Database Storage
這篇筆記會討論在 disk-oriented 的 DBMS 上,資料是如何被儲存與管理的。
Storage
首先我們需要了解電腦的儲存結構。
如下圖所示,電腦的儲存結構是 hierarchical 的,越靠近上方的儲存設備離 CPU 越近,速度也越快,但同時容量也越小,價格也越貴。
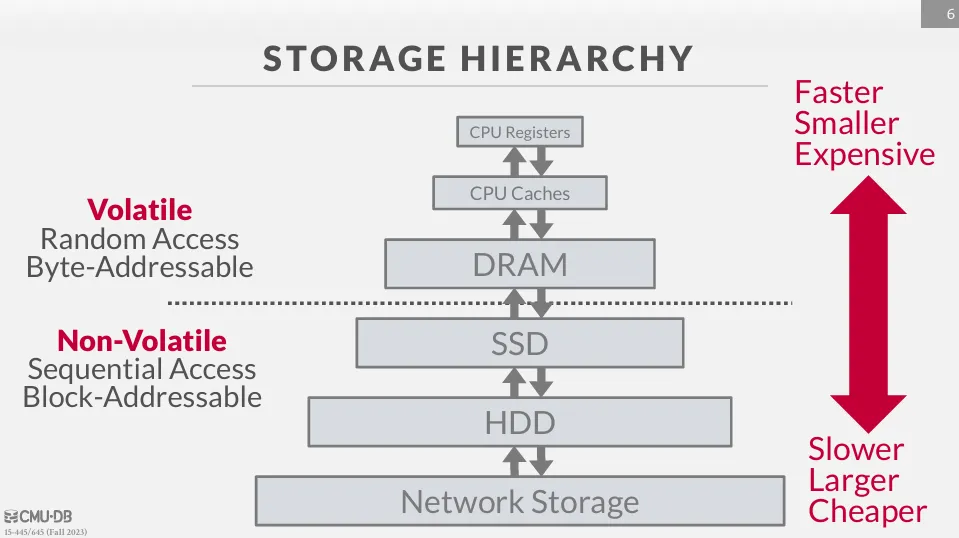
通常來說,所謂的 volatile storage 指的就是一般所說的記憶體 (memory),而 non-volatile storage 指的就是硬碟 (disk)。
他們的差別如下 :
- volatile :
- 當電源關閉時,資料會遺失
- 支持快速的 random access,可以由 byte address 直接存取
- non-volatile :
- 當電源關閉時,資料不會遺失
- 資料主要以 block 或是 page 的形式存在硬碟上
- 如果我們想要存取某個資料,我們需要將 page 讀進記憶體中,然後再透過 offset 來存取我們想要的資料
- 通常擅於使用 sequential access 來存取資料
除此之外,也有一些其他的儲存方式,如 Intel 的 Optane 等等,但都不在這篇筆記的討論範圍內。
Disk-Oriented DBMS Overview
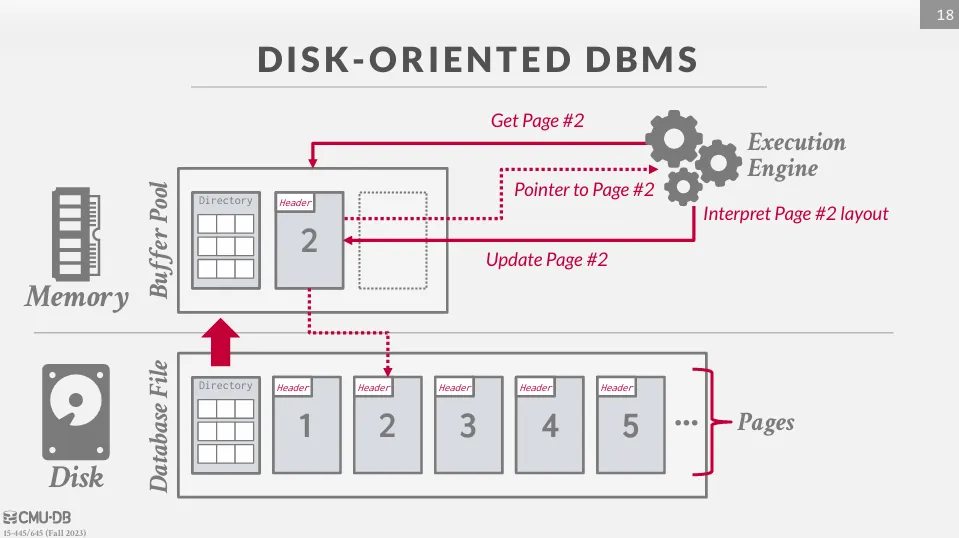
在資料庫中,所有的資料都會被存在固定大小的 page 中,而這些 page 會被存在硬碟上。
當 execution engine 需要存取某個資料時, buffer pool 會先從讀取目錄,並且依據目錄中的資訊把 page 讀進記憶體中,最後再返還給 execution engine 這個 page 的指標。
File Storage
DBMS 需要管理大量資料,而這些資料通常遠大於記憶體容量。 因此,這些資料必須儲存在硬碟檔案上,並透過 DBMS 的 storage manager 進行存取與管理。
Database Page
