Memory & Disk I/O Management
這節會討論 DBMS 如何讓資料在硬碟跟記憶體中移動,主要分為兩個部分 :
- Spatial Control : 決定把 page 寫到硬碟中的哪個位置,目標是將常常需要一起用到的 page 放在一起來提高 I/O 效率
- Temporal Control : 決定甚麼時候要把 page 讀進記憶體或是寫回硬碟,目標是降低 I/O 的停頓時間
Buffer Pool Management
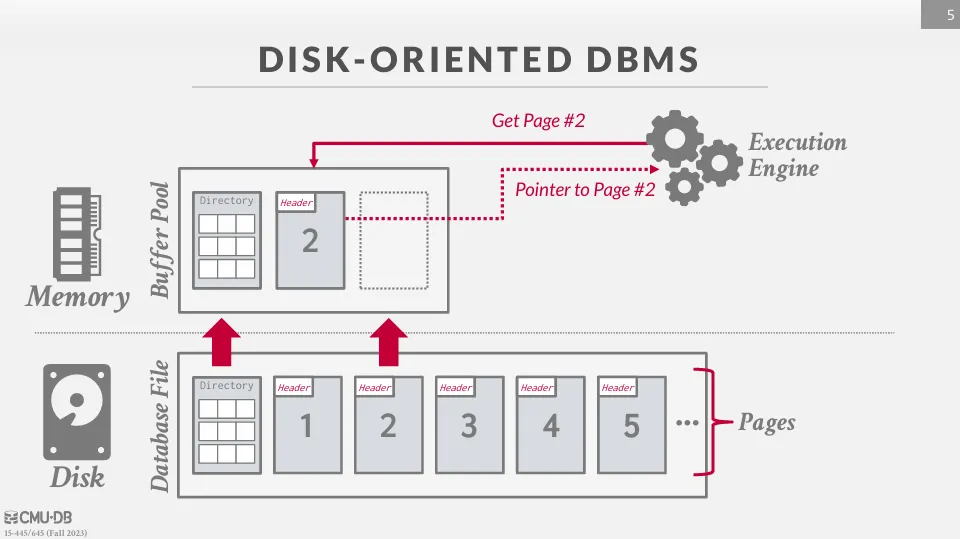
在啟動 DBMS 時,DBMS 會向 OS 申請一塊記憶體來存放 page,這塊記憶體就是 buffer pool。 DBMS 會將這塊記憶體分成多個 frame,每個 frame 就可以對應到一個 page,當需要讀取 page 時,就把 page 讀進 frame 中。
同時 DBMS 會維護一個 page table 來記錄每個 page 在記憶體中的位置,也會記錄一些 metadata,比如 dirty flag (是否被修改過)、Pin / Reference Counter (是否被使用中) 來幫助管理 page。

當 page 被引用時,DBMS 會將這個 page 的 reference counter +1 表示這個 page 正在被使用中,不能被移出記憶體。 當我們要請求不在記憶體中的 page 時,DBMS 會先請求一個 latch,然後把 page 讀進 buffer pool 中,再釋放 latch,這樣可以避免多個 thread 同時修改同一個 entry。
DBMS vs OS
DBMS 與 OS 都涉及記憶體與硬碟的管理,但兩者的設計目標跟方向都不太一樣。 DBMS 希望能處理比記憶體大很多的資料,並在讀取時保持低延遲,而作業系統提供的機制主要是通用且保護整個系統的安全性與穩定性。
DBMS 可以被理解為一個擁有虛擬地址空間的系統,它決定何時將硬碟上的資料 (page) 載入記憶體,類似 OS 的虛擬記憶體概念。 但如果直接使用 OS 提供的機制 (例如 mmap),會帶來幾個問題 :
- 交易安全性 : OS 會在任何時間點把 dirty page 寫回硬碟,破壞 DBMS 的 ACID 保證
- IO 停頓 : DBMS 不知道哪些頁面在內存中,在 page fault 時,OS 會使線程停頓
- 錯誤處理 : 難以驗證頁面,任何訪問都可能導致 DBMS 必須處理 SIGBUS 信號
- 性能問題 : OS 根據查詢需求來管理頁面,無法進行預取或是最佳化 IO
因此,DBMS 通常會使用較為低階的 system call 來管理資料,像是 :
madvise: 告訴 OS 我們需要哪些頁面mlock: 告訴 OS 哪些頁面不能被寫入msync: 通知 OS 將某些記憶體寫到硬碟上
透過這些 system call,DBMS 可以更有效率的管理記憶體與硬碟。
Buffer Replacement Policies
