分散較遠,且通訊成本較大
Process Model
Process model 定義了 DBMS 的多用戶平行處理的架構,我們會用 worker 這個詞來代表執行的單位,它可以是一個 process 或 thread。
Process per Worker
Client 端的請求經過 dispatcher 後會由 dispatcher 分配一個 worker 來處理,每個 worker 都是一個獨立的 process。
- 依賴於作業系統的 scheduler
- 使用 shared memory 來儲存全局的資料結構
- 單一的 process crash 並不會造成整個系統的 crash
這種 process model 主要出現在 pthread 還沒有穩定的時候,主要是為了解決移植性問題,如舊版的 Oracle 和 DB2 以及現在的 PostgreSQL。
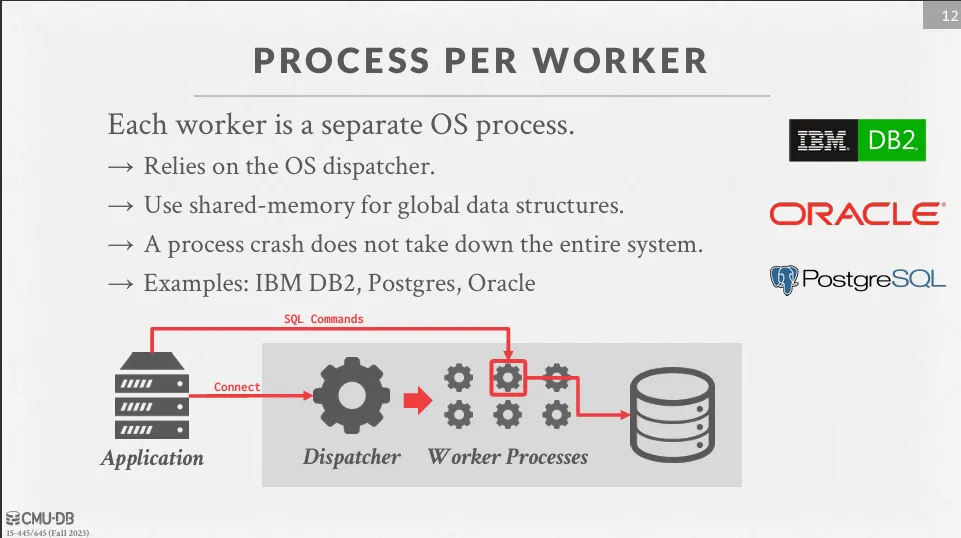
OS scheduler 會負責分解跟分派任務給 CPU core 並執行。
OS dispatcher 會負責接收 client 的請求並將請求分配給 worker。
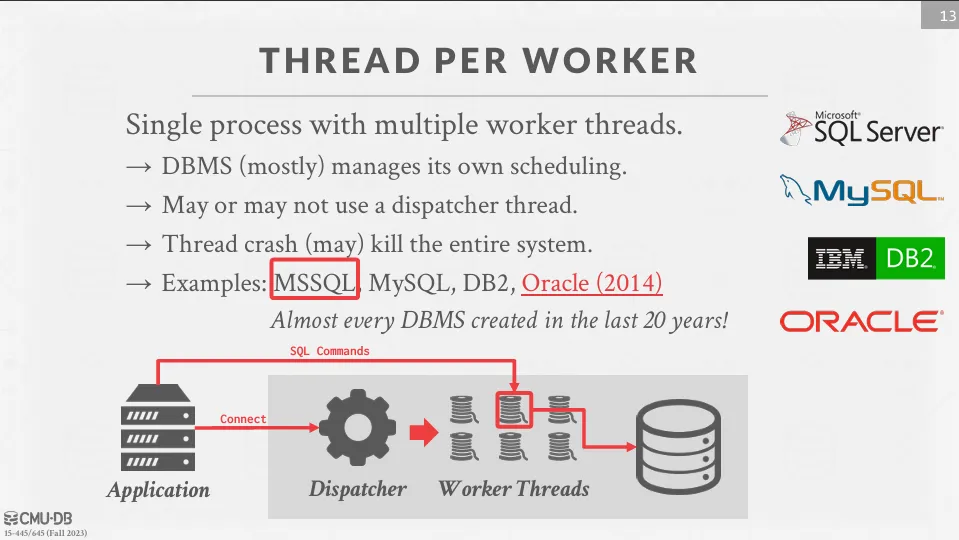
Thread per Worker
DBMS 由一個 process 和多個 worker thread 組成。
- DBMS 通常會自己管理 scheduler
- 可能沒有 dispatcher
- thread crash 可能導致系統崩潰
- 由於使用 thread,context switch 的成本較低,且不需要維護 shared model
這種 process model 是近年來最流行的,如 MySQL、SQL Server、MySQL 以及新版的 Oracle 都支持這種模型。