DBMS 會將一個固定大小的區域稱為頁面 (page),這是硬碟與記憶體之間傳輸的最小單位。 不同的 DBMS 有不同的頁面大小,像是 PostgreSQL 使用 8kb。 page 可以包含不同種類的資料,像是 tuple、index、log 等等,不同種類的資料通常不會被存在一個 page 中。
通常來說,一個檔案會包含多個 page,而每個 page 都有一個獨立的 page_id,DBMS 會透過 indirection layer 將 page_id 與 file path 跟 offset 對應起來。
為了滿足各種需求,DBMS 有不同的儲存頁面的方式,像是 :
- Heap File Organization
- Tree File Organization
- Sequential / Sorted File Organization (ISAM)
- Hashing File Organization
Heap File Organization
如前面所提到的,我們有很多方法來管理頁面,其中最常見的方式是 heap file organization。
Heap file 是一個無序的集合 (unordered_set),裡面的 page 都是隨機存儲的。 這種結構的優點在於插入效率高,且不需要額外維護一些如排序之類的結構。
有兩種方式可以定位一個 page :
- Linked List
- Page Directory
Linked List
有一個 header page 儲存指向 free page 和 data page 的指標,但如果要找到某個 page 需要從頭開始找。
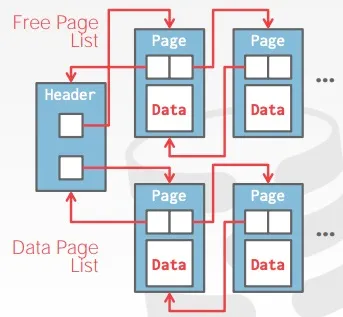
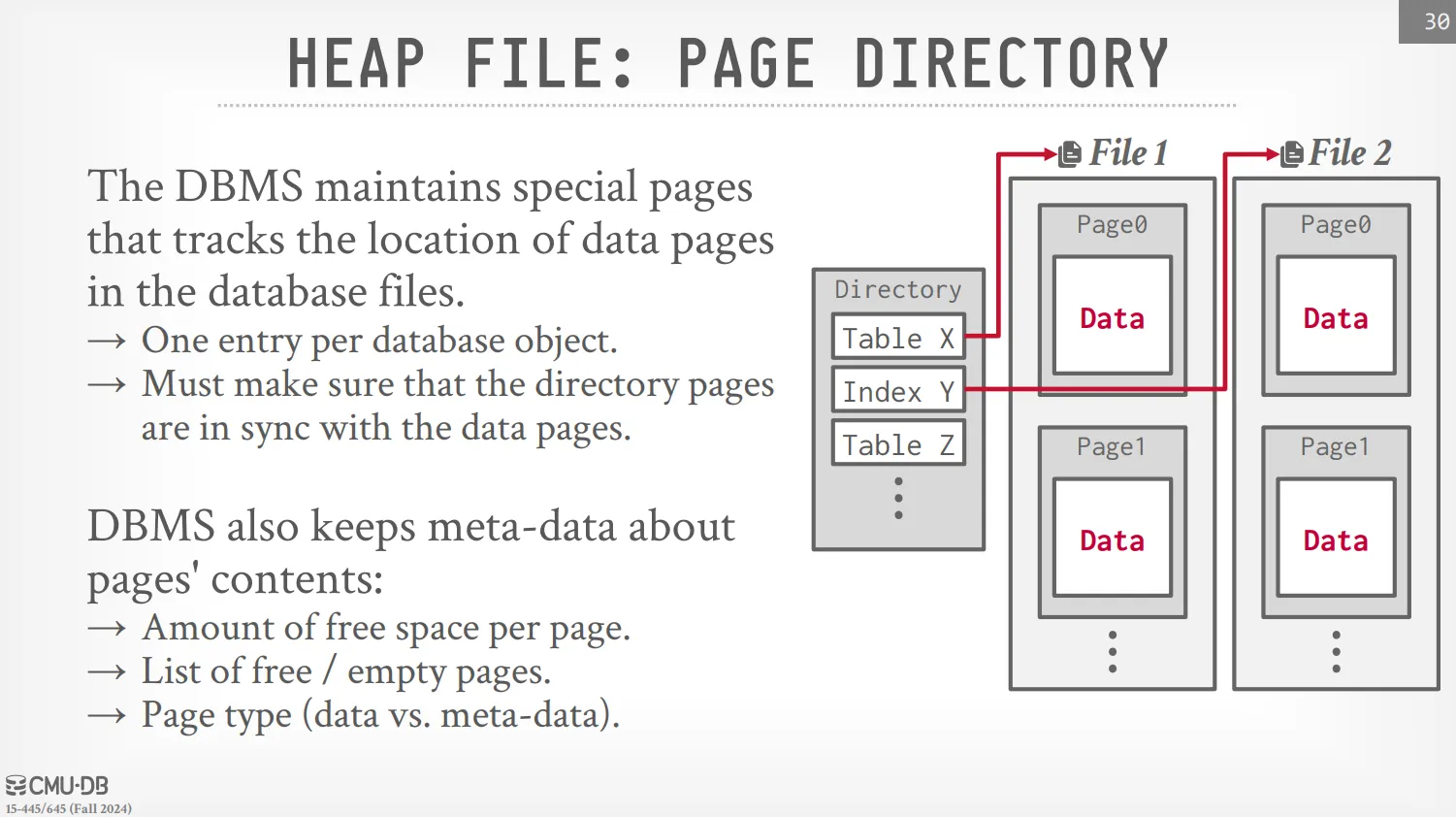
Page Directory
儲存一個目錄頁,用於告訴我們那些 page 是存在哪裡,DBMS 需要保證 directory page 跟 data page 是同步的。
Page Layout
接下來會介紹資料在 page 中的儲存方式,每個 page 會被分成 header 跟 data 兩個部分。
Page Header
header 中會包含一些 metadata,像是 :
- Page size
