[PG] PostgreSQL Performance Tuning
這篇文章是我看了 PostgreSQL High Performance Tuning Guide 的筆記
Environment Setup
在這篇文章中,我會在 GCP 上面建立一個 VM (Debian) 來安裝 PostgreSQL (15.10) 來做 demo
sudo apt install postgresql
安裝完之後應該會自行啟動,我們可以透過以下指令來確認是否有啟動
sudo systemctl status postgresql
接著我們可以切換使用者並且進入 psql 來進行操作
sudo -i -u postgres
psql
輸入 \q 即可離開 psql
Postgres Architecture
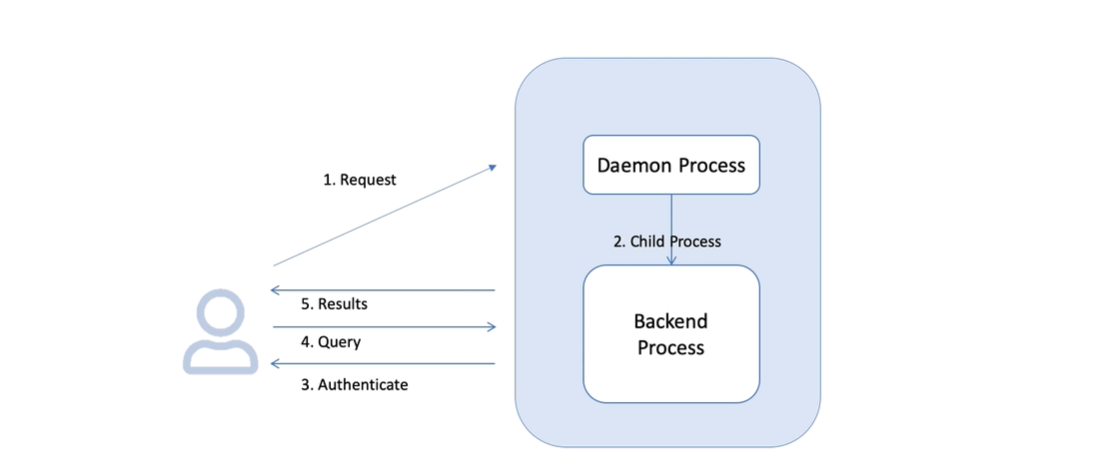
Process manager
PostgreSQL 是 client-server 的架構,client 端可以透過 TCP 連線到 server 端
對於每一個連線,PostgreSQL 都會 fork 一個 process 來處理
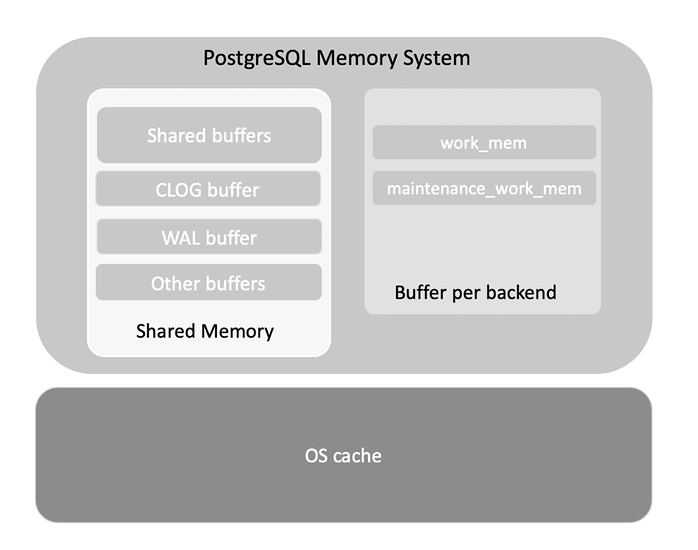
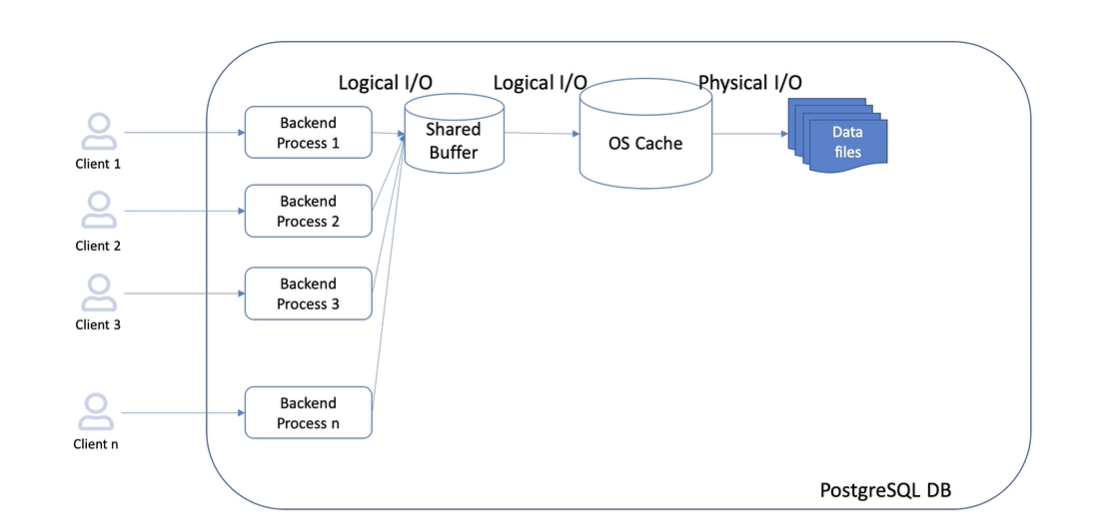
Shared Memory
PostgreSQL 並不會直接讀取硬碟上的資料,而是先嘗試從 shared buffer 中讀取來減少磁碟 I/O 的次數
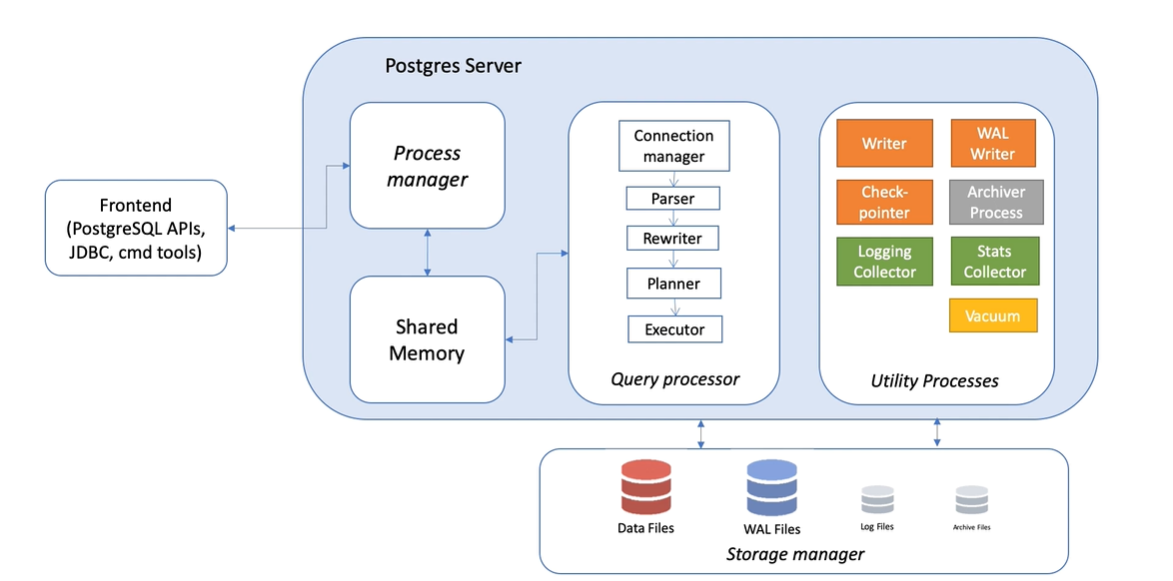
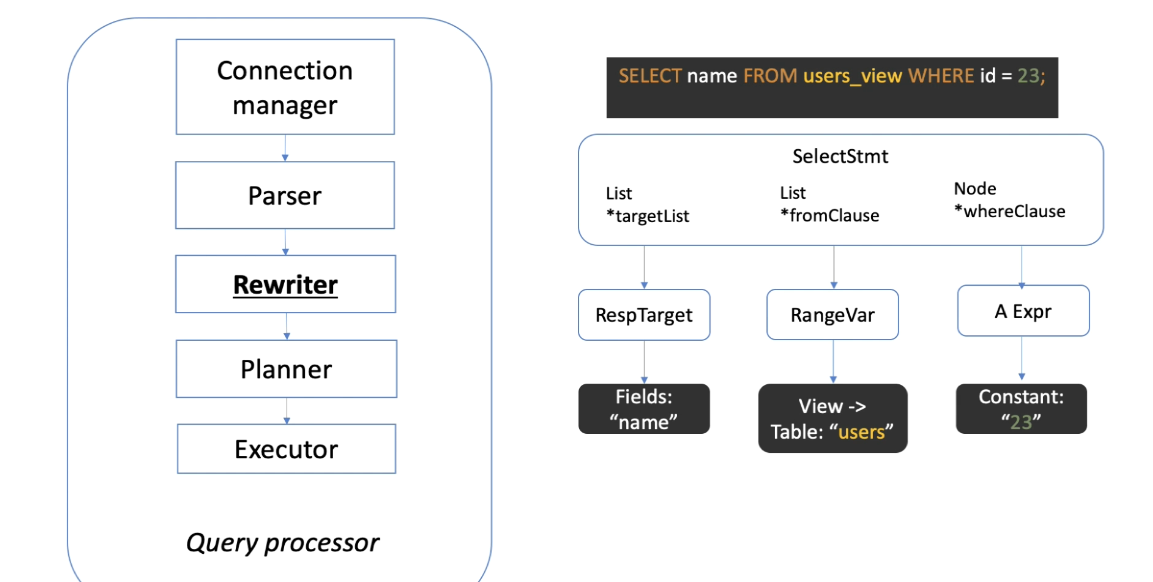
Query processor
Query processor 分為五個步驟 :
- Connection manager : 管理 client 端的連線
- Query parser : 解析 client 端發送的指令
- Query rewriter : 將 view 之類的物件轉換成基本的 SQL 語法
- Query planner : 依據統計資料,選擇最佳的執行計畫
- Query executor : 執行指令
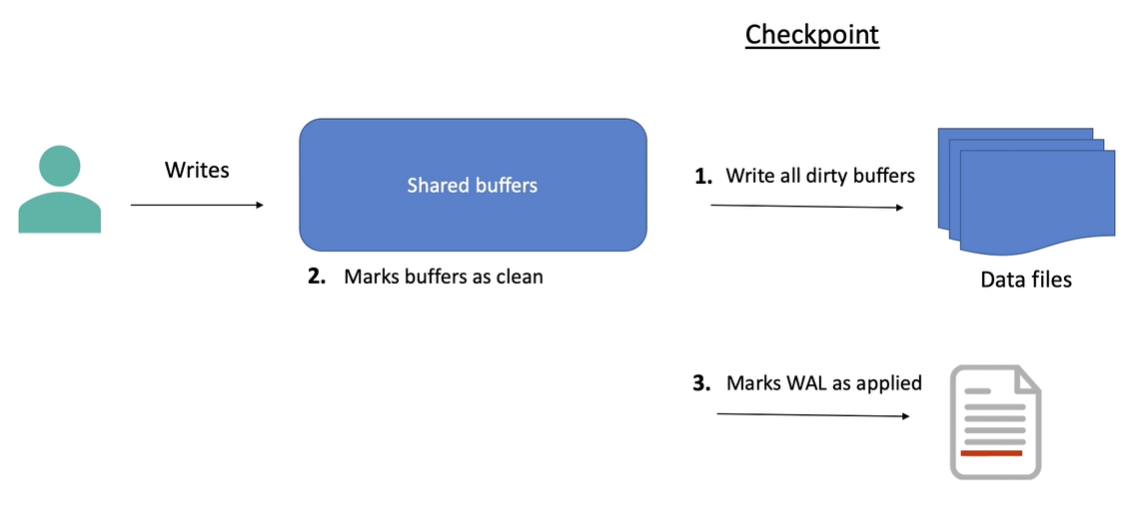
Checkpoint
當要執行 checkpoint 時,會將 shared buffer 中的資料寫入到磁碟上,並且將 shared buffer 和 WAL 中的資料標記為乾淨
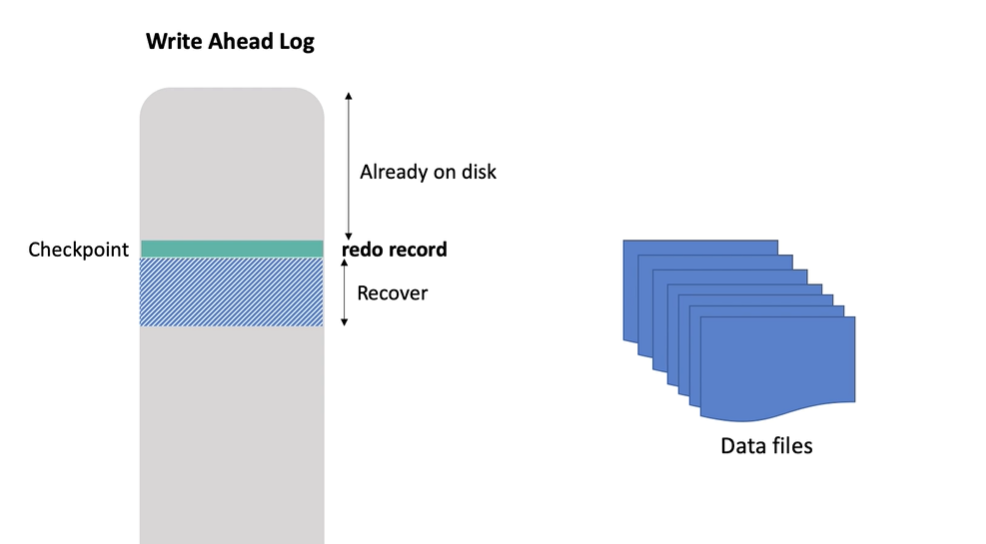
這樣當資料庫出現問題需要 recovery 時,可以從 checkpoint 的位置開始進行 recovery
常見的參數包含以下幾個,可以依據實際的狀況進行調整 :
checkpoint_flush_after: 每寫入多少資料後就進行 flushcheckpoint_timeout: 設定 checkpoint 的時間間隔checkpoint_completion_target: 設定寫入必須在 checkpoint 的幾趴內完成,預設為 0.5
