Hash Tables
為了能讓 DBMS 快速查找資料,我們需要使用一些資料結構來幫助查詢,其中最常見的是 Hash Table 跟 Tree。
在使用這些資料結構時,我們需要考慮以下兩點 :
- Data Organization : 要如何把資料放到 page / memory 中,以及需要哪些資訊來支持更高效的查詢
- Concurrency : 如何讓多個 worker 同時存取資料而不會出現問題
而本節我們會先討論 Hash Table,並在下一節討論 Tree。
Hash Tables
Hash table 是一個無序的資料結構,可以用來儲存 key-value pair,並且可以快速查找資料。
在實作細節上,主要可以分為兩個部分來討論 :
- Hash Function
- 如何將有較多可能性的 key 映射到較少可能性的 index
- 如何在速度跟 collision rate 之間取得平衡
- Hash Scheme
- 如何處理 collision
- 如何處理 resizing
Hash Function
在 DBMS 中,由於我們的資料不會暴露在外面,因此我們不需要使用加密的 hash function (如 SHA-256),我們只需要使用速度快且碰撞率低的即可。
目前常見的 hash function 有 Facebook XXHash、Google FarmHash 等等。
Static Hashing Schemes
在 static hashing schemes 中,我們會將所有的 key-value pair 放在一個固定大小的 table 中。
一些常見的 static hashing schemes 有 :
- Linear Probe Hashing
- Cuckoo Hashing
- Robin Hood Hashing
- Hopscotch Hashing
- Swiss Tables
這裡我們會介紹 Linear Probe Hashing 跟 Cuckoo Hashing。
Linear Probe Hashing
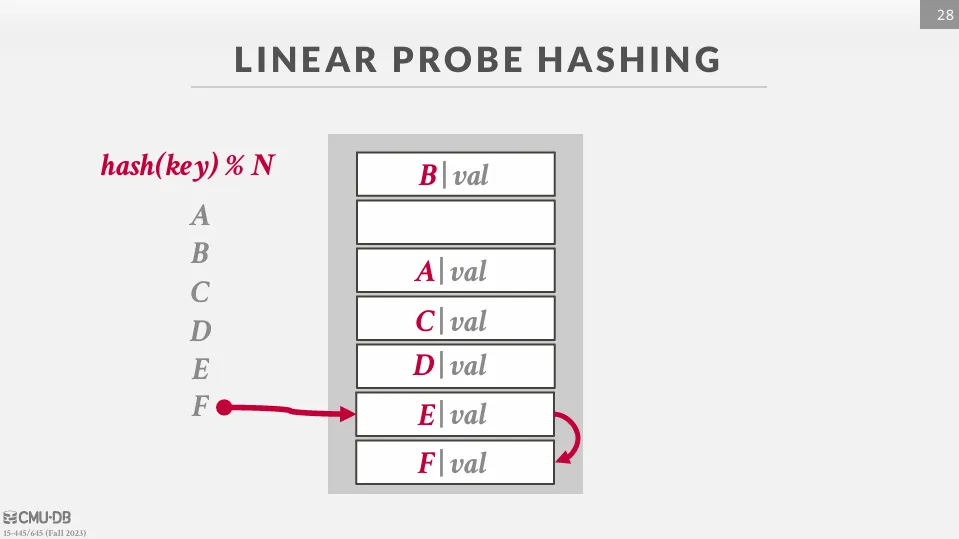
插入時,我們會在 slot 中儲存 key-value pair,發生 collision 時,我們會往下一個 slot 移動,直到找到空的 slot 為止。
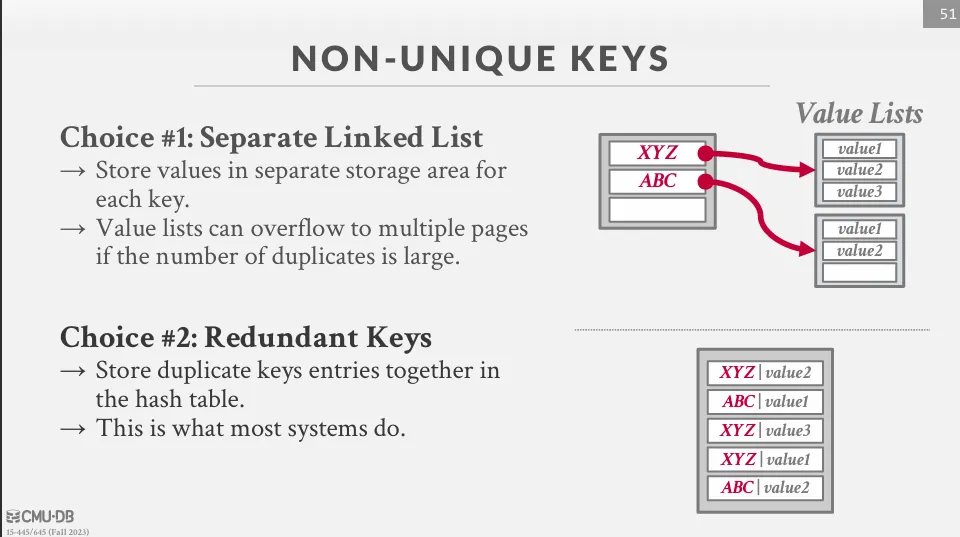
如果 key 不是 unique 的話,我們有兩種方式可以解決 :