- DBMS version
- Checksum
- Transaction visibility
- Compression information
有些資料庫也會儲存一些統計值等等。
Page Data
對於 row-based 的 DBMS 來說,page data 有以下幾種常見的儲存方式 :
- Tuple-oriented storage
- Log-structured storage
- Index-organize storage
Tuple-oriented Storage
Tuple-oriented storage 是一種最常見的儲存方式,它會以 tuple 為單位來儲存資料,常見的實作方式有兩種 :
- Strawman Idea
- Slotted Page
Strawman Idea
在 header 中記錄 tuple 的數量,並持續往下寫入 tuple。
這個方法有不少缺點,第一個缺點是刪除 tuple 後,每次新增新的 tuple 就需要遍歷整個 page 來找到空位,且當欄位有可變長度的時會無法處理。

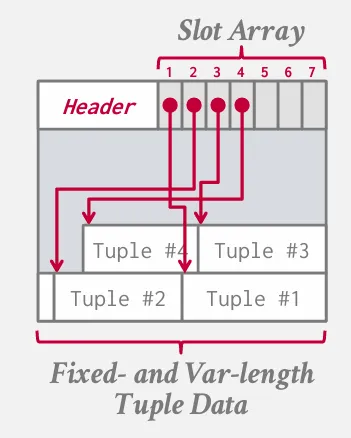
Slotted Page
在 header 中會紀錄當前有幾個 slot 已經被使用,同時記錄 free space 的起始位置,並且有一個 slot array 來記錄每個 slot 的 offset 跟 length。
要新增 tuple 時,先新增一個 slot 到 slotted array 中 (可以重用被刪除的 slot),然後再寫入 tuple,並由兩端向中間生長,這樣當兩者相遇的時候就知道 page 已經滿了。 要刪除 tuple 時,只需要將 slot array 中的 slot 標記為刪除即可。 進行壓縮 (如 VACUUM) 時,可以將所有的 tuple 移到一端,然後更新 slot array 的 offset 跟 length 即可。
是目前最常見的儲存方式。
Log-structured Storage
