Design a Cloud Storage Service like Dropbox
Background
Dropbox / Google Drive 是一種雲端儲存服務,允許使用者上傳各種類型的檔案,包括文件、圖片、影片等,並與其他使用者分享這些檔案,還能夠在不同的裝置上進行檔案同步,確保使用者在任何地方都能夠存取最新版本的檔案。
Requirements
Functional Requirements
- 使用者可以在任何裝置上傳跟下載檔案
- 使用者可以跟其他人分享檔案
- 檔案可以自動同步到其他的設備並處理衝突
- 可以離線修改檔案,並在重新連線後自動同步
- 系統能存取過去 30 天內的檔案版本
針對不同檔案 / 資料夾可以設定不同的權限
Non-Functional Requirements
- 高可用性 (可用性 > 一致性)
- 可以支持超大檔案上傳 (> 10GB)
- 可靠性,檔案一旦上傳就不會遺失
- 低延遲,下載 / 上傳檔案的延遲盡可能低
- 可擴展性,可以支持大量使用者
安全性,檔案應該被加密
The Set up
Back of the Envelope Estimation
Assumptions
- 100M DAU
- 每個使用者平均每天上傳 10 個檔案
- 每個檔案平均大小 10MB
- 讀寫比例 1:1
QPS
- 每秒平均寫入 / 讀取請求數: (100M * 10) / 86400 = 11754
- 高峰期假設是平均的 5 倍: 11754 * 5 = 58770
Storage
- 每天上傳的資料量: 100M * 10 * 10MB = 10PB
- 每年上傳的資料量: 10PB * 365 = 3.65EB
Bandwidth
- 每天需要的頻寬: 10PB
- 每秒的上傳 / 下載流量: 10PB * 8 / 86400 = 926Gbps
Schema Design
這裡的 item 可以是檔案或資料夾,item_version 用來記錄檔案的不同版本,chunk 用來記錄檔案被切成的多個 chunk,shared_file 用來記錄檔案的分享資訊。
- item
- item_id
- owner_id
- namespace_id
- name
- latest_version
- item_type (file / folder)
- parent_item_id (null if root)
- item_version
- item_id
- version_number
- namespace_id
- chunks (list of chunk checksums)
- status (pending / succeed / failed)
- size (in bytes)
- checksum (SHA256 of the whole file)
- created_at
- chunk
- checksum (SHA256)
- status (pending / succeed / failed)
- size (in bytes)
- access_url (URL to access the chunk in the storage service)
- shared_file
- shared_with_user_id
- item_id
- permissions (e.g., read, write)
- shared_at
除此之外,還需要一個用於儲存變更的表,用來幫助使用者在重新連線後同步檔案。
- file_changes
- change_id
- user_id
- item_id
- version_number
- change_type (created / updated / deleted)
- timestamp
API Design
1. Create Item (File / Folder)
建立新的檔案或資料夾
POST /api/items
{
"name": "file.txt",
"item_type": "file",
"parent_item_id": "folder_123"
}
Response: HTTP 201 Created
{
"item_id": "item_123",
"name": "file.txt",
"item_type": "file",
"parent_item_id": "folder_123",
"owner_id": "user_456",
"latest_version": 1
}
2. Upload File
上傳檔案,檔案會在客戶端被切成多個 chunk 並發送給後端,後端會回傳需要上傳的 chunk 的 pre-signed URL
POST /api/items/{item_id}/upload
{
"base_version": 1,
"size": 10485760,
"chunks": [
{
"checksum": "abc123",
"size": 5242880
},
{
"checksum": "def456",
"size": 5242880
}
]
}
Response: HTTP 200 OK
{
"item_id": "item_123",
