Modern SQL
這篇筆記會簡單介紹常見的 SQL 語法。
SQL History
SQL 最早由 IBM 在 1970 年代初期開發,並於 1986 年成為 ANSI 標準,隨後在 1987 年被 ISO 採用。 自那時以來,SQL 標準經歷了多次修訂和擴展,主要的更新包括 :
- SQL:1999 Regular expressions, Triggers
- SQL:2003 XML, Windows, Sequences
- SQL:2008 Truncation, Fancy sorting
- SQL:2011 Temporal DBs, Pipelined DML
- SQL:2016 JSON, Polymorphic tables
- SQL:2023 Property Graph Queries, Muti-Dim. Arrays
Relational Languages
在 1969 年,Ted Codd 提出了 Relational Model,其核心目標是讓資料庫使用者能以高階語言操作資料,而不需要理解底層的物理儲存方式。 要實現這個模型,就需要一套專門的 "語言" 來描述資料的存取與操作方式,這些語言的總稱就是 Relational Languages。
Relational Languages 可以分為兩大類,分別是 Relational Algebra 與 Relational Calculus。
Relational Algebra 是一種程序性語言 (Procedural Language),使用者需要明確指定如何 (How) 獲取資料的步驟。 Relational Calculus 則是一種宣告式語言 (Non-Procedural Language),使用者只需描述想要什麼 (What) 資料,由系統自行決定最佳的執行計畫。
SQL 就是綜合了這兩種模式的語言,它在語法上是宣告式的,但在系統內部,查詢通常會被轉換為關聯代數運算,進而生成最佳化的執行計畫。
與理論不同的是,SQL 使用的是 bag (multiset) 而非 set,這意味著 SQL 中的結果可以包含重複的資料列。
SQL 可以被細分為幾種子類 :
- DML (Data Manipulation Language) : 查詢、插入、更新、刪除資料,例如 SELECT, INSERT, UPDATE, DELETE
- DDL (Data Definition Language) : 定義 table, view, index 等等,例如 CREATE, ALTER, DROP
- DCL (Data Control Language) : 定義權限 (資安相關),例如 GRANT, REVOKE
- TCL (Transaction Control Language) : 交易控制,例如 COMMIT, ROLLBACK
SQL Syntax
接下來會介紹 SQL 的常用語法,使用的資料表如下 :
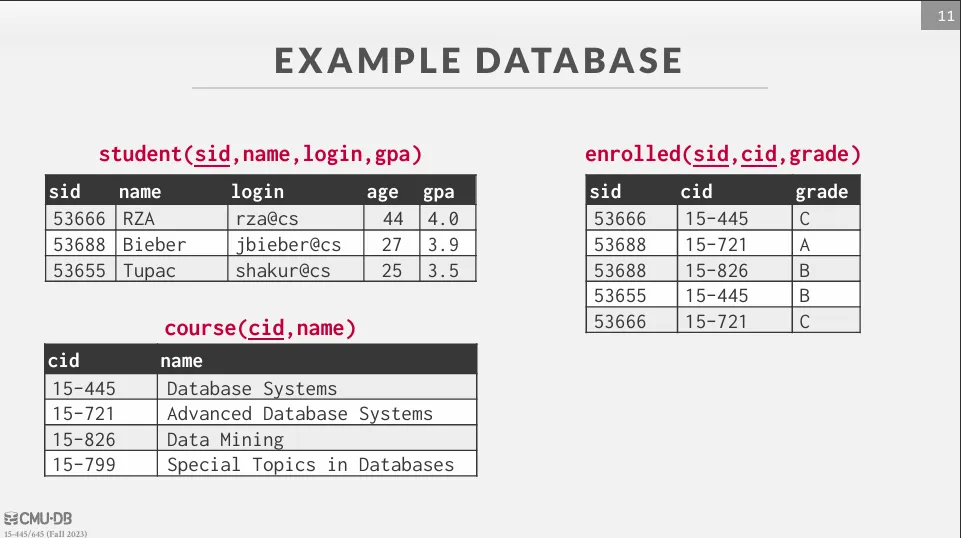
如果想實際操作看看的話,可以使用 Docker 快速建立一個 PostgreSQL 環境,以下的範例也都會以 PostgreSQL 的語法為主。
docker run --name mypg -e POSTGRES_PASSWORD=123456 -p 5432:5432 -d postgres:17
docker exec -it mypg psql -U postgres
接著可以使用以下的 SQL 語法來建立資料表並插入資料 :
CREATE TABLE student(
sid INT PRIMARY KEY,
name VARCHAR(16),
login VARCHAR(32) UNIQUE,
age SMALLINT,
gpa FLOAT
);
CREATE TABLE course(
cid VARCHAR(32) PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
CREATE TABLE enrolled(
sid INT REFERENCES student(sid),
cid VARCHAR(32) REFERENCES course(cid),
grade CHAR(1)
);
INSERT INTO student (sid, name, login, age, gpa) VALUES
(53666, 'RZA', 'rza@cs', 44, 4.0),
(53688, 'Bieber', 'jbieber@cs', 27, 3.9),
(53655, 'Tupac', 'shakur@cs', 25, 3.5),
(53621, 'GZA', 'gza@cs', 54, 3.8);
INSERT INTO course (cid, name) VALUES