在傳統的資料庫系統中,資料通常以 slotted page 的方式存在硬碟中。 這種設計有一個核心假設是硬碟要可以就地更新 (in-place update)。 也就是說,如果某個 tuple 的欄位需要更新,系統只要找到它所在的頁面,把該區塊載入記憶體,修改 tuple,再將頁面寫回磁碟即可。
然而,這種方式有幾個問題:
- Fragmentation : 刪除 tuple 之後會留下空洞,頁面無法被充分利用
- Useless disk IO : 即使只改動一筆 tuple,也要將整個頁面載入並寫回
- Random disk IO : 當一次要更新很多 tuple 時,會需要讀取很多個不同的頁面,導致大量的隨機 IO
除此之外,也有一些系統 (如 HDFS) 根本不允許覆寫舊檔案,這使得傳統的儲存方式無法使用。
為了解決這些限制,研究者從 Log-Structured File System (LFS) 與 Log-Structured Merge Tree (LSM-tree) 中獲得啟發,提出了 Log-Structured Storage。 在這個儲存模式下,DBMS 不會直接修改舊的頁面,而是將更新的資料以 log 的形式附加 (append-only) 到檔案的末尾,並且定期進行壓縮 (compaction) 來整理資料。
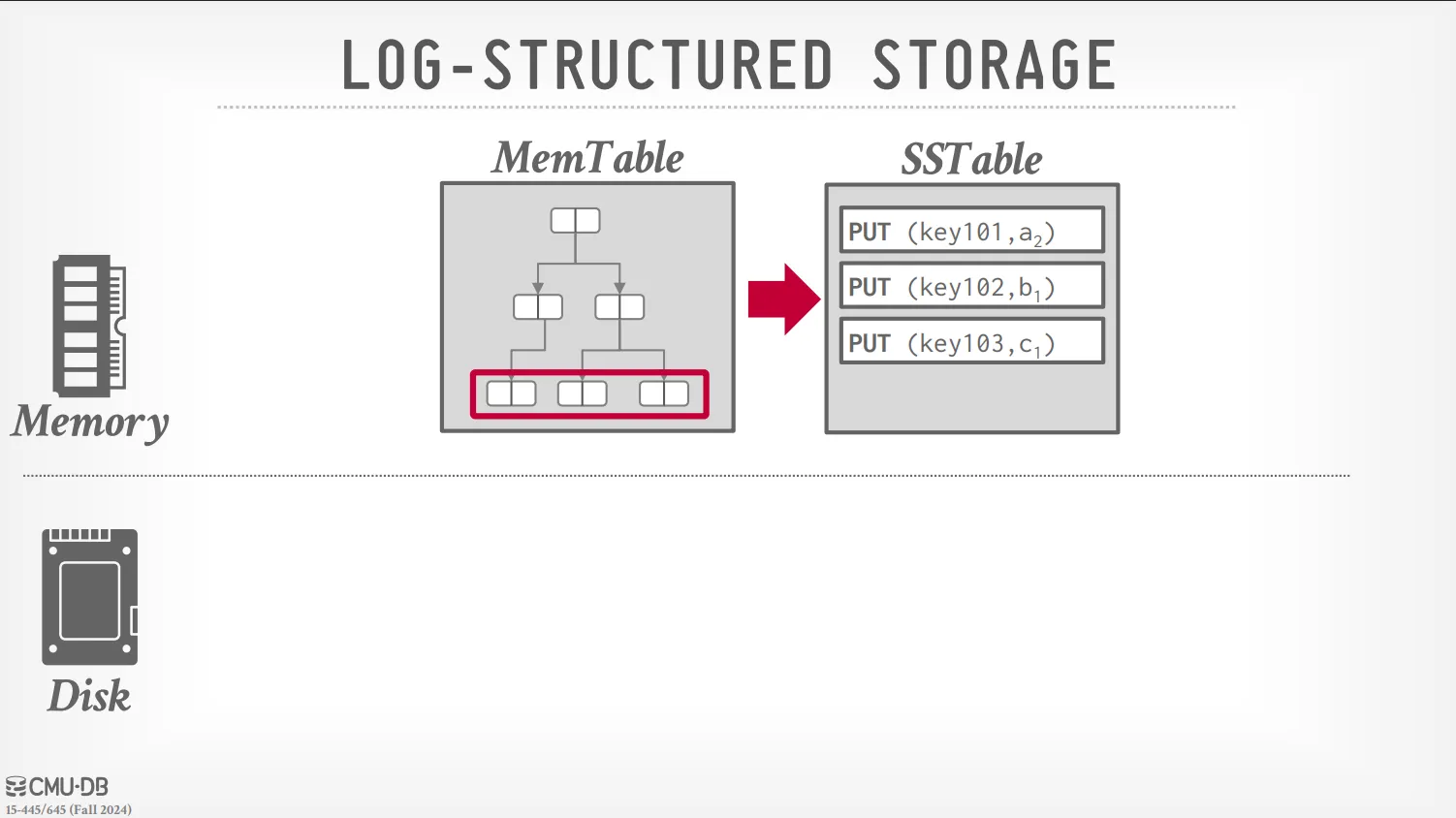
LSM Tree 是一種設計架構,它會協調 Memtable 跟 SSTable 來將隨機寫入轉換成順序寫入,並且定期將 MemTable 的資料寫入 SSTable 中並進行壓縮,從而最大化寫入效能。
當資料寫入時,它會先記錄 WAL (Write-Ahead Log) 以確保交易的持久性,然後將資料寫入 Memtable 中。當 Memtable 滿了之後,會將其內容寫入 SSTable 中,並且清空 Memtable。
MemTable 是一個存在記憶體中的資料結構,通常是使用跳表 (skip list) 或是平衡樹 (AVL、RBT) 來實作。
SSTable 是一個存在硬碟上的資料結構,指的是排序的字串表 (sorted string table),只要被寫入就不會再被更改。
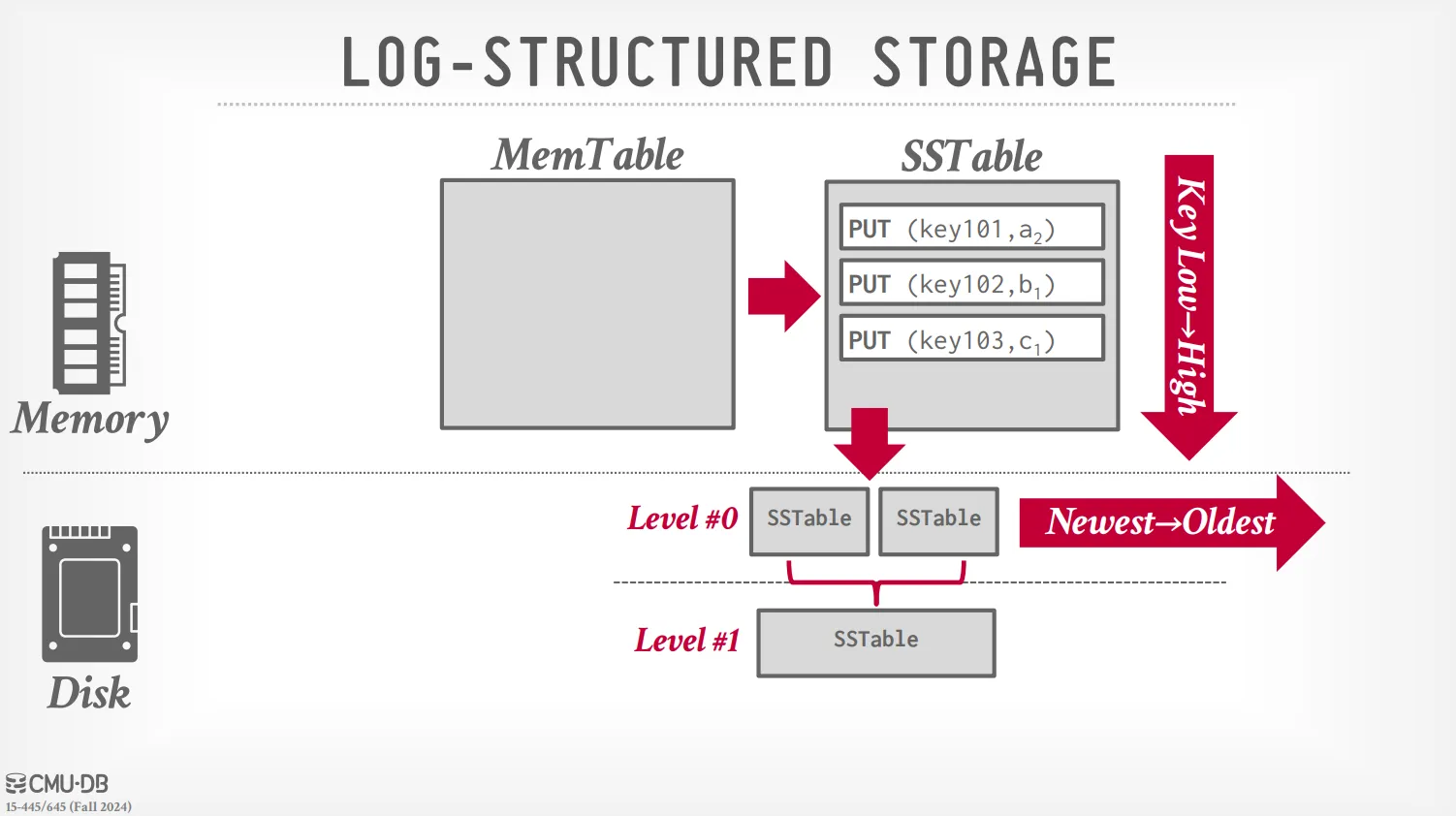