"version_number": 2,
"chunks": [
{
"checksum": "abc123",
"upload_url": "https://storage-service.com/upload/abc123"
}
]
}
3. Chunk Upload Completion
每個 chunk 上傳完成後,客戶端會通知後端該 chunk 已經上傳完成
PATCH /api/items/{item_id}/version/{version_number}/chunks/complete
{
"completed_chunks": [
{
"checksum": "abc123",
"status": "succeed"
},
{
"checksum": "def456",
"status": "succeed"
}
]
}
Response: HTTP 200 OK
{
"item_id": "item_123",
"version_number": 2,
"status": "pending",
"chunks": [
{
"checksum": "abc123",
"status": "succeed"
},
{
"checksum": "def456",
"status": "succeed"
}
]
}
4. Get File Metadata
回傳目前最新的可用版本的檔案 metadata,包括版本號、大小、checksum 以及 chunk 狀態
GET /api/items/{item_id}/metadata
Response: HTTP 200 OK
{
"item_id": "item_123",
"version_number": 2,
"size": 10485760,
"checksum": "overall_checksum",
"chunks": [
{
"checksum": "abc123",
"status": "succeed"
},
{
"checksum": "def456",
"status": "succeed"
}
]
}
5. Download File
回傳所有需要的 chunk 的 access URL 以供下載
GET /api/items/{item_id}/versions/{version_number}
{
"chunks": [
"abc123"
]
}
Response: HTTP 200 OK
{
"item_id": "item_123",
"version_number": 2,
"chunk_access_urls": [
{
"checksum": "abc123",
"access_url": "https://storage-service.com/download/abc123"
}
]
}
6. Share File
將檔案分享給其他使用者,並設定權限
POST /api/items/{item_id}/shares
{
"shared_with_user": [
{
"user_id": "user_456",
"permissions": "read"
},
{
"user_id": "user_789",
"permissions": "write"
}
]
}
Response: HTTP 200 OK
{
"item_id": "item_123",
"shared_with_user": [
{
"user_id": "user_456",
"permissions": "read"
},
{
"user_id": "user_789",
"permissions": "write"
}
],
"shared_at": "2023-10-01T12:00:00Z"
}
7. Get History File Metadata
用於請求特定版本檔案的 metadata,包括版本號、大小、checksum 以及 chunk 狀態
GET /api/items/{item_id}/versions/{version_number}/metadata
Response: HTTP 200 OK
{
"item_id": "item_123",
"version_number": 2,
"size": 10485760,
"checksum": "overall_checksum",
"chunks": [
{
"checksum": "abc123",
"status": "succeed"
},
{
"checksum": "def456",
"status": "succeed"
}
]
}
8. Sync Notifications
檢查從上次同步以來的變更
GET /api/sync/changes?since_timestamp=2023-10-01T12:00:00Z
Response: HTTP 200 OK
{
"changes": [
{
"item_id": "item_123",
"version_number": 2,
"change_type": "updated",
"timestamp": "2023-10-01T12:30:00Z"
},
{
"item_id": "item_456",
