Design a URL Shortener like TinyURL
Background
TinyURL 是一個網址縮短服務,使用者可以輸入一個長網址並得到一個短網址,當其他使用者訪問這個短網址時,會被重定向到原始的長網址。
舉例來說,使用者可以將 https://www.example.com/some/very/long/url 丟給 TinyURL,TinyURL 會回傳一個短網址 https://tinyurl.com/abc123,當其他人訪問這個短網址時,會被重定向到 https://www.example.com/some/very/long/url。
Requirements
Functional Requirements
- 使用者可以提交一個長網址並獲得一個對應的短網址
- 使用者可以通過短網址來被重定向到原始的長網址
- 短網址預設會在 3 年後過期
使用者可以設定過期時間使用者可以刪除短網址使用者可以自訂短網址的別名可以提供統計資訊,如點擊次數或是使用者的地理位置分布
本文將專注於短網址的核心功能,也就是生成短網址並進行重定向,其他的功能不在本文的討論範圍內。
Non-Functional Requirements
- 重定向需要確保低延遲 (< 100ms)
- 高可用性 (可用性 > 一致性)
- 可擴展性,可以處理 100M DAU
- 保證短網址的唯一性,不會有一個短網址對應到多個長網址
The Set up
Back of the Envelope Estimation
Assumptions
- 100M DAU
- 每日產生 5M 個短網址
- 讀寫比例 100:1
QPS
- 每秒平均寫入請求數: 5M / 86400 ≈ 58 (writes/sec)
- 每秒平均讀取請求數: 58 * 100 = 5800 (reads/sec)
- 高峰期流量假設為平均的 5 倍: 29000 (reads/sec), 290 (writes/sec)
Storage
- 長網址: 150 bytes
- 短網址: 20 bytes
- 使用者 ID: 16 bytes
- 創建時間戳: 8 bytes
- 過期時間戳: 8 bytes
- 索引和其他開銷: 100 bytes
從上述估算可得每條紀錄約 300 bytes。
- 每日產生的短網址數量: 5M
- 每日儲存空間需求: 5M * 300B = 1.5GB
- 3 年的儲存空間需求: 1.5GB * 365 * 3 = 1.6TB
Bandwidth
兩隻 API 的請求大小差距不大,假設每次請求輸入輸出大小均為 500 bytes (包含 HTTP headers) :
- Ingress: (58 + 5800) * 500 bytes * 8 (bits/byte) ≈ 23 Mbps
- Egress: 同上 ≈ 23 Mbps
即使是在高峰期 (115 Mbps),這樣的頻寬需求對於現代的系統來說並不是瓶頸。
Cache
使用 in-memory 的資料庫快取最熱門的 10% 短網址,並假設每個短網址的資料大小約 200 bytes (short_url -> long_url) :
- 需要快取的短網址數量: 5M * 365 * 3 * 10% = 547.5M
- 需要的記憶體大小: 547.5M * 200B = 109.5GB
Schema Design
這裡只針對 URL 的部分來設計 schema,不考慮如使用者、權限等其他功能。
- url_mapping
- short_url
- long_url
- user_id
- created_at
- expiry_date
API Design
1. Create Short URL
建立新的短網址
POST /api/urls
{
"long_url": "https://www.example.com/some/very/long/url",
"custom_alias": "optional-custom-alias",
"expiry_date": "optional-expiry-date"
}
Response: HTTP 200 OK
{
"short_url": "https://tinyurl.com/abc123"
}
2. Redirect to Long URL
重定向到長網址
GET /{short_url}
Response: HTTP 301 Moved Permanently
Location: https://www.example.com/some/very/long/url
這裡的 HTTP status code 有兩種選擇 :
- 301 Moved Permanently: 表示這個重定向是永久性的,瀏覽器跟搜尋引擎都會將這個短網址記錄下來
- 302 Found: 表示這個重定向是臨時性的,每次訪問短網址都會需要重新發送請求到伺服器
對於短網址服務來說,乍看之下由於會有過期時間且有時候需要蒐集點擊次數等統計資訊,似乎選擇 302 是比較合理的選擇。
但以 TinyURL 為例,它是使用 301 搭配 Cache-Control: max-age=0, must-revalidate, no-cache, no-store, private 來忽略瀏覽器的快取,這樣就能夠同時達到 SEO 跟統計資訊的需求。