WAL writer
在資料被修改時,會先寫入到 WAL 的 buffer 中,直到被 commit 後才會寫入到磁碟上
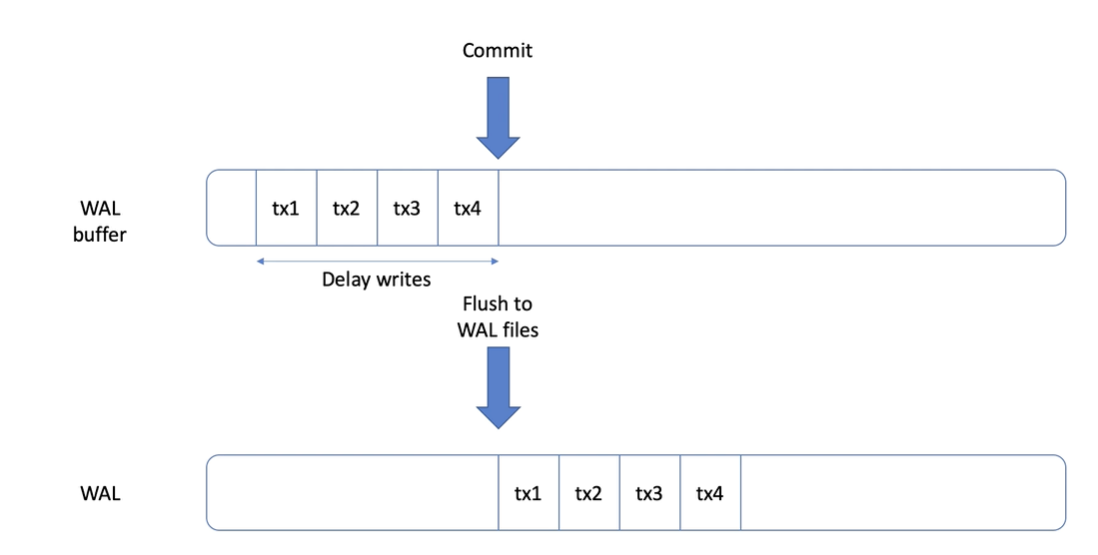
同時,WAL 也會被用來進行 crash recovery 和 replication
Utility process
在 Postgres 中有很多 utility process 會在背景執行,例如 :
Vacuum: 清理 dead tuplesCheckpointer: 執行 checkpointWAL Writer: 紀錄 WAL 的資料Archiver: 將 WAL 中的資料寫入到磁碟Stats Collector: 收集統計資料
Vacuum
在 PostgreSQL 中,如果我們使用 DELETE 或 UPDATE 指令來刪除或修改資料,實際上並不會立即將資料從磁碟上刪除,而是將資料標記為 dead tuples (因為需要在失敗時進行 rollback),這樣的資料會佔用磁碟空間,並且影響查詢效能。
而 VACUUM 指令可以將被標記為已刪除或是過期的 tuple 標記為可重用,這樣當下一次有資料需要寫入時,會覆蓋掉原本的 dead tuples,因此如果我們再次執行 UPDATE,資料表的大小也不會增加
如果我們想要刪除所有 dead tuples,可以執行 VACUUM FULL 指令,
這樣會將整張表的資料重新寫入到硬碟上並且釋放硬碟空間,但是會阻塞其他指令的執行
我們可以透過以下的範例來觀察 VACUUM 的影響 :
首先創建 10 萬筆資料並關閉 autovacuum
CREATE TABLE test (id int) with (autovacuum_enabled = off);
INSERT INTO test SELECT * FROM generate_series(1, 100000);
接著查詢資料表的大小
SELECT pg_size_pretty(pg_relation_size('test'));
-- result
pg_size_pretty
----------------
3544 kB
(1 row)
更新之後再觀察資料表的大小,發現大小大約增加了兩倍
UPDATE test SET id = id + 1;
SELECT pg_size_pretty(pg_relation_size('test'));
-- result
pg_size_pretty
----------------
7080 kB
(1 row)
接著執行 VACUUM 指令,大小並不會減少,而是將 tuple 標記為可重用
VACUUM test;
SELECT pg_size_pretty(pg_relation_size('test'));
-- result
pg_size_pretty
----------------
7080 kB