"version_number": 1,
"change_type": "created",
"timestamp": "2023-10-01T12:45:00Z"
}
]
}
High-Level Design
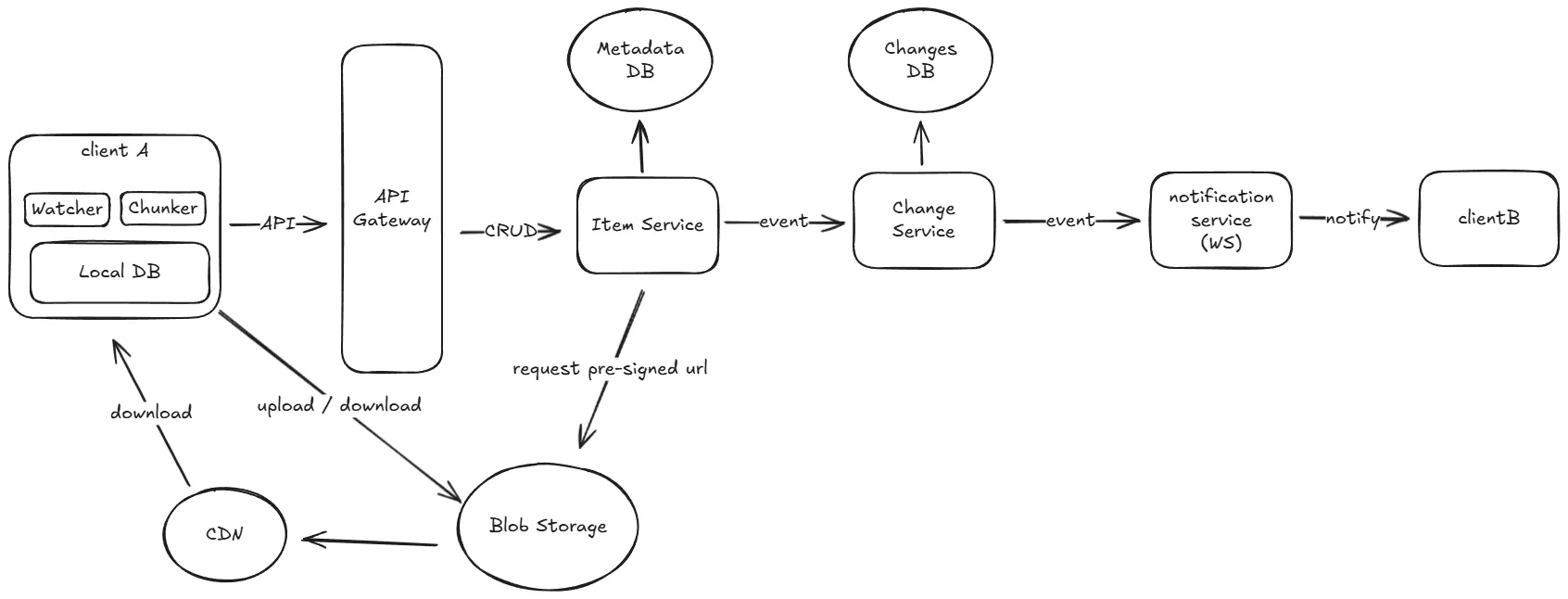
User should be able to upload file from any device
- 客戶端的 chunker 將要上傳的檔案切成多個 chunk
- 如果是新的檔案,客戶端會發送
POST /api/items請求到後端,後端會建立一個新的 item 並回傳 item_id - 接著將所有 chunk 的 checksum 發送到後端,後端會檢查哪些 chunk 已經存在並回傳需要上傳的 chunk 的 pre-signed URL
- 客戶端根據回傳的 pre-signed URL 上傳需要的 chunk 到 blob storage 中
- 一旦有 chunk 上傳完成,客戶端會發送
PATCH /api/items/{item_id}/version/{version_number}/chunks/complete請求到後端,告知後端該 chunk 已經上傳完成 - 後端透過該 chunk 的 checksum 跟 blob storage 進行比對,確保 chunk 上傳正確無誤
- 一旦所有 chunk 都上傳完成,後端會自動判定版本為成功並更新 item 的最新狀態
- 全部都完成後,後端會傳一個訊息給下游的服務,通知有新的檔案版本可以使用
User should be able to download file from any device
- 客戶端發送
GET /api/items/{item_id}/metadata請求到後端拿最新版本的資訊,並檢查那些 chunk 需要下載 - 客戶端發送
GET /api/items/{item_id}/versions/{version_number}請求到後端,後端會回傳需要的 chunk 的 access URL - 客戶端使用 access URL 下載 chunk,並在本地合併成完整的檔案
除此之外,也可以搭配 CDN 來加速下載速度。
User should be able to share file with other users
- 客戶端發送
POST /api/items/{item_id}/shares請求到後端,並設定分享的使用者和權限 - 當被分享的使用者發送請求到後端時,後端會檢查
shared_file表以確定該使用者是否有存取權限
File should be automatically synced to other devices and handle conflicts
檔案同步主要分成兩個方向,本地端變更同步到遠端以及遠端變更同步到本地端。
如果發生衝突的話,應該要在本地創建一個新的版本,並交由使用者來決定要保留哪一個版本。
Local -> Remote
- 客戶端使用 OS 的 API 監控檔案系統的變化 (例如 Linux 的 inotify, Windows 的 FileSystemWatcher, macOS 的 FSEvents)
- 在本地重新切 chunk,並呼叫
PATCH /api/items/{item_id}/versions/{version_number}/chunksAPI 上傳變更的 chunk,後端會檢查衝突並回傳所需的 chunk 的 pre-signed URL - 客戶端使用 pre-signed URL 將 chunk 上傳到 blob storage
- 上傳完成後,客戶端會發送
PATCH /api/items/{item_id}/versions/{version_number}/chunks/complete請求到後端通知 chunk 上傳完成
Remote -> Local
從遠端更新檔案到本地端有幾種常見的方式 :
- Polling: 客戶端持續發送請求到後端,後端會在有新的版本時回傳最新版本
- WebSocket / SSE: 客戶端與後端建立 WebSocket 連線,後端在有新的版本時主動推送通知給客戶端
這裡我認為使用 WS / SSE 會比較好,因為 Polling 的開銷較高,且大部分時間都是空等。 對於 WS 來說,每個連接大約需要消耗 50 KB 的記憶體。
User should be able to access previous versions of files
- 客戶端發送
GET /api/items/{item_id}/versions/{version_number}/metadata請求到後端來拿到特定版本的檔案 metadata - 客戶端發送
GET /api/items/{item_id}/versions/{version_number}請求到後端來拿到需要的 chunk 的 access URL - 客戶端使用 access URL 從 blob storage 下載 chunk,並在本地合併成完整的檔案
Deep Dives
How to support large file upload?