Cache-Control 的設定可以參考 MDN Web Docs :
- max-age=N: 表示回應可以被快取 N 秒
- must-revalidate: 表示在快取過期後,必須重新向服務器驗證資源是否有更新,需要搭配 ETag 或是 Last-Modified 使用
- no-cache: 表示回應可以被快取,但使用前必須先向服務器驗證資源是否有更新
- no-store: 表示回應不能被任何快取儲存
- public / private: public 表示回應可以被任何快取 (如 CDN) 儲存,private 表示回應只能被瀏覽器的快取儲存
TinyURL 採取的做法可能是為了讓很舊的瀏覽器也能正確忽略快取,因此使用了很多功能重複的指令,實際上應該只需要 no-store 就可以達到同樣的效果。
也有一些其他的短網址服務使用 302,兩種做法都是可以的。
High-Level Design
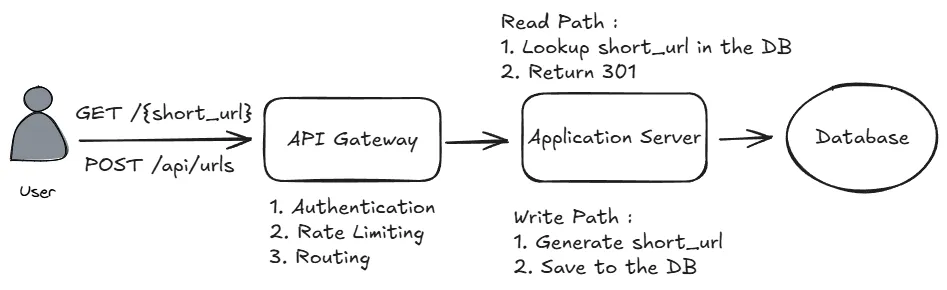
API Gateway: 負責處理所有進入的請求,可以做負載均衡依據路由把請求導向不同的服務,同時也能處理登入驗證跟流量控制Application Server: 負責處理業務邏輯,包含生成短網址以及查找長網址Database: 用於儲存資料,這裡會使用關聯式資料庫 (PostgreSQL) 來儲存 URL 資料
User should be able to create a short URL
- 使用者呼叫
POST /api/urls並提交長網址 - 驗證長網址是否符合 url 格式
- 生成唯一的短網址
- 將長網址和短網址儲存到資料庫中
User should be able to access the original URL by using the short URL
- 使用者訪問短網址並呼叫
GET /{short_url} - 查詢資料庫並獲取對應的長網址
- 如果有找到並且沒有過期,返回 301 重定向到長網址
Deep Dives
How to generate a unique short URL?
在設計短網址的生成方法時,需要考慮以下幾點 :
- 短網址的唯一性
- 長度盡可能短
- 生成短網址的速度要快
常見的做法是先產生一個唯一的 ID,然後對這個 ID 進行編碼 (encoding) 來生成短網址。
對於如何產生唯一的 ID,有幾種方法 :
- Hash Functions
- Counter
- Any unique ID generation algorithm (e.g. Snowflake、UUID)
- Random Generation
而對於編碼方式,常見的選擇是 Base62 或 Base58,因為 Base64 中的 + 和 / 是特殊字符,需要做 URL encoding,會增加短網址的長度。
- Base64: 使用 A-Z, a-z, 0-9, +, / 共 64 個字符
- Base62: 使用 A-Z, a-z, 0-9 共 62 個字符
- Base58: 使用 A-Z, a-z, 1-9 (去除容易混淆的 0, O, I, l) 共 58 個字符
假設使用 Base62 編碼,代表 :
- 如果是 5 個字元的短網址,總共有 62^5 ≈ 9 億種組合,約 30 bits
- 如果是 6 個字元的短網址,總共有 62^6 ≈ 568 億種組合,約 36 bits
- 如果是 7 個字元的短網址,總共有 62^7 ≈ 3.5 兆種組合,約 42 bits
每日產生 5M 個短網址,3 年下來大約是 5M * 365 * 3 = 5.5B 個短網址,因此最好使用 6-7 個字元來確保不容易碰撞。
如果是使用 hash function 的話,就需要特別注意碰撞的機率問題。
假設資料庫中已經有 50 億個短網址且使用 6 個字元,現在要再生成一個新的短網址,碰撞的機率大約是 50 億 / 568 億 ≈ 9%,這個機率看起來不高,但如果每天都產生 5M 個短網址,那麼一天就會有大約 450000 個短網址會碰撞。
Option 1: Hash Function
常見的哈希函數有 MD5、SHA256 等等,其中 MD5 會產生 128 bits 的哈希值,SHA256 則會產生 256 bits 的哈希值。
我們可以使用 SHA256 並加入一個密碼來生成一個無法被預測的哈希值,再將這個值進行 Base62 編碼,最後取前 7 個字符作為短網址。
但這樣同樣會產生問題,即使我們使用了碰撞機率極低的哈希函數,但因為我們需要截斷,所以仍然有可能會產生碰撞,並且如果使用者輸入相同的長網址,就必定會產生相同的短網址,這不是我們想要的行為。
要解決碰撞問題,可以採取以下幾種策略 :
- Unique Constraint: 在資料庫中對短網址欄位設置唯一約束,這樣當插入一個已存在的短網址時會產生錯誤,系統可以捕捉這個錯誤並重新生成短網址
- Nonce / Salt: 在生成短網址時加入一個隨機的 nonce 或是 salt,這樣即使使用者輸入相同的長網址,也會產生不同的短網址
- Retry: 如果產生的短網址已經存在,可以嘗試加入不同的 nonce 或是 salt 並重新生成,直到重試的次數達到上限