Embedded DBMS
Embedded DBMS 是一種與傳統 client-server 架構的 DBMS 不同的架構。 在這種架構中,DBMS 會直接在跟應用程式相同的 address space 中運行,並由應用程式負責 task 和 scheduler 的管理。
常見的有 SQLite、DuckDB、RocksDB 等。
Inter-Query Parallelism
Inter-Query Parallelism 是指同時執行多個查詢的能力,如果都是 read only 的查詢,那麼不需要多餘的協調,如果有 write 操作,則需要更多的機制來確保一致性,我們會在後面的章節中討論。
Intra-Query parallelism
Intra-Query Parallelism 是指通過平行化來將單個 query 分解成多個 operators 來提升性能。
在這個過程中,每個 operator 都是資料的 producer,也同時是其他 operator 的 consumer,這種設計使得平行算法可以應用於每個 relational operator。
使用額外的 process / thread 來平行執行 query 可以提高 CPU 的利用率,但如果瓶頸出現在 disk I/O 上,那麼這種平行處理就沒有太大的意義,甚至有可能因為 cache miss 而導致效能下降。
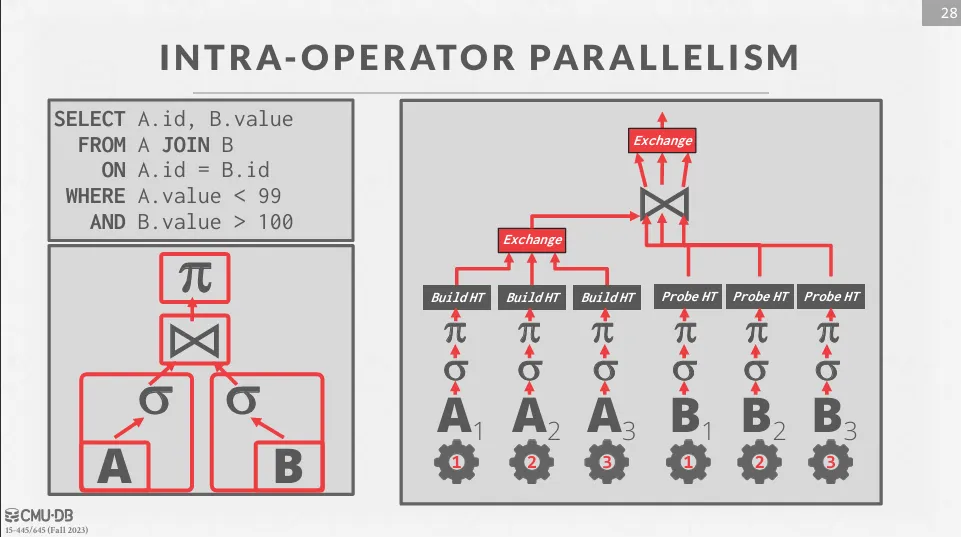
Intra-Operator Parallelism (Horizontal)
將資料拆解成多個子集,並透過 exchange operator 來合併子集處理的結果。