對於大檔案來說,我們可以將它切成多個 chunk,並使用分段上傳的方式來加速上傳流程。
這樣做有幾個好處 :
- 如果上傳到一半的時候斷線了,只需要重新上傳未完成的 chunk 即可
- 可以同時上傳多個 chunk 來提升上傳速度
- 使用者可以隨時掌握上傳進度,對於使用者體驗較好
這裡我們以 AWS S3 為例,S3 提供了 Multipart Upload 的功能,可以讓我們輕鬆地實現分段上傳。
- 客戶端獲取檔案,並決定要切成多大的 chunk 以及總共有幾個 chunk (S3 支援 5MB - 5GB,最多 10,000 個 chunk),並發送 API 告訴後端
- 後端呼叫
CreateMultipartUploadAPI 來得到一個唯一的 upload ID,並為每個 chunk 產生一個 pre-signed URL (預設為 15 分鐘有效),然後回傳給客戶端 - 客戶端使用
UploadPartAPI 上傳每個 chunk 到 S3,並在上傳完成後帶著 partNumber 跟 ETag 回傳給後端 - 當所有 chunk 都上傳完成後,客戶端發送 API 告訴後端所有 chunk 都上傳完成,後端會呼叫
CompleteMultipartUploadAPI 並帶著partNumber跟ETag來驗證並完成整個上傳流程,S3 會自動把所有 chunk 合併成一個完整的檔案 - 如果在上傳過程中發生錯誤,客戶端可以呼叫
AbortMultipartUploadAPI 來取消整個上傳流程,S3 會自動刪除所有已經上傳的 chunk
但使用 Multipart Upload 也有一些問題,就是它會把所有的 chunk 在最後一次性合併,這樣會導致每次修改時都需要重新上傳整個檔案,喪失了使用 chunk 可重複利用的優勢。
Dropbox 採用了自己的儲存系統 Magic Pocket,它完全以 chunk 為單位來儲存檔案,並且可以重複使用已經存在的 chunk。
How to chunk files efficiently?
前面提到,我們會將檔案切成多個 chunk 來上傳,但顯然直接以固定大小來切 chunk 並不是最有效率的分塊方式。 如果使用者在檔案中間插入或刪除了一些資料,這樣會導致後面的所有 chunk 都需要重新上傳。
為了解決這個問題,我們可以使用 Content Defined Chunking (CDC) 的方式來切 chunk,常見的實作是 FastCDC。 CDC 的基本原理是不使用固定大小來切 chunk,而是使用滾動哈希 (rolling hash) 並搭配一些斷點條件來決定 chunk 的邊界。
舉例來說,我們以 64 bytes 來當作我們的 windows,每次讀取一個 byte 就更新一次哈希值 (HASH(b1, b2, ..., b64) -> HASH(b2, ..., b65)),然後檢查哈希值的某些位元是否符合斷點條件 (例如最後 12 bits 全部為 0),如果符合就將目前的資料切成一個 chunk。
這代表 chunk 的平均大小大約是 4KB (2^12),且能保證一次更改最多只會影響到自己或是鄰近的 chunk,大幅減少需要重新上傳的資料量。
How to scaling metadata database?