當 buffer pool 被填滿時,DBMS 需要透過演算法來決定要將哪個 page 移出記憶體,這個演算法稱為 replacement policy。
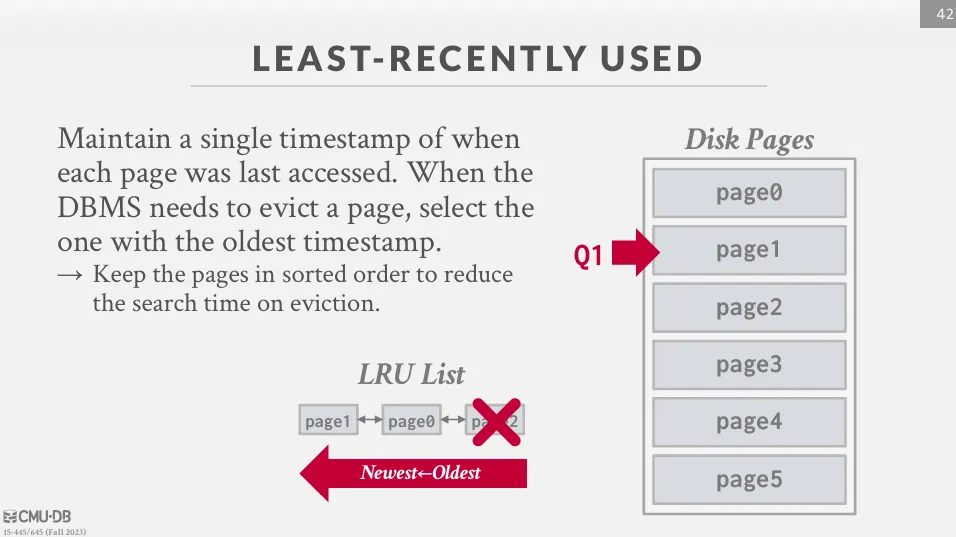
Least Recently Used (LRU)
LRU 會將最近最少被使用的 page 移除,這個策略的假設是最近被使用過的 page 在未來也會被使用到。 通常會使用 linked list 來記錄每個 page 最後一次被使用的時間,如果滿了,就把最久沒被使用的 page 替換掉。
Clock
與 LRU 類似,但是 clock 不需要紀錄上一次訪問的時間,而是記錄一個 reference bit。
- 當 page 被訪問時,reference bit 會被設為 1。
- 當需要移除 page 時,從上一次的位置開始,輪流詢問 reference bit, 如果 reference bit 是 1,則將 reference bit 設為 0,然後繼續往下找。 如果 reference bit 是 0,則將這個 page 移除。

LRU-K
不管是 LRU 還是 clock,都會遇到 sequential flooding 的問題,也就是指最新讀取的 page 反而是最不需要的 page,也因此有了 LRU-K 來解決這個問題。
LRU-K 會保存每個 page 最後 k 次被訪問的時間,然後根據這個時間來預估下次被訪問的時間,如果 k = 1 就是 LRU,通常會使用 k = 2。
MySQL 就是採用了類似的概念叫做 midpoint insertion strategy。 這種方法會將 list 分成 young list 跟 old list,當新的 page 被訪問時,會被放到 old list 的最前面,而當 old list 裡面的 page 被訪問到時,會被放到 young list 的最前面。

Buffer Pool Optimization
除了選擇適合的 replacement policy 外,DBMS 也會透過其他方式來優化 buffer pool。
Multiple Buffer Pools
DBMS 可以維護多個 buffer pool,每個 buffer pool 有不同的大小和替換策略,這麼做可以減少 latch 的競爭,並且可以為不同型態的 page 選擇不同的存取策略。
例如可以有以下幾種 buffer pool :
- Multiple buffer pool instances
- Per-database buffer pool
- Per-page type buffer pool
常見的分配方式有兩種 :
- Object_id : 在 record 中產生一個 object_id,然後維護一個 hash table 來記錄 object_id 對應到哪個 buffer pool
- Hashing : 根據 page_id 的 hash 來決定放在哪個 buffer pool
Prefetching
DBMS 可以透過 query plan 來預測未來可能會用到的 page,然後提前把這些 page 讀進 buffer pool 中。