(1 row)
再執行一次 UPDATE 指令,大小並不會增加,因為覆蓋掉了原本的 dead tuples
UPDATE test SET id = id + 1;
SELECT pg_size_pretty(pg_relation_size('test'));
-- result
pg_size_pretty
----------------
7080 kB
(1 row)
最後執行 VACUUM FULL 指令,大小會縮小到原本的大小
VACUUM FULL test;
SELECT pg_size_pretty(pg_relation_size('test'));
-- result
pg_size_pretty
----------------
3544 kB
(1 row)
如果想要檢查 table 中有多少 dead tuples 可以執行以下指令
SELECT relname, n_live_tup, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'test';
-- result
relname | n_live_tup | n_dead_tup
---------+------------+------------
test | 100000 | 100000
(1 row)
也可以透過以下指令來檢查 VACUUM 的參數
select name,setting
from pg_settings
where name in ('autovacuum_max_workers','autovacuum_naptime','autovacuum_vacuum_scale_factor','autovacuum_vacuum_threshold');
-- result
name | setting
--------------------------------+---------
autovacuum_max_workers | 3
autovacuum_naptime | 60
autovacuum_vacuum_scale_factor | 0.2
autovacuum_vacuum_threshold | 50
(4 rows)
也可以透過調整參數來控制 VACUUM 的行為,例如 :
autovacuum_max_workers: 最大可以同時運行 vacuum 的 process 數量autovacuum_naptime: 每多少秒需要檢查是否需要執行 vacuumautovacuum_vacuum_scale_factor: 決定觸發 vacuum 的條件autovacuum_vacuum_threshold: 決定觸發 vacuum 的條件
而觸發 vacuum 的公式是 : dead tuples > autovacuum_vacuum_scale_factor * tuple count + autovacuum_vacuum_threshold