('15-445', 'Database Systems'),
('15-721', 'Advanced Database Systems'),
('15-826', 'Data Mining'),
('15-799', 'Special Topics in Databases'),
('15-999', 'Non-Database Course');
INSERT INTO enrolled (sid, cid, grade) VALUES
(53666, '15-445', 'C'),
(53688, '15-721', 'A'),
(53688, '15-826', 'B'),
(53655, '15-445', 'B'),
(53666, '15-721', 'C');
Joins
可以用於連接兩張 table,並且可以依據不同的條件來連接。
Inner Join
只回傳兩個資料表中,連接欄位皆能匹配上的資料列 :
-- 找出所有有修課的學生以及他們修的課程
SELECT s.name, e.cid
FROM student AS s
JOIN enrolled AS e ON s.sid = e.sid;
-- equivalent to
SELECT s.name, e.cid
FROM student AS s
INNER JOIN enrolled AS e ON s.sid = e.sid;
-- name | cid
-- --------+--------
-- RZA | 15-445
-- Bieber | 15-721
-- Bieber | 15-826
-- Tupac | 15-445
-- RZA | 15-721
Left Join
回傳左邊資料表的所有資料列,右邊資料表中連接欄位能匹配上的資料列,若無法匹配則以 NULL 補足 :
-- 找出所有學生以及他們修的課程 (若無修課則顯示 NULL)
SELECT s.name, e.cid
FROM student AS s
LEFT JOIN enrolled AS e ON s.sid = e.sid;
-- name | cid
-- --------+--------
-- RZA | 15-445
-- Bieber | 15-721
-- Bieber | 15-826
-- Tupac | 15-445
-- RZA | 15-721
-- GZA |
Right Join
回傳右邊資料表的所有資料列,左邊資料表中連接欄位能匹配上的資料列,若無法匹配則以 NULL 補足 :
-- 找出所有課程以及修這些課程的學生 (若無學生修課則顯示 NULL)
SELECT c.cid, e.sid
FROM enrolled AS e
RIGHT JOIN course AS c ON e.cid = c.cid;
-- cid | sid
-- --------+-------
-- 15-445 | 53666
-- 15-721 | 53688
-- 15-826 | 53688
-- 15-445 | 53655
-- 15-721 | 53666
-- 15-999 |
-- 15-799 |
Full Join
回傳兩個資料表的聯集,兩邊資料表中連接欄位能匹配上的資料列,若無法匹配則以 NULL 補足 :
-- 找出所有學生以及有選過的課程 (若無修課或沒被選過則顯示 NULL)
SELECT s.name, e.cid
FROM student AS s
FULL JOIN enrolled AS e ON s.sid = e.sid;
-- name | cid
-- --------+--------
-- RZA | 15-445
-- Bieber | 15-721
-- Bieber | 15-826
-- Tupac | 15-445
-- RZA | 15-721
-- GZA |
Cross Join
回傳兩個資料表的笛卡兒積 (Cartesian Product) :
-- 找出所有學生以及所有課程的組合
SELECT s.name, c.cid
FROM student AS s
CROSS JOIN course AS c;
-- name | cid
-- --------+--------
-- RZA | 15-445
-- RZA | 15-721
-- RZA | 15-826
-- RZA | 15-799
-- RZA | 15-999
-- Bieber | 15-445
-- Bieber | 15-721
-- Bieber | 15-826
-- Bieber | 15-799
-- Bieber | 15-999
-- Tupac | 15-445
-- Tupac | 15-721
-- Tupac | 15-826