Scan Sharing (Synchronized Scans)
Scan sharing 主要是在有多個查詢同時進行 sequential scan 時,可以共享同一個 scan 的結果。 舉例來說,如果有 A 和 B 兩個查詢先後進行,當 B 開始查詢時,可以先跟 A 一起掃描,等到 A 結束時,自己再重新掃描一開始缺少的部分。
Buffer Pool Bypass
當需要使用 sequential scan 來掃描資料量很大的表時,如果 DBMS 將每個 page 都讀進 buffer pool 中,就會導致 buffer pool 被汙染,因此我們可以單獨分配一塊記憶體來存放這些 page。
Localization
在 DBMS 中,如果有大型的查詢 (SELECT * FROM large_table),會需要讀取大量的 page,這樣會導致 buffer pool 被汙染,因為這些 page 大多只會被使用一次。
而 localization 就是用來處理這個問題的,它的意思是系統不會全局共享一個 buffer pool,而是根據每個查詢來分配 buffer pool 的空間,當要替換時就優先移除這個查詢所使用的 page。
以 PostgreSQL 為例,它會對每個查詢維護一個 ring buffer 用於限制查詢可使用的 buffer 數量,當查詢繼續讀取新的 page 時,會將 ring buffer 中最舊的 page 替換掉。
Dirty Page Flushing
當 buffer pool 中的 page 被修改後,該頁會被標記為 dirty page,表示記憶體中的內容已經和磁碟上的版本不一致。 在淘汰 dirty page 之前,DBMS 必須先將其寫回磁碟,否則會造成資料遺失或不一致。
由於寫入磁碟的成本高,若在淘汰時才同步,會導致延遲。 因此 DBMS 會使用 background writer,週期性地將 dirty page 刷回磁碟,清除 dirty 標記。
OS problem
總體來說,DBMS 應該盡量減少對 OS 的依賴。
Scheduler
硬碟 I/O (特別是 HDD),是需要非常久的時間來完成的,因此 OS 為了提高整體系統的效能,會透過 I/O Scheduler 來合併及管理 I/O 請求。
但問題在於 OS 並不會知道那些東西對 DBMS 來說是重要的,譬如說 WAL 肯定比其他資料重要,而 VACUUM 相對來說就不那麼重要。 所以許多 DBMS 會建議使用 deadline 或 noop scheduler (FIFO) 來盡量減少 scheduler 的影響,如 MySQL、Oracle。
同時,DBMS 會自己有一個 scheduler 來管理讀寫請求,它會根據請求的類型來自己決定讀寫的順序。
Page Cache
OS 會維護一個 page cache 來存放最近被讀取的 page,但這有可能會跟 DBMS 衝突,並導致雙重快取或是不一致的問題。
因此通常會使用 O_DIRECT 來避免這個問題,除了 PostgreSQL 以外。