如果資料量過大,VACUUM 在執行一段時間後就會進入到 delay 的時間,讓其他操作可以執行,假如一直無法完成,就需要去調整 vacuum_cost_delay
Index
Index introduction
索引通常是資料庫效能的瓶頸,因此我們需要適當的建立索引來提高查詢效能
先建立範例資料表
CREATE TABLE test_index (id serial, name text);
INSERT INTO test_index (name) SELECT 'alice' FROM generate_series(1, 2500000);
INSERT INTO test_index (name) SELECT 'bob' FROM generate_series(1, 2500000);
-- 開啟計時
\timing
接著嘗試在沒有索引的情況下進行查詢
EXPLAIN ANALYZE SELECT * FROM test_index WHERE id = 1000000;
-- result
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..43392.60 rows=15606 width=36) (actual time=100.488..103.282 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test_index (cost=0.00..40832.00 rows=6502 width=36) (actual time=72.973..97.820 rows=0 loops=3)
Filter: (id = 1000000)
Rows Removed by Filter: 1666666
Planning Time: 0.286 ms
Execution Time: 103.303 ms
(8 rows)
Time: 104.655 ms
經由上面的查詢計畫可以看到,PostgreSQL 使用兩個 Workers 和 Parallel Seq Scan 來進行查詢
CREATE INDEX idx_id ON test_index (id);
EXPLAIN ANALYZE SELECT * FROM test_index WHERE id = 1000000;
-- result
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Index Scan using idx_id on test_index (cost=0.43..8.45 rows=1 width=9) (actual time=0.653..0.671 rows=1 loops=1)
Index Cond: (id = 1000000)
Planning Time: 1.190 ms
Execution Time: 0.739 ms
(4 rows)
Time: 3.408 ms
可以看到使用 index 之後速度加快了許多, 但是要注意的是 index 會佔用硬碟空間,並且在寫入時會增加額外的開銷, 因此需要觀察 index 和 table 的大小,並且在適當的時機使用索引