import hashlib
import os
def generate_short_url(long_url, secret_key, nonce=None):
if nonce is None:
nonce = os.urandom(8).hex()
input_data = f"{long_url}{secret_key}{nonce}"
hash_object = hashlib.sha256(input_data.encode())
hash_hex = hash_object.hexdigest()
base62_chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
base62 = ""
num = int(hash_hex, 16)
while num > 0:
num, rem = divmod(num, 62)
base62 = base62_chars[rem] + base62
short_code = base62[:7]
return short_code, nonce
secret = "my-secret-key"
short_code, nonce = generate_short_url("https://github.com/", secret)
print(f"short_code: {short_code}, nonce: {nonce}")
# Output: short_code: l6H1MFB, nonce: a0039d516f604c19
Option 2: Counter
第二種方法是使用一個全局的計數器,每次有新的長網址時,計數器就加 1,然後將這個計數器的值進行 Base62 編碼來生成短網址,這樣就可以確保生成的數字是唯一且不會碰撞的。
這裡的實作有幾種不同的方法 :
- 使用 Redis 的
INCR命令來實現全局計數器,這個命令是原子操作,能夠保證在高併發的情況下不會產生重複的值 - 使用機器 ID 搭配計數器,這樣每台機器都有自己的計數器,並且在生成短網址時會將機器 ID 加入到計數器的值中,這樣就能夠確保不同機器生成的短網址不會重複
第一種方法的缺點是所有的 application server 都需要連接到同一個 Redis 節點來取得計數器的值,這會導致跨區域的延遲成為一個重要的問題,舉例來說,從臺灣打到美國西岸的 EC2 伺服器,網路延遲大概是 200ms 左右。
解決方案有幾種,一種是不要使用中心化的單一 Redis cluster,而是在不同區域都部屬節點來降低跨區延遲,另一種方式是一次性跟 redis 獲取多個值 (如 1000 個),然後在本地使用這些值來生成短網址,這樣就能夠大幅降低跨區延遲的影響。
第二種做法的缺點是要思考機器 ID 的分配方式,由於本地的計數器通常會放在記憶體中,因此需要保證機器 ID 要是唯一的,需要其他方法來維護這個性質。
這兩種方法的優點同樣非常明顯,他們都能保證生成的短網址是不會碰撞的,所以速度相對來說會更快。
Option 3: UUID / Snowflake
目前來說,比較常見的 UUID 版本大致有以下幾種 :
- UUIDv1: 60 bits 的時間戳 (自 1582 年以來的 100ns 數) + 48 bits 的 MAC address
- UUIDv4: 122 bits 的隨機數
- UUIDv7: 使用 48 bits 的時間戳 (自 1970 年以來的毫秒數) 加上 74 bits 的隨機數來生成 UUID
而 Snowflake 則是 Twitter 提出的分散式 ID 生成演算法,使用 1 bit 的符號位 1 + 41 bits 的時間戳 (自某個時間點以來的毫秒數) + 10 bits 的機器 ID + 12 bits 的序列號來生成 64 bits 的整數 ID。
這類型的 ID 生成演算法都有一個共同的缺點是,生成的 ID 通常比較長,如果使用截斷的話就會產生各種碰撞的問題,變成不如直接使用 hash function 或是使用 random generation 來得好。
Option 4: Random Generation
最後一個方法就是直接使用隨機數來生成短網址。
import random
import string
def generate_short_url(length):
characters = string.ascii_letters + string.digits
short_url = ''.join(random.choice(characters) for _ in range(length))
return short_url
short_code = generate_short_url(7)
print(f"short_code: {short_code}")
# Output: short_code: aZ3bX9K
這個方法的優點是簡單且不需要額外的基礎設施 (如 Redis),缺點跟使用 hash function 類似,會有碰撞的機率問題。 並且程式語言內建的隨機數生成器通常熵 (entropy) 不夠,因此碰撞的機率可能會比預期的高。
How to ensure low latency?