為了減少所需的空間,DBMS 會定期將 log 進行壓縮,並且將相同的操作合併在一起。 在經過合併後,我們就不需要維護原本的時間順序了 (因為每個 key 都只剩下一個 value),DBMS 會將其依照 id 來進行排序並存入硬碟,也就是上面提到的 SSTable。
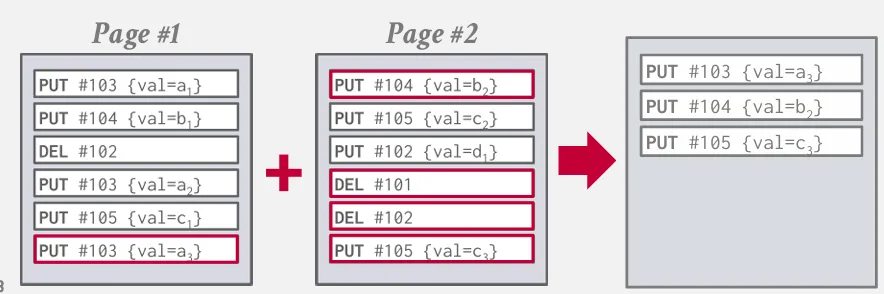
壓縮的方法有兩種 :
- Universal compaction : 將大小相近的一組 SSTable 合併成一個更大的 SSTable。
- Level compaction : 將 SSTable 分成多個 level,並且將較小的 level 合併到較大的 level 中。
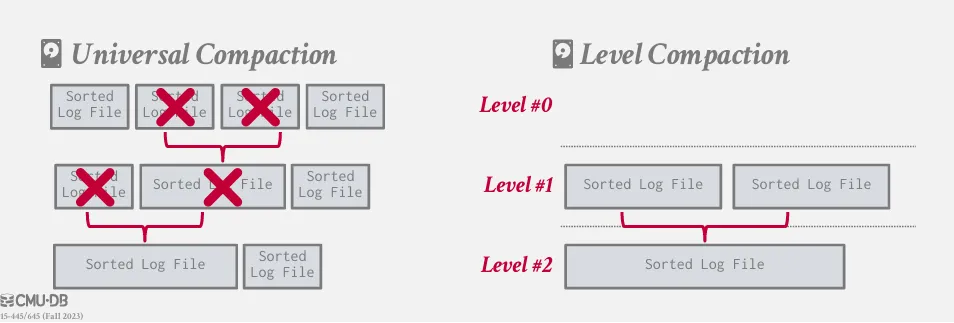
在查詢時,LSM Tree 的查詢順序如下 :
- 先在 MemTable 中尋找
- 查詢 L0 層的 SSTable,L0 的 SSTable 通常是直接從 MemTable 刷下來的,檔案之間 key 的範圍可能重疊,所以需要逐一檢查。
- 查詢 L1, L2, ... 層的 SSTable,這些層級的 SSTable 經過 Compaction,同一層內 key 的範圍互不重疊。因此,系統可以透過 key 的範圍判斷出目標 key 最多只可能存在於其中一個檔案裡,只需對那一個檔案執行上述的查詢流程即可。
Log-structured storage 因為 RockDB 的出現而變得相當常見,但也有一些問題 :
- Write Amplification : 當我們寫入一個資料時,實際上會寫入多次,譬如說合併 SSTable
- Compaction Overhead : 壓縮會佔用大量的 CPU 跟 IO 資源
Index-organized Storage
不管是 tuple-oriented storage 還是 log-structured storage,都需要透過 index 來進行查詢。 在 index-organized storage 中,我們會將 tuple 當成 index 中的值,並且使用類似 slot page 的方式來儲存,同時依據 key 來進行排序。