- Separate Linked List : 將相同 key 的 value 串在一起,但這樣會導致每個節點都需要 new,不利於快取
- Redundant Keys : 在 slot 中儲存所有相同 key 的 value (大部分 DBMS 採用)
刪除有兩種方法 :
- Movement : 直接將後來的所有 slot 都做一次 rehash,直到遇到空的 slot (沒有 DBMS 會這樣做)
- Tombstone : 將 slot 中的 key-value pair 刪除,並在 slot 中放上一個特殊的值,表示這個 slot 已經被刪除,可能會需要定期清理 tombstone
以及一些常見的 optimization :
- 根據類型或鍵的大小來產生哈希表,例如,如果 key 是 string,可以依據 string 的長度選擇儲存 pointer 還是直接儲存 string
- 將 metadata 獨立儲存,例如將 empty slot 和 tombstone 的位置儲存在 bitmap 中
- 維護 hash table 和 slot 的版本,因為為 hash table 重新分配記憶體的開銷很大,因此可以使用版本來避免重新分配記憶體。如果 slot 跟 table 的版本不一樣,就表示 slot 為空。
Google 的 absl::flat_hash_map 是目前最先進的 Linear Probe Hashing。
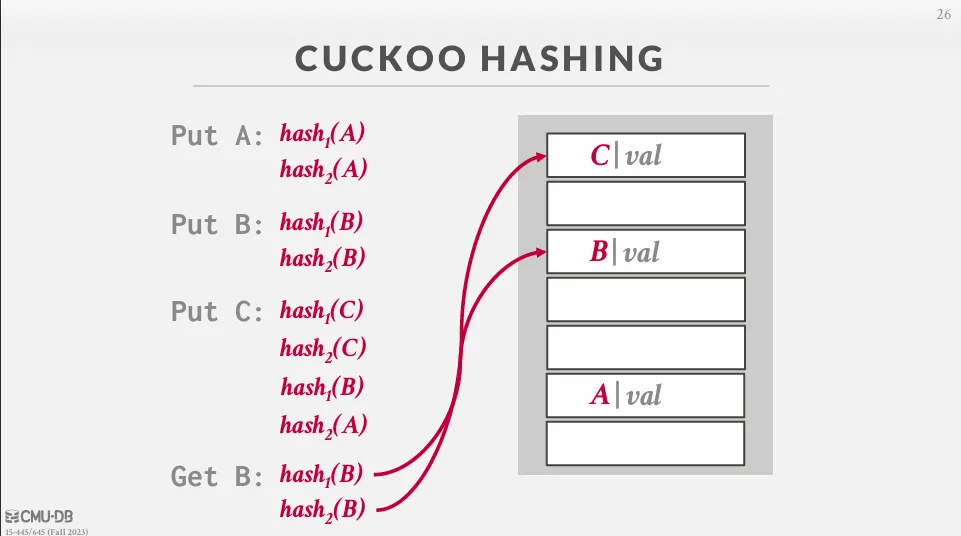
Cuckoo Hashing
Cuckoo Hashing 可以在 O(1) 的時間進行查找和刪除。
以圖片為例,我們會選擇一個 hash function 並使用不同的 seed 來找空的 slot,如果兩個都空的話就隨機選擇一個 slot 來放入 key-value pair,如果兩個都滿的話就隨機覆蓋一個,並將被覆蓋掉的遞迴執行一次 hash function 直到有一個 key 找到空的 slot。
在極少數的情況下,可能會出現 cycle,這時候我們可以重新使用新的 seed 全部 rehash (少見),或者直接搬到更大的 table 中 (常見)。
Dynamic Hashing Schemes
在很多情況下,我們無法知道我們最終需要多少的空間,因此我們需要使用 dynamic hashing schemes。
Chained Hashing