\di+
-- result
List of relations
Schema | Name | Type | Owner | Table | Persistence | Access method | Size | Description
--------+----------+-------+----------+------------+-------------+---------------+--------+-------------
public | idx_id | index | postgres | test_index | permanent | btree | 107 MB |
(1 row)
\dt+
-- result
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------+-------+----------+-------------+---------------+--------+-------------
public | test_index | table | postgres | permanent | heap | 192 MB |
(1 row)
Index use case
除了在查詢的時候可以使用 index 來提高查詢性能,在做 join 的時候也可以使用 index 來提高性能, 我們可以在 foreign key 上建立 index , 這樣除了可以提高 join 的效率外, 在 parent table 變動時,也可以提高效能
至於 index 的下法,我們除了針對全表建立 index 外,也可以針對某些特定的值來建立 index (partial index)
CREATE INDEX idx_name_res ON test_index(name) WHERE name not in ('alice', 'bob');
還有一種 index 的模式叫做 combination index,這種 index 可以將多個欄位組合起來建立 index
CREATE INDEX idx_name_res2 ON test_index(name, id);
在上方的範例中,如果我們同時對 name 跟 id 查詢或單獨對 name 查詢,都可以使用到這個 index,但如果只對 id 查詢,就無法使用這個 index
Index cluster
除此之外 correlation 也可以用來提高查詢效能,由於資料的物理位置接近,可以減少 I/O 的次數,進而提高查詢效能
接下來我們透過兩個範例來說明 correlation 的影響 :
CREATE TABLE t_test (id serial, name text);
INSERT INTO t_test (name) SELECT 'alice' FROM generate_series(1, 500000);
