Relational Model & Algebra
這篇筆記主要介紹資料庫的基本概念,包含資料庫系統的歷史、資料模型、以及關係模型與關係代數。
Database System
首先,讓我們先了解一下什麼是資料庫 (Database) 以及為什麼我們需要資料庫系統 (DBMS) :
- 資料庫 (Database) : 有組織的、相互關聯的資料集合,用於對現實世界進行建模,如一個數位音樂商店的歌曲、專輯、藝術家等資料
- 資料庫管理系統 (Database Management System) : 管理資料庫的軟體系統,如 MySQL、PostgreSQL、SQLite、MongoDB 等等
接下來,我們來看一個沒有使用 DBMS 的例子來了解為什麼我們需要 DBMS。
假設有一個 Spotify 的工程師需要儲存作家和專輯的訊息,他可能會將資料儲存下面這兩個檔案 :
"Wu-Tang Clan",1992,"USA"
"Notorious BIG",1992,"USA"
"GZA",1990,"USA"
"Enter the Wu-Tang","Wu-Tang Clan",1993
"St.Ides Mix Tape","Wu-Tang Clan",1994
"Liquid Swords","GZA",1990
如果他想要查詢 GZA 在哪一年首發了專輯,可以這樣做 :
for line in file.readlines():
record = parse(line)
if record[0] == "GZA":
print(int(record[1]))
但是這樣做會遇到一些問題,例如 :
- 資料完整性 (Data Integrity):如何保證專輯的作者一定存在於 artists.csv? 如果有人將年份寫成無效的字串怎麼辦? 如果一張專輯有多個作者呢?
- 實作複雜度 (Implementation):如何快速找到特定紀錄? 如果兩個程式同時寫入同一個檔案怎麼辦?
- 持久性 (Durability):如果在寫入檔案的過程中機器當機了,如何保證資料不會損毀?
- 抽象層缺失 (Abstraction):應用程式的程式碼與資料的物理儲存方式 (如 CSV 格式) 緊密耦合。如果想把分隔符號從逗號改成 tab,所有應用程式都得修改。
為了解決這些問題,我們需要一個資料庫管理系統 (DBMS) 來幫助我們管理資料。
DBMS
DBMS 是一個通用軟體,它允許應用程式根據特定的資料模型來定義、創建、查詢、更新和管理資料庫。
- 資料模型 (Data Model) : 一套抽象規則,用於描述資料的結構、關係與約束。它決定能如何表達資料與操作資料。
- 綱要 (Schema) : 基於某一資料模型,對特定資料集合的具體描述。它定義了資料庫的結構 (例如表格、欄位、鍵、索引)。
其中, 資料模型有很多種,常見的有以下幾種 :
- Relational (本課程的主要資料模型)
- NoSQL (key-value、graph、document、column)
- Array / Matrix / Vector (machine learning)
- Hierarchical / Network / Multi-Value (old)
Relational Model
早期的 DBMS,邏輯層 (描述資料庫有哪些實體和屬性) 和物理層 (描述這些資料如何被實際儲存) 是緊密耦合的。 這意味著應用程式開發者必須了解資料的底層儲存細節。 如果資料庫管理員想改變資料的儲存方式 (例如從 Hash Map 改成 B-Tree 以支援範圍查詢),就必須修改所有應用程式的程式碼。
IBM 的研究員 Ted Codd 在 1969 年發現了以上這個問題後,提出了關係模型 (Relational Model),核心目標是資料獨立性,即將邏輯層和物理層分離。
關聯式模型包含三個關鍵概念 :