-- Tupac | 15-799
-- Tupac | 15-999
-- GZA | 15-445
-- GZA | 15-721
-- GZA | 15-826
-- GZA | 15-799
-- GZA | 15-999
Aggregates
常見的包括 COUNT, SUM, AVG, MIN, MAX 等等 :
-- 計算 login 以 '@cs' 結尾的學生人數,只算 login 欄位不為 NULL 的資料列
SELECT COUNT(login) AS cnt
FROM student
WHERE login LIKE '%@cs';
-- 也可以使用 COUNT(*) 或 COUNT(1),但會將所有資料列都算進去 (包含 NULL)
SELECT COUNT(*) AS cnt
FROM student
WHERE login LIKE '%@cs';
SELECT COUNT(1) AS cnt
FROM student
WHERE login LIKE '%@cs';
Aggregates function 不能與其他欄位同時出現在 SELECT 子句中,因此下面的寫法是錯誤的 :
-- 計算每門課的平均 GPA
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e
JOIN student AS s ON e.sid = s.sid;
-- ERROR: column "e.cid" must appear in the GROUP BY clause or be used in an aggregate function
-- LINE 1: SELECT AVG(s.gpa), e.cid
需要使用 GROUP BY 子句來解決這個問題,所有非聚合函數的欄位都必須出現在 GROUP BY 子句中 :
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e JOIN student AS s
ON e.sid = s.sid
GROUP BY e.cid;
如果要過濾的話,可以使用 HAVING 子句 :
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e JOIN student AS s
ON e.sid = s.sid
GROUP BY e.cid
HAVING AVG(s.gpa) > 3.8;
String Operations
不同的資料庫有不同的比較字串以及大小寫的方式,具體如下圖所示 :

也可以在 LIKE 中使用 % 或 _ 來進行字串比較,% 代表任意長度的字串 (包括空字串),_ 代表任意單一字元 :
SELECT *
FROM enrolled AS e
WHERE e.cid LIKE '15-%';
-- sid | cid | grade
-- -------+--------+-------
-- 53666 | 15-445 | C
-- 53688 | 15-721 | A
-- 53688 | 15-826 | B
-- 53655 | 15-445 | B
-- 53666 | 15-721 | C
SELECT *
FROM student AS s
WHERE s.login LIKE '%@c_';
-- sid | name | login | age | gpa
-- -------+--------+------------+-----+-----
-- 53666 | RZA | rza@cs | 44 | 4
-- 53688 | Bieber | jbieber@cs | 27 | 3.9
-- 53655 | Tupac | shakur@cs | 25 | 3.5
-- 53621 | GZA | gza@cs | 54 | 3.8
PostgreSQL 也提供了很多字串處理的函數,例如 LENGTH, SUBSTRING, LOWER, UPPER, TRIM, CONCAT 等等 :
SELECT LENGTH(name) AS len, SUBSTRING(name FROM 1 FOR 2) AS sub
FROM student;
-- len | sub
-- -----+-----
-- 3 | RZ
-- 6 | Bi
-- 5 | Tu
-- 3 | GZ
SELECT LOWER(name) AS lower_name, UPPER(name) AS upper_name
FROM student
WHERE name IN ('rza', 'Bieber', 'tupac', 'GZA');
-- lower_name | upper_name
-- ------------+------------