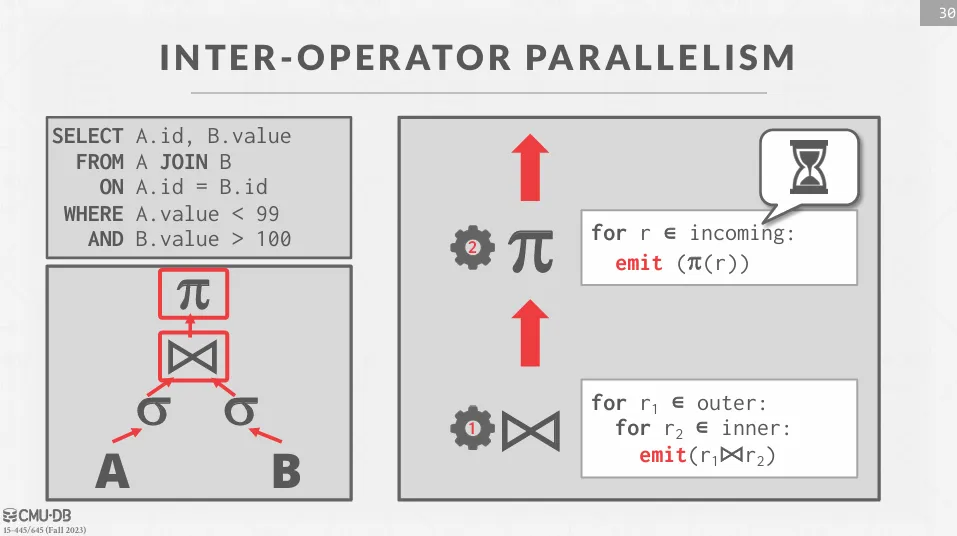
Inter-Operator Parallelism (Vertical)
將 operator 串聯成 pipeline,並由前一個階段不斷地產生 tuple 來供給下一個階段而不用等待整個階段處理完畢,也叫做 pipelined parallelism。 缺點在於處理速度會被最慢的 operator 所限制。
通常會在一些 streaming 的系統中使用,如 Spark、Flink 等。
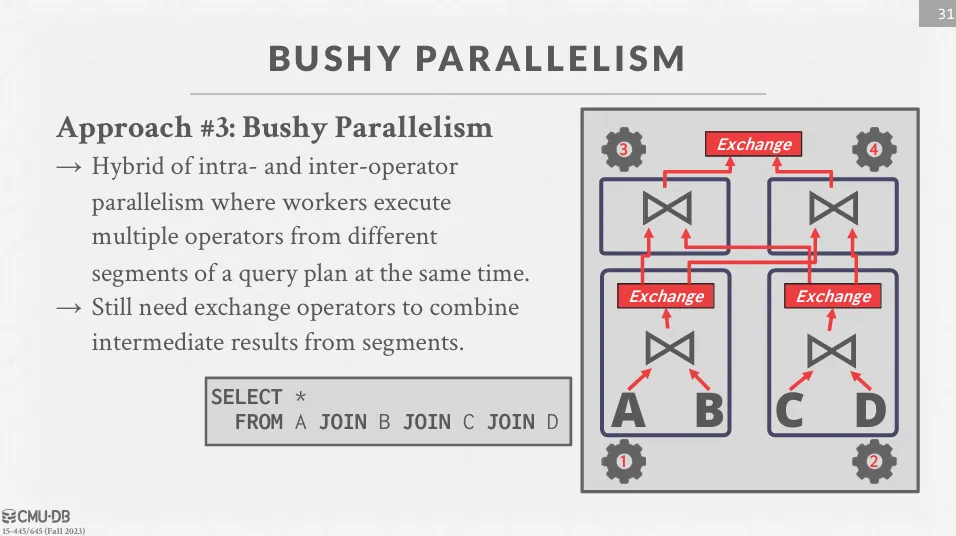
Bushy Parallelism
Bushy Parallelism 是 Intra-Operator 和 Inter-Operator Parallelism 的混合形式。
I/O Parallelism
I/O Parallelism 是指在 DBMS 中使用額外的進程或執行緒來平行執行查詢,以提高資料存取的效能。 這種技術旨在克服硬碟是主要瓶頸的情況,透過將資料庫分散在多個存儲設備上來提高效能。
Multi-Disk I/O Parallelism
在 multi-disk I/O parallelism 中,DBMS 會將資料庫檔案分散在多個硬碟上,這可以使用 RAID 來實現。
常見的 RAID 級別有 :
- RAID 0 : 將資料分散在多個硬碟上,可以提高讀寫效能,但沒有冗餘
- RAID 1 : 將資料複製到多個硬碟上,有冗餘但效能提升有限
- RAID 5 : 將資料和奇偶校驗資訊分散在多個硬碟上,提供冗餘且效能較好

Database Partitioning
可以將一個 logical table 分割成多個分開儲存的 physical segments,以提高 I/O 效能。