- 結構 (Structure) : 將所有資料都看作是關係 (Relation)。
- 完整性 (Integrity) : 透過約束 (Constraints) 來確保資料庫內容的正確性。
- 操作 (Manipulation) : 提供一套高階語言介面來存取和修改資料。
並主要由以下幾個基本要素組成 :
- 關係 (Relation) : 一個包含多個元組 (Tuple) 的 無序集合。可以將其視為一張資料表 (Table)。
- 元組 (Tuple) : 關係中的一筆紀錄,代表一個實體。可以視為資料表中的一列 (Row)。
- 屬性 (Attribute) : 元組中的一個值,描述實體的某個特徵。可以視為資料表中的一欄 (Column)。
- 主鍵 (Primary Key) : 一個或一組屬性,其值能唯一標識關係中的每一個元組。
- 外鍵 (Foreign Key) : 一個或一組屬性,其值參照到另一個關係中的主鍵,用於建立兩個關係之間的連結。
Document Model
Document Model 的資料庫會將資料儲存為文件形式,並以 hierarchical 的 key-value pair 來表示資料。 文件的欄位值可以是數字、字串、陣列,或者是嵌套的文件,這種類型的資料庫最常使用的方式是 JSON 格式,而舊系統則可能使用 XML 或自訂的物件表示。
常見的 Document Model 資料庫有 MongoDB、CouchDB 等等。

Vector Model
Vector Model 的資料庫是一種專門處理高維度向量 (如由機器學習模型生成的嵌入向量) 而設計的資料庫系統,可以有效執行 Nearest Neighbor 搜尋,適合用於如近似語義搜尋、推薦系統等應用。
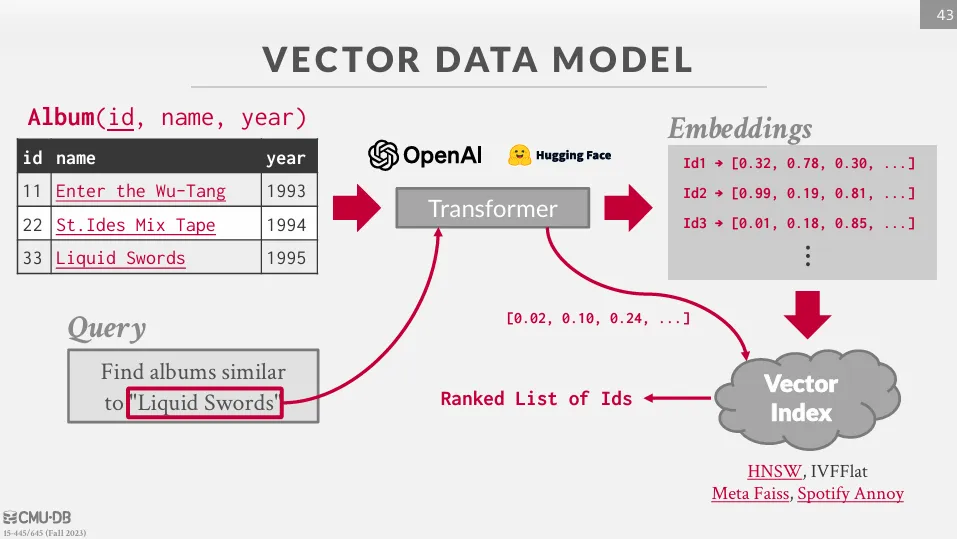
DML (Data Manipulation Language)
DML 是用來操作資料庫中資料的語言,主要分為兩種 :
- 程序性語言 (Procedural) : 使用者明確指定如何 (How) 獲取資料的步驟。例如指定使用迴圈來遍歷資料。
- 宣告式語言 (Non-Procedural / Declarative) : 使用者只描述想要什麼 (What) 資料,由 DBMS 自行決定最佳的執行計畫。
Relational Algebra
關聯式代數是一套對關係進行操作的基礎運算子集合。每個運算子都接受一或多個關係作為輸入,並產生一個新的關係作為輸出。
- 選擇 (Selection, ) : 選出滿足特定條件的元組 (過濾 Rows)。
SELECT * FROM R WHERE predicate;
- 投影 (Projection, ) : 選出特定的屬性 (選擇 Columns)。
SELECT A1, A2 FROM R;
- 聯集 (Union, ) : 回傳兩個關係中所有的元組 (會自動去重)。兩個關係必須有相同的屬性。
(SELECT * FROM R) UNION (SELECT * FROM S);
- 交集 (Intersection, ) : 回傳同時存在於兩個關係中的元組。
(SELECT * FROM R) INTERSECT (SELECT * FROM S);
- 差集 (Difference, -) : 回傳存在於第一個關係但不存在於第二個關係的元組。
(SELECT * FROM R) EXCEPT (SELECT * FROM S);
- 積 (Product, ) : 將兩個關係的元組進行所有可能的組合。
(SELECT * FROM R) CROSS JOIN S;
- 連接 (Join, ) : 根據共同屬性的值,將兩個關係的元組組合起來。這是最常用也最重要的操作之一。
SELECT * FROM R JOIN S ON R.key = S.key;