Chained hashing 會將每個可能的 hash value 對應一個 linked list,而 linked list 的每個 node 都是一個 bucket,如果這個 bucket 滿了就會再往後面加一個 bucket。
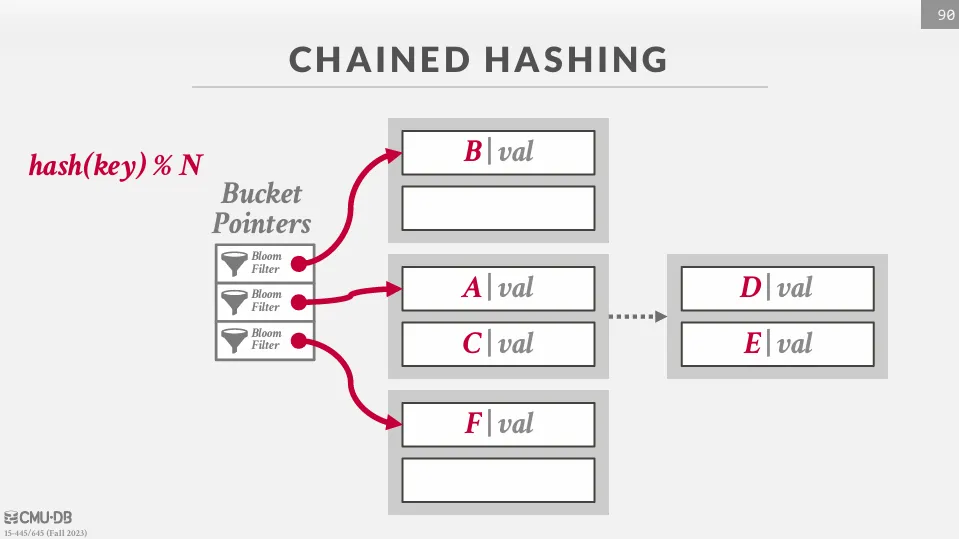
在 bucket pointer 中,我們可以使用 bloom filter 來加速查找,後面會再介紹 bloom filter。
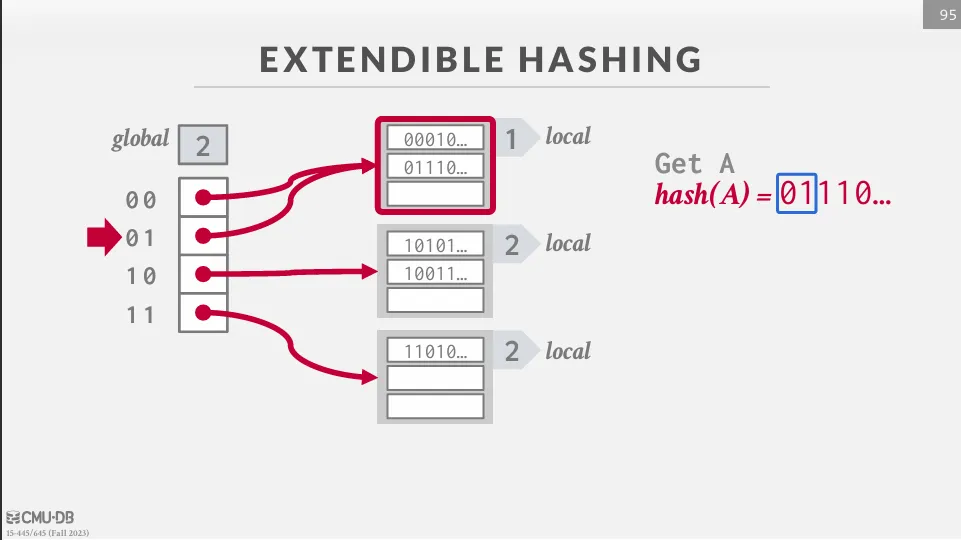
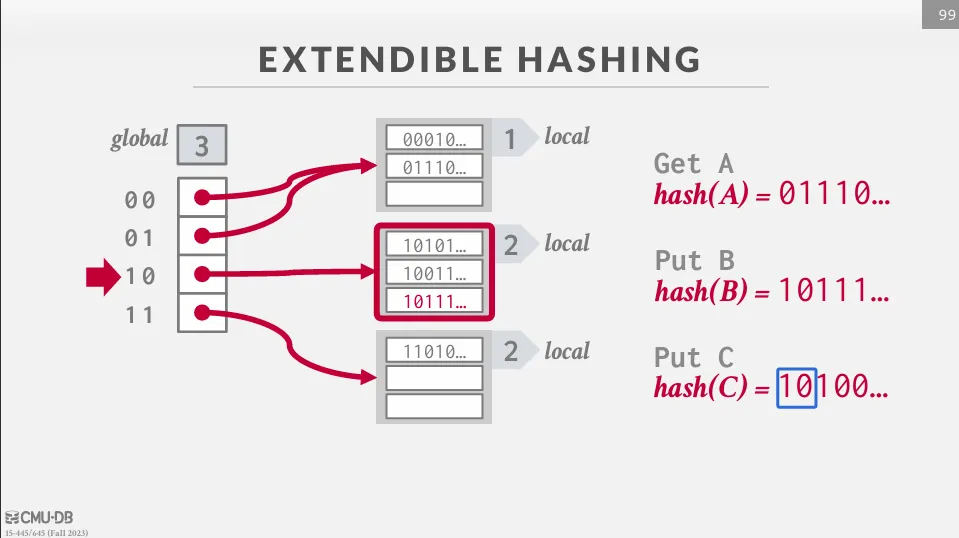
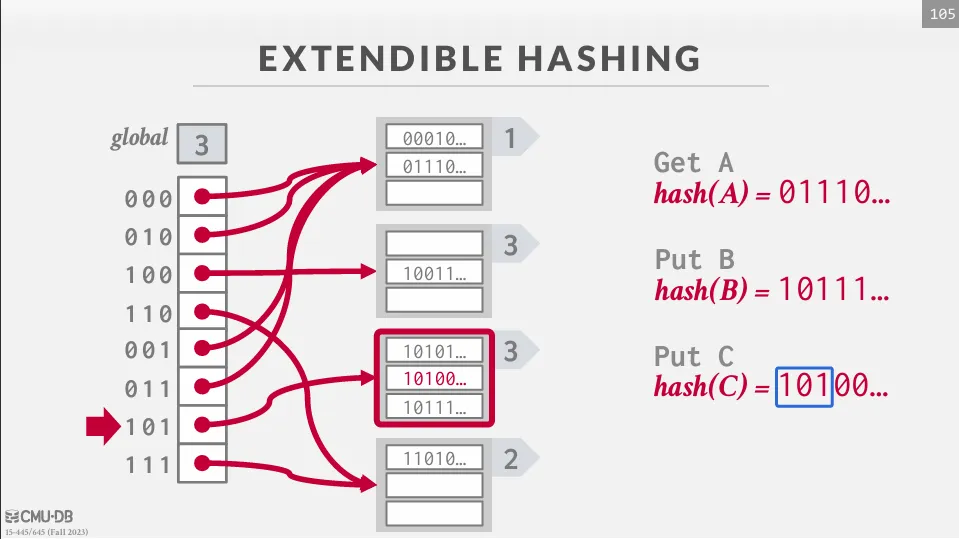
Extendible Hashing
Extendible hashing 與 chained hashing 有點類似,但是在 extendible hashing 中,我們不會把 bucket 串在一起,而是進行分裂。
在 Extendible hashing 中,我們會維護兩個 depth,一個是 global depth,另一個是 local depth。 除此之外,我們還需要維護一個 directory,它的大小為 ,裡面存放著每個 bucket 的 pointer。