-- bieber | BIEBER
-- gza | GZA
Date and Time
不同的 DBMS 差異非常大,所以需要依據不同的 DBMS 來撰寫 SQL 語法 :
SELECT NOW();
-- now
-- -------------------------------
-- 2025-09-07 00:54:17.279466+00
SELECT CURRENT_TIMESTAMP;
-- current_timestamp
-- -------------------------------
-- 2025-09-07 00:54:23.033652+00
SELECT CAST('2023-08-01' AS DATE) - CAST('2023-01-02' AS DATE) AS diff;
-- diff
-- ------
-- 211
Output Redirection
可以將查詢結果儲存到另一張已經存在且有相同欄位結構的 table 中 :
SELECT DISTINCT cid
INTO TEMPORARY CourseIds
FROM enrolled;
也可以用於 insert 語句中,將查詢結果插入到另一張 table 中 :
INSERT INTO CourseIds (cid)
(SELECT DISTINCT cid FROM enrolled);
Output Control
可以使用 ORDER BY 子句來排序查詢結果,語法為 ORDER BY <column*> [ASC|DESC],預設為 ASC,可以依據多個欄位進行排序 :
SELECT sid FROM enrolled
WHERE cid = '15-721'
ORDER BY grade DESC, sid ASC;
也可以使用 LIMIT 子句來限制查詢結果的數量,語法為 LIMIT <number> [OFFSET <number>],其中 OFFSET 用於跳過前面的資料列 :
SELECT * FROM student
ORDER BY sid
LIMIT 1 OFFSET 1;
還有一種使用 FETCH 的方法,語法如下 (WITH TIES 會將相同的資料列全部取出) :
-- 將學生依照 GPA 由低到高排序,跳過前 10 名,並取出接下來的 10 名,如果有並列的話也會全部取出
SELECT sid, name
FROM student
WHERE login LIKE '%@cs'
ORDER BY gpa
OFFSET 1 ROWS
FETCH FIRST 2 ROWS WITH TIES;
Window Functions
在 SQL 的早期,我們主要用 聚合函數搭配 GROUP BY 來做統計,例如:
SELECT cid, AVG(CASE grade
WHEN 'A' THEN 4
WHEN 'B' THEN 3
WHEN 'C' THEN 2
ELSE 0 END) AS avg_gpa
FROM enrolled
GROUP BY cid;
-- cid | avg_gpa
-- --------+--------------------
-- 15-445 | 2.5000000000000000
-- 15-826 | 3.0000000000000000
-- 15-721 | 3.0000000000000000
這樣能計算每門課的平均分數,但問題在於 :
- 結果會壓縮資料列。例如上面,輸出只有課程跟平均分數,無法同時保留學生個別資料。
- 無法在同一查詢中,同時看到個人資訊與群體統計。如果要查每個學生的分數,還有他在課程中的平均,就得寫子查詢或 join,語法冗長。
因此,為了解決這些問題,SQL 引入了 Window Functions (視窗函數)。
SELECT e.sid, s.name, e.cid, e.grade,
AVG(CASE grade
WHEN 'A' THEN 4
WHEN 'B' THEN 3
WHEN 'C' THEN 2
ELSE 0 END)
OVER (PARTITION BY e.cid) AS avg_gpa
FROM enrolled e
JOIN student s ON e.sid = s.sid;
-- sid | name | cid | grade | avg_gpa
-- -------+--------+--------+-------+--------------------
-- 53666 | RZA | 15-445 | C | 2.5000000000000000
-- 53655 | Tupac | 15-445 | B | 2.5000000000000000
-- 53688 | Bieber | 15-721 | A | 3.0000000000000000