依據我們的估算,每秒大約有 60k 的讀寫請求,對於一般的關聯式資料庫來說,這樣的負載是非常高的,因此我們需要對資料庫做水平分片 (sharding)。
對於 item 跟 item_version 這兩個表,我們如果簡單的以 owner_id 來做 sharding 的話,可能會導致某些大客戶的所有資料都集中在同一個 shard 上,造成 hotspot。
因此我們需要引入一個額外的欄位 (例如 namespace_id),來進行分片,並建立一個路由的服務來根據 namespace_id 來決定要將請求導向哪一個 shard,並盡量把同一使用者的 namespace_id 綁定到同一個 shard 上,這樣就能減少跨 shard 的查詢。
對於 chunk 表來說,可以考慮要不要把 chunk 綁定到某一個 file 上,這樣就能依據 file_id 來做 sharding,從而確保同一個檔案的 chunk 都在同一個 shard 上,但這樣相對的 chunk 就會比較難以重複使用。
如果覺得這樣不好的話,也可以直接依據 checksum 來做 sharding,只是相對的就需要查詢多個 shard 來取得同一個檔案的所有 chunk。
對於 shared_file 表來說,我認為主要的查詢應該是根據 shared_with_user_id 來查詢有哪些檔案是分享給該使用者的,因此可以依據 shared_with_user_id 來做 sharding。
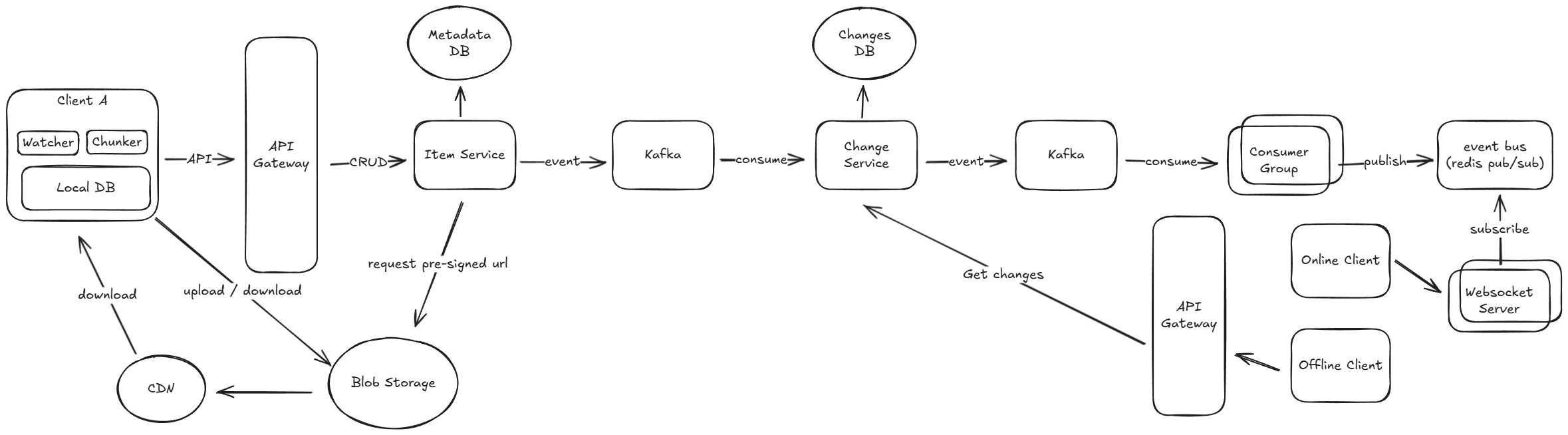
How to scaling file change notification?
讓我們先了解一下整個通知的流程。
當某個檔案發生改變時,item service 會負責將變更的訊息傳送到 kafka 的一個 topic 中,這個訊息會包含有關檔案變更的詳細資訊,例如檔案 ID、版本號、變更的使用者等。
接著下游的 change service 會訂閱這個 topic,並且根據訊息中的資訊來把變更記錄到 file_changes 表中。
對於離線的使用者來說,重新連線時客戶端會發送 GET /api/sync/changes?since_timestamp= 請求到後端,後端會查詢 file_changes 表並回傳有變動的檔案給客戶端,客戶端再根據這些變更來下載最新的檔案版本。
而對於在線的使用者來說,change service 會將變更的訊息發送到 kafka 的另一個 topic 中,這個 topic 會被一個專門負責通知的 consumer group 訂閱,這個 consumer group 會將訊息中的使用者找出來,並且向 redis pub/sub 中發送通知。
{
"event_id": "event_123",
"event_type": "file_updated",
"item_id": "item_123",
"version_number": 2,
"user": ["user_456", "user_789"],
"updated_at": "2023-10-01T12:00:00Z"
}
客戶端會連線到隨機的一台 WebSocket 伺服器,這個伺服器會在記憶體中紀錄所有連線到這台機器的使用者並訂閱 redis pub/sub。 當有新的通知時,伺服器會檢查這個通知的使用者是否有連線到自己這台伺服器,如果有的話就直接發送通知給客戶端。
Final Design
References
- Design Dropbox
- Dropbox System Design
- Design Dropbox/Google Drive
- How to design a personal cloud storage service like Dropbox
- Foundation - Introducing Content Defined Chunking (CDC)
除此之外,Dropbox 官方技術部落格 有非常多的文章可以參考 :