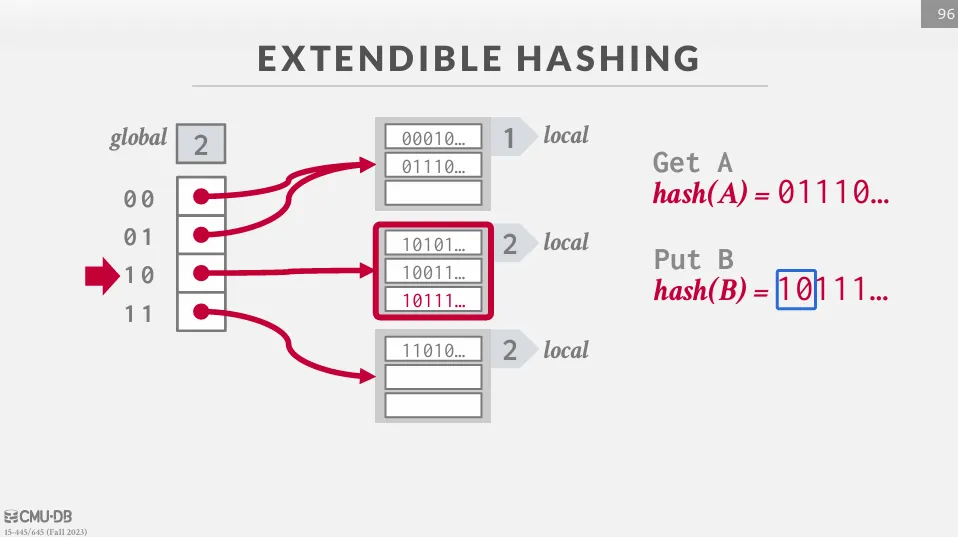
當我們要查詢一個 key-value pair 時,我們會先使用 hash function 來計算 hash value 並得到一組位元 (0101010...)。 然後根據 global depth 來決定要使用多少 bits 來找 bucket,如果是 global depth 為 3 的話,我們就會使用前三個 bits (010) 來找 bucket。 找到之後線性掃描 bucket 中的 key-value pair,如果有空的 slot 就直接插入,如果沒有空的 slot 就需要分裂這個 bucket。
當要插入時,如果 bucket 已經滿了,我們需要先檢查這個 bucket 的 local depth 是否等於 global depth。 如果相等的話,我們需要將 global depth 加一,並且將 directory 的大小翻倍 (將原本的 pointer 複製一份) 並重新指向 bucket。 最後將這個 bucket 分裂成兩個 bucket,並且把原本 bucket 中的值重新 hash 到新的 bucket 中。
Linear Hashing