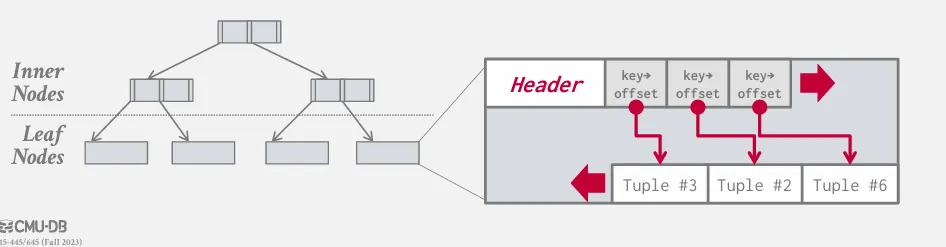
Tuple Layout
在 tuple-oriented storage 中,tuple 也是由 header 和 data 兩個部分組成。
DBMS 會將每個 tuple 設定一個 id 代表他在資料庫中的具體位置,通常是由 page_id + offset/slot 組合而成,如 PostgreSQL 中的 ctid。
-- postgres 16
CREATE TABLE test (id INT, name VARCHAR(10));
INSERT INTO test VALUES (1, 'a'), (2, 'b'), (3, 'c');
SELECT ctid, * FROM test;
-- result
ctid | id | name
-------+----+------
(0,1) | 1 | a
(0,2) | 2 | b
(0,3) | 3 | c
(3 rows)
-- ctid 代表 (page, slot) 的位置,如 (0,1) 代表 page 0 的第一個 slot
DELETE FROM test WHERE id = 2;
SELECT ctid, * FROM test;
-- result
ctid | id | name
-------+----+------
(0,1) | 1 | a
(0,3) | 3 | c
(2 rows)
-- 可以看到 id = 2 的 tuple 被刪除了,但 id = 3 的 ctid 仍然是 (0,3)
INSERT INTO test VALUES (2, 'b');
SELECT ctid, * FROM test;
-- result
ctid | id | name
-------+----+------
(0,1) | 1 | a
(0,3) | 3 | c
(0,4) | 2 | b
(3 rows)
-- 可以看到 id = 2 的 ctid 是 (0,4)
VACUUM FULL test;
SELECT ctid, * FROM test;
-- result
ctid | id | name
-------+----+------