對於 read-heavy 的系統來說,有幾種常見的優化手段 :
- Database Indexing
- Caching
- CDN and Edge Servers
Database Indexing
由於這裡的 SQL 查詢主要是 point search (根據 short_url 查找 long_url),在 short_url 欄位上建立索引可以大幅提升查詢速度。
SELECT long_url
FROM url_mapping
WHERE short_url = 'abc123';
以 PostgreSQL 為例,可以使用 hash index 來進一步提升查詢速度。
CREATE INDEX idx_short_url ON url_mapping USING HASH (short_url);
Caching
以前面估計的 QPS 來看 (29000 r/s, 290 w/s),單單引入索引不足以應付這樣的讀取量。
由於讀寫比例高達 100:1,且資料一旦寫入後通常不會再更改,因此很適合使用 cache (如 Redis) 來快取熱門的短網址,減少對資料庫的讀取壓力。
對於一般的 RDBMS (PostgreSQL、MySQL) 來說,在簡單的查詢下單個資料庫節點大約能處理 1000 writes/sec 或 3000 reads/sec 左右的請求。
而對於像 Redis 這樣的 in-memory 資料庫,簡單的 GET / SET 操作在單個節點上可以輕鬆達到 100000 req/sec 以上的處理能力。
引入快取雖然可以提升效能,但也會帶來可用性與一致性上的挑戰。 為了提升可用性,可以使用 Redis Cluster 或其他 Redis 高可用方案。
而在快取的使用上則可以採用 cache aside pattern :
- 讀取時先查快取,若快取未命中再查資料庫並將結果寫入快取
- 寫入時先更新資料庫,並採用 lazy write 的方式更新快取 (不立即更新快取,等到下一次讀取時再更新)
同時因為記憶體的大小有限,可以使用 LRU 搭配 TTL 來移除較少使用或過期的資料。
CDN and Edge Servers
除了快取之外,還可以使用 CDN (Content Delivery Network) 來將熱門的查詢放在離使用者更近的邊緣節點 (Edge Servers)。
以短網址系統來說,我認為 CDN 的必要性不是特別大,而且會造成額外的成本,因此這部分可以視情況而定。 如果要使用 CDN 的話還需要額外考慮到快取失效的問題。
How to handle expired data?
為了避免資料量不斷膨脹,因此我們需要定期清除過期的資料來保證資料庫的大小在可控範圍內。
這裡有幾種做法 :
- 將資料依據
expiry_date進行 partitioning,並定期刪除整個 partition - 使用批次工作 (batch job) 來定期刪除過期資料
針對第一種方式,由於主要的查詢是針對 short_url 進行 point search,因此如果用 expiry_date 來做 partitioning,會導致查詢時需要掃描多個 partition,進而影響查詢效能。
因此需要使用第二種方式來定期刪除過期資料。
由於一次使用 DELETE * FROM url_mapping WHERE expiry_date < now() 來刪除過期資料會對資料庫造成很大的負擔,因此可以在低峰時段使用批次工作來分批刪除過期資料。
可以使用行級鎖搭配 FOR UPDATE SKIP LOCKED 來啟動多個 worker 同時刪除過期資料 :
With candidates AS (
SELECT short_url
FROM url_mapping
WHERE expiry_date < now()
LIMIT 100
FOR UPDATE SKIP LOCKED
)
DELETE FROM url_mapping
USING candidates
WHERE url_mapping.short_url = candidates.short_url;
特別注意由於有使用 cache,因此在刪除資料時也需要同時刪除快取中的資料。
How to scale up to support 100M DAU?