CREATE INDEX t_test_idx ON t_test (id);
VACUUM ANALYZE t_test;
EXPLAIN (ANALYZE true, BUFFERS true, TIMING true) SELECT * FROM t_test WHERE id < 10000;
-- result
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Scan using t_test_idx on t_test (cost=0.42..321.59 rows=9324 width=10) (actual time=0.054..1.826 rows=9999 loops=1)
Index Cond: (id < 10000)
Buffers: shared hit=55 read=30
Planning:
Buffers: shared hit=17 read=1
Planning Time: 0.321 ms
Execution Time: 2.325 ms
(7 rows)
Time: 3.179 ms
CREATE TABLE t_random as SELECT * FROM t_test ORDER BY random();
CREATE INDEX t_random_idx ON t_random (id);
VACUUM ANALYZE t_random;
EXPLAIN (ANALYZE true, BUFFERS true, TIMING true) SELECT * FROM t_random WHERE id < 10000;
-- result
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t_random (cost=191.22..3070.30 rows=10167 width=10) (actual time=1.065..3.621 rows=9999 loops=1)
Recheck Cond: (id < 10000)
Heap Blocks: exact=2636
Buffers: shared hit=2636 read=30
-> Bitmap Index Scan on t_random_idx (cost=0.00..188.68 rows=10167 width=0) (actual time=0.789..0.789 rows=9999 loops=1)
Index Cond: (id < 10000)
Buffers: shared read=30
Planning:
Buffers: shared hit=9
Planning Time: 0.095 ms
Execution Time: 4.446 ms
(11 rows)
Time: 4.959 ms
可以看到 Buffer 的 shared hit 相差很多,進而影響了效能
我們可以透過以下的範例來查看 correlation 的數值