(0,1) | 1 | a
(0,2) | 3 | c
(0,3) | 2 | b
(3 rows)
-- 執行 VACUUM FULL 之後,ctid 會重新排序
Tuple Header
header 中會包含一些 metadata,像是 :
- Bitmap for NULL columns (哪些欄位是 NULL)
- Transaction information (transaction id, visibility information)
Tuple Data
DBMS 需要保證這些資料是對齊的,以免出現一些非預期的行為並且提升存取效率。
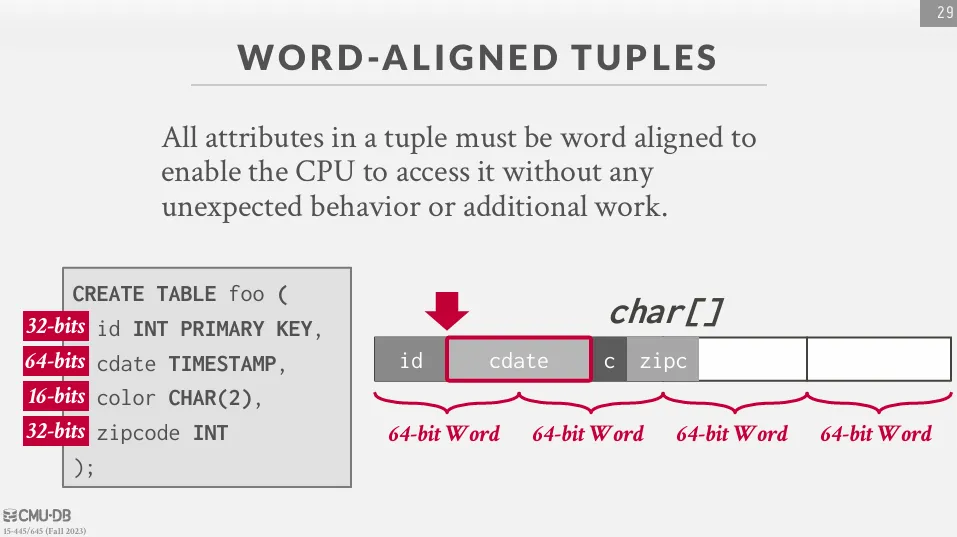
一般來說,如果讀到邊界的資料,會依據電腦的架構有不同的處理方式 :
- Perform Extra Reads : 執行兩次讀取並且合併
- Random Reads : 隨機返回不正確的結果
- Reject : 拒絕讀取
要處理這個問題,有兩種解決方式 :
- Padding
- Reordering
Padding
在每個 tuple 的後面加上 padding,使其對齊。
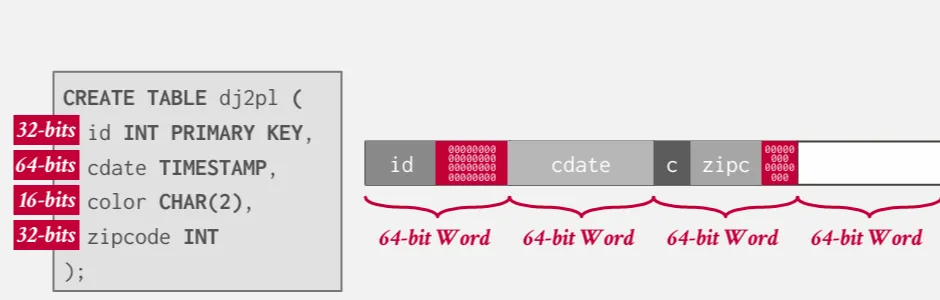
Reordering
將資料重新排序 (可能需要再填充),使其對齊。
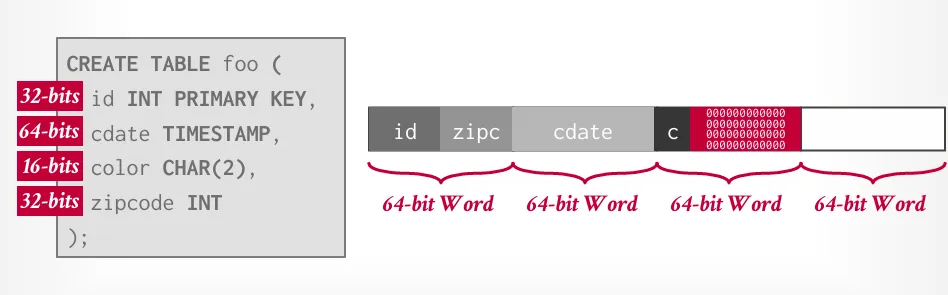
Data Representation
最後就來介紹不同的資料型態是如何被儲存的。

Integer
使用 C/C++ 原生的 type 來表示,是固定長度的。
如 INTEGER、BIGINT、SMALLINT、TINYINT
Variable Precision Number
同樣使用 C/C++ 原生的 type 來表示,也是固定長度,但是跟 C/C++ 一樣,會遇到精確度的問題,如 FLOAT、DOUBLE。
#include <stdio.h>
int main(int argc, char* argv[]) {
float x = 0.1;
float y = 0.2;
printf("x+y = %.20f\n", x+y)