Linear hashing 中放棄了哪裡滿了就分裂哪裡的概念,而是採用預先規劃好的分裂順序。
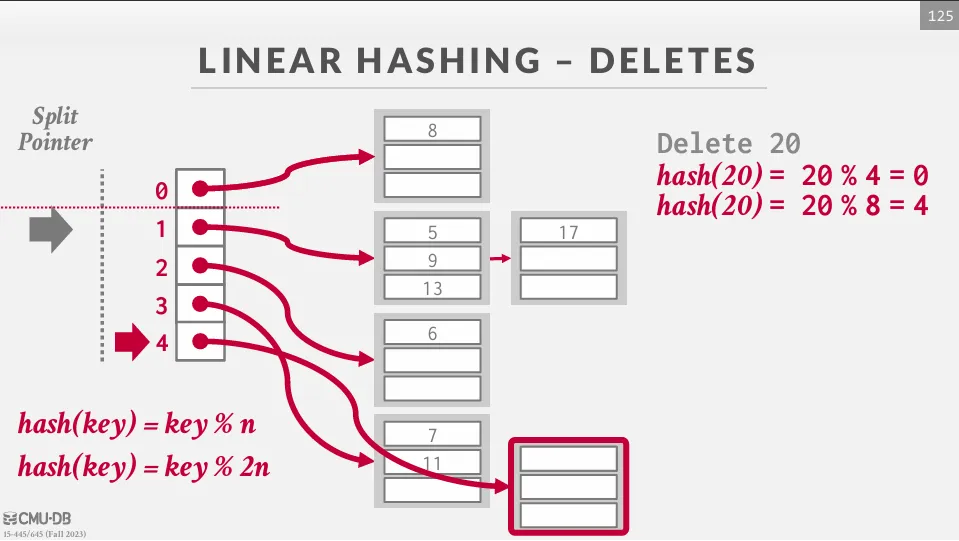
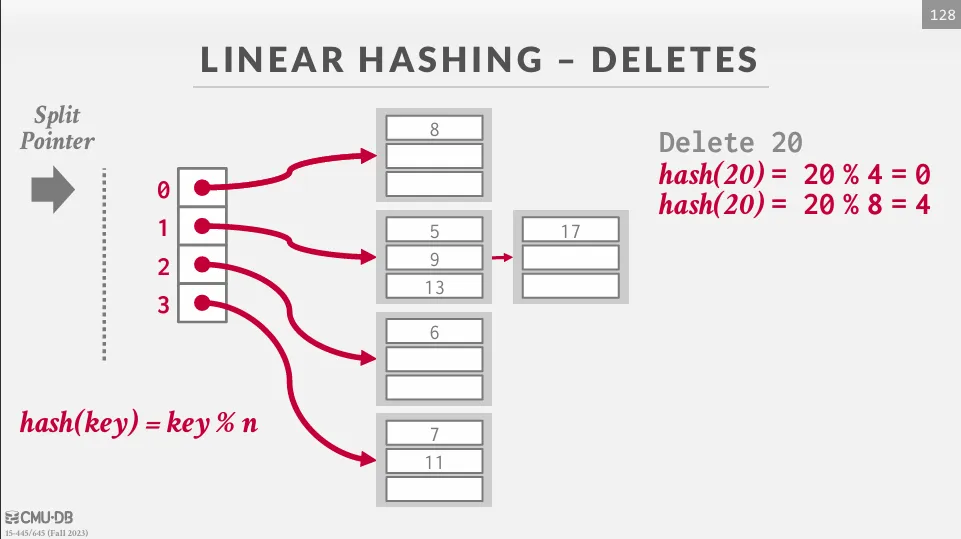
維護一個 split pointer 指向下一個要被分裂的 bucket,當任意一個 bucket 滿了時,就新增一個 bucket 並將指針指向的 bucket 分裂,最後把這個分裂的 bucket 中的值重新 hash 到新的 bucket 中。
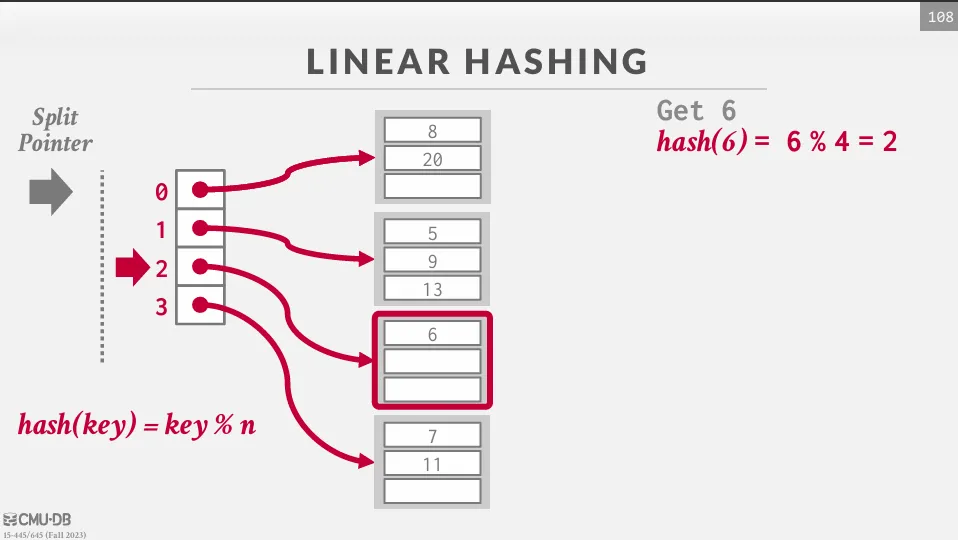
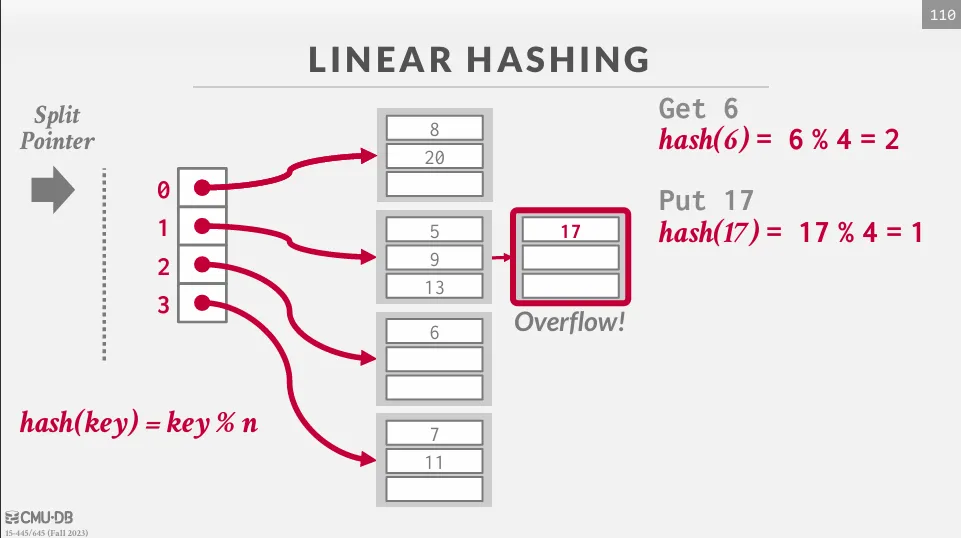
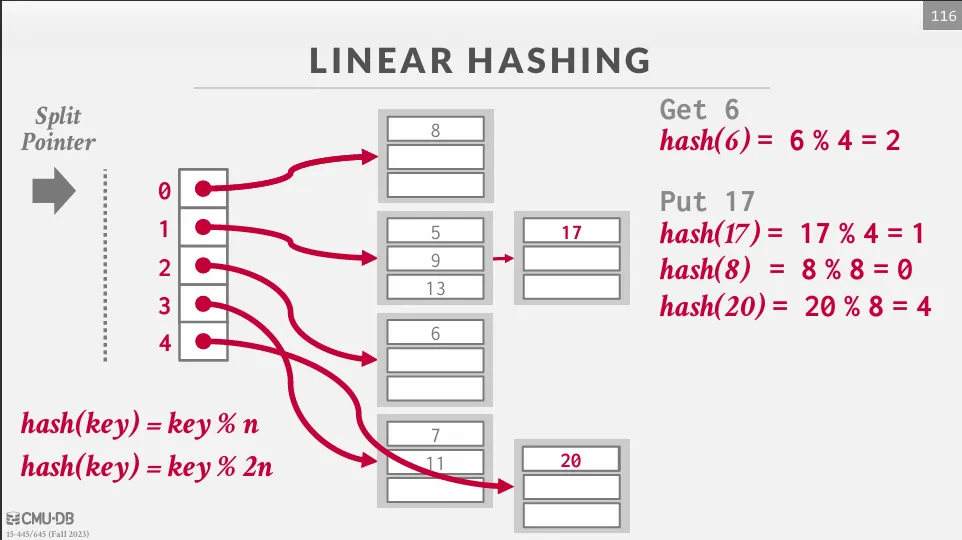
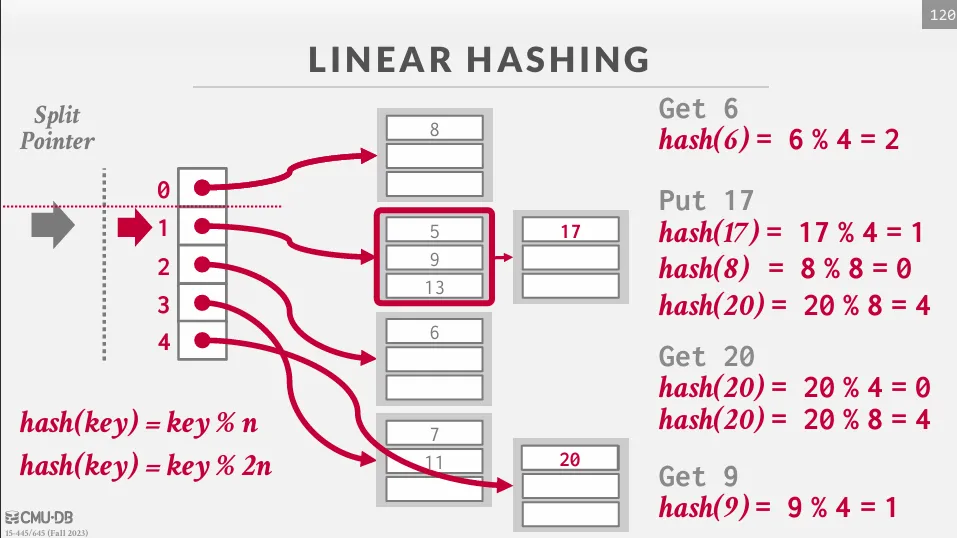
隨著分裂指針的移動,最終所有溢出的桶都會被處理到,當分裂指針到達最後一個 bucket 時,我們可以將第一個 hash 移除只使用第二個 hash,並且將分裂指針歸零。 如果在最下面一個 bucket 是空的,我們可以移除這個 bucket 並反向移動指針。