-- 53666 | RZA | 15-721 | C | 3.0000000000000000
-- 53688 | Bieber | 15-826 | B | 3.0000000000000000
這樣就能在同一查詢中,同時看到個人資訊與群體統計。
除了一般的聚合函數,常見的視窗函數還有 RANK, DENSE_RANK, ROW_NUMBER 等等。
-- 每門課的成績排名
SELECT e.cid, s.name, e.grade,
RANK() OVER (
PARTITION BY e.cid
ORDER BY CASE e.grade
WHEN 'A' THEN 4
WHEN 'B' THEN 3
WHEN 'C' THEN 2
ELSE 0 END DESC
) AS rank_in_course
FROM enrolled e
JOIN student s ON e.sid = s.sid;
-- cid | name | grade | rank_in_course
-- --------+--------+-------+----------------
-- 15-445 | Tupac | B | 1
-- 15-445 | RZA | C | 2
-- 15-721 | Bieber | A | 1
-- 15-721 | RZA | C | 2
-- 15-826 | Bieber | B | 1
Nested Queries
在一個查詢中嵌套另一個查詢,內層查詢會先被執行,然後將結果傳遞給外層查詢。
可以支持 NOT、IN、ANY、ALL、EXISTS 等等。
-- 找出有修課的學生
SELECT s.sid, s.name
FROM student AS s
WHERE EXISTS (
SELECT 1
FROM enrolled AS e
WHERE e.sid = s.sid
);
-- sid | name
-- -------+--------
-- 53666 | RZA
-- 53688 | Bieber
-- 53655 | Tupac
除此之外也可以使用 LATERAL 來進行查詢,LATERAL 會依據外層查詢的每一列來執行內層查詢 :
-- 找出每門課的修課人數以及平均 GPA
SELECT *
FROM course AS c,
LATERAL (
SELECT COUNT(*) AS cnt
FROM enrolled AS e
WHERE e.cid = c.cid
) AS t1,
LATERAL (
SELECT AVG(gpa) AS avg
FROM student AS s
JOIN enrolled AS e ON s.sid = e.sid
WHERE e.cid = c.cid
) AS t2;
-- cid | name | cnt | avg
-- --------+-----------------------------+-----+------
-- 15-445 | Database Systems | 2 | 3.75
-- 15-721 | Advanced Database Systems | 2 | 3.95
-- 15-826 | Data Mining | 1 | 3.9
-- 15-799 | Special Topics in Databases | 0 |
-- 15-999 | Non-Database Course | 0 |
Common Table Expressions
CTE 是 SQL 提供的一種語法機制,用來在一個查詢中定義臨時的結果,可以在後續的主查詢中重複使用,提供可讀性並且支援遞迴查詢。
-- 使用 CTE 計算每門課的平均 GPA
WITH course_avg AS (
SELECT e.cid, AVG(s.gpa) AS avg_gpa
FROM enrolled e
JOIN student s ON e.sid = s.sid
GROUP BY e.cid
)
SELECT c.cid, c.name, ca.avg_gpa
FROM course c
JOIN course_avg ca ON c.cid = ca.cid;
CTE 也可以支援遞迴查詢 (Recursive CTE),例如計算階乘 :
WITH RECURSIVE factorial(n, fact) AS (
SELECT 0 AS n, 1 AS fact
UNION ALL
SELECT n + 1, (n + 1) * fact
FROM factorial
WHERE n < 5
)
SELECT * FROM factorial;
-- n | fact
-- ---+------
-- 0 | 1
-- 1 | 1
-- 2 | 2
-- 3 | 6
-- 4 | 24
-- 5 | 120