printf("0.3 = %.20f\n", 0.3)
}
// =>
// x+y = 0.30000001192092895508
// 0.3 = 0.29999999999999998890
Fixed Precision Number
如果需要精確的數字,可以使用 fixed precision number,但是在計算上會比較慢,通常每個 DBMS 都會自己實作 (如加減法和儲存方式),所需的空間會依照精確度而有所不同,如 NUMERIC、DECIMAL。
// postgresql NUMERIC
typedef unsigned char NumericDigit;
typedef struct {
int ndigits; // # of Digits
int weight; // Weight of 1st Digit
int scale; // Scale Factor
int sign; // Positive/Negative/NaN
NumericDigit * digits; // Digit Storage
} numeric;
NULL Data Type
有三個常見的方式來表示 NULL :
- NULL column bitmap header : 在 header 中有一個 bitmap 來表示哪些 column 是 NULL (最常見)
- Special value : 用一個特殊的值來表示 NULL 如 INT32_MIN
- Per attribute NULL flag : 在每一個屬性前加入一個 flag 來表示是否為 NULL,會破壞 alignment (非常少見)
Large Value
大多數 DBMS 不支援大於 page size 的 tuple,所以我們必須將資料儲存在獨立的 overflow / toast page,並且在 tuple 中儲存一個 pointer 指向這個 page。

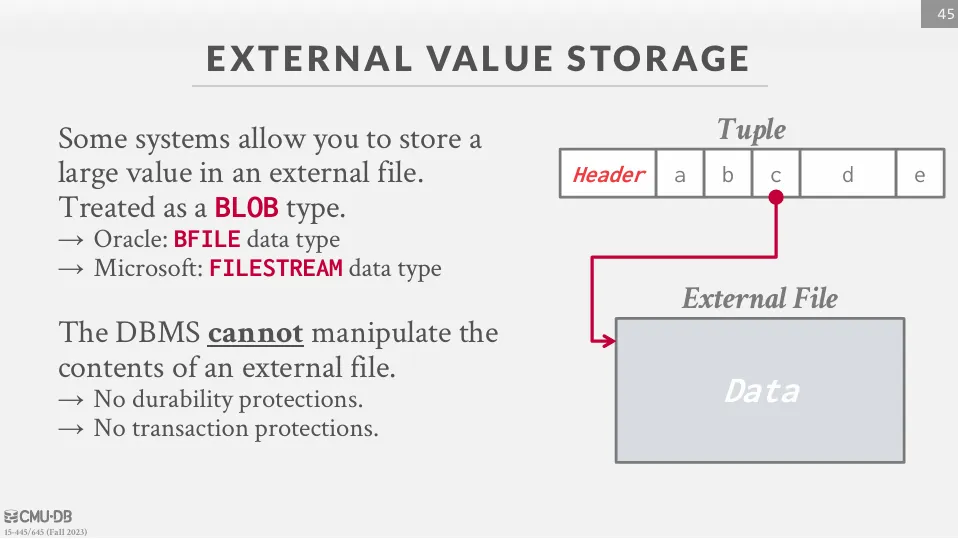
External Value Store
有些資料庫可以存取外部的檔案,這些檔案會被放在本地的路徑並儲存 URL,資料庫不能做任何更改,也不保證 transaction。