以短網址系統來說,主要的瓶頸可能會出現在資料庫上,這裡有幾個點需要注意 :
- 讀寫的 QPS 吞吐量是否足夠
- 內部的儲存空間是否足夠
Read/Write Throughput
以資料庫的寫入量來說 (290 w/s),單一節點應該是足夠的,但讀取量 (29000 r/s) 就需要特別注意。
假設快取可以處理 90% 的讀取請求,那麼實際上資料庫需要處理的讀取請求大約是 2900 r/s,這對於單一資料庫節點來說壓力稍微有點大。
對於這樣的情況,最好的解決方法就是採用 read replica 的方式來分散讀取的負載,可以把主資料庫的內容同步到多個從資料庫節點,並且將讀取請求分散到這些從節點上。 以前面估計的值來說,可以把寫入請求都導向主節點,而讀取請求則可以分散到 2-3 個從節點上,這樣每個從節點大約只需要處理 1000 r/s 的請求。
Storage
以目前所需的儲存空間來說 (1.6TB/3y),對於現代的資料庫不是特別大的問題,但問題在於這個資料量對於單一表來說非常大,進而影響到查詢效能。
假設系統需要保存 3 年的資料,代表資料庫需要保存 5M * 365 * 3 = 5.5B 行的資料在單一的表中,這會產生如索引過大、查詢效能下降的問題,因此需要進行 partitioning 來將資料分散到多個表中,以減少單一表的大小。
以這裡的情境來說,對 short_url 做 hashing 來決定資料要存放在哪一個 partition 是一個不錯的選擇,可以保證每次查詢都只需要查詢一個 partition。
Final Design
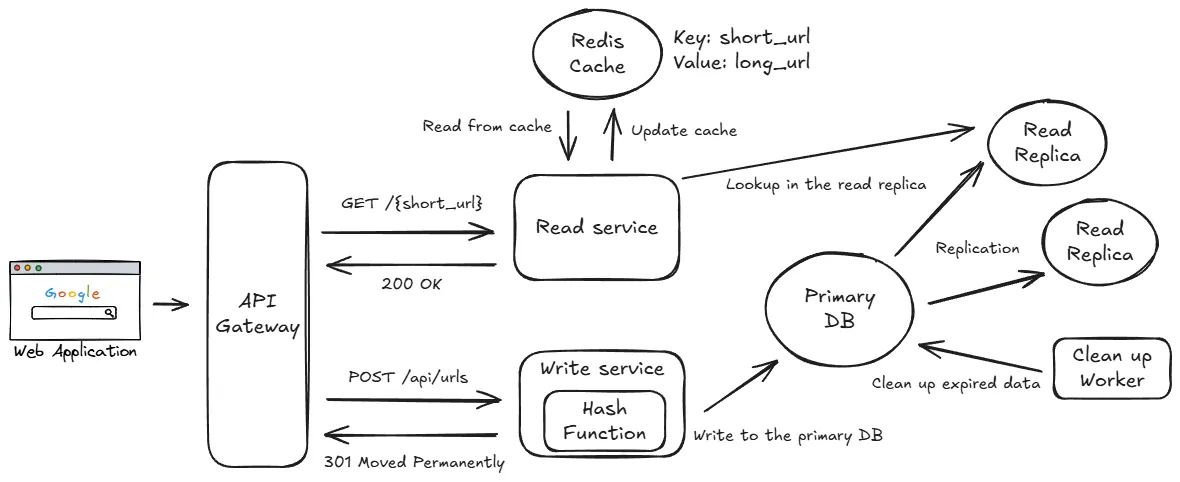
我認為生成短網址的方案中,選擇使用哈希函數跟計數器都是合理的選擇,前者實作較為簡單,後者則能保證不會碰撞。