SELECT tablename, attname, correlation FROM pg_stats WHERE tablename IN ('t_test', 't_random') ORDER BY 1, 2;
-- result
tablename | attname | correlation
-----------+---------+-------------
t_random | id | 0.012932359
t_random | name | 1
t_test | id | 1
t_test | name | 1
(4 rows)
如果要解決這個問題,我們可以使用 CLUSTER 指令來將資料按照 index 的順序重新排列,來提高查詢效能,
但這個方式會造成鎖表,且只能依據一個 index 來進行排序,並且當新的資料進入時,也不會自動重新排序
CLUSTER t_random USING t_random_idx;
ANALYZE;
SELECT tablename, attname, correlation FROM pg_stats WHERE tablename IN ('t_test', 't_random') ORDER BY 1, 2;
-- result
tablename | attname | correlation
-----------+---------+-------------
t_random | id | 1
t_random | name | 1
t_test | id | 1
t_test | name | 1
在 PostgreSQL 中,有一個參數叫做 fill factor ,預設是 100%, 這個參數會決定 page 被填滿的程度,如果我們將 fill factor 設定為 90%,那麼當 page 被填滿 90% 時, 就不會再寫入新的資料,而是把空間預留給更新和刪除的資料,使之變成 HOT update
我們可以透過以下範例來宣告 fill factor 的值 :
CREATE TABLE test_fillfactor (id serial, name text) WITH (fillfactor = 90);
Statistics
在 PostgreSQL 中,統計資料是非常重要的,它可以幫助我們了解資料庫的狀況,並且提供最佳化的建議。
我們可以透過 pg_stat_statements 來查看統計資料,這個 view 會記錄所有執行的 SQL 語句,並且提供執行時間、執行次數、讀取的資料量等資訊。
首先我們需要啟動這個 extension,我們需要先離開 psql 並創建一個新的資料庫並使用 pgbench 生成一些假資料 :
\q
createdb benchdb
pgbench -i benchdb
接著需要調整 postgresql.conf 來啟動這個 extension
cd /etc/postgresql/15/main
nano postgresql.conf
# change shared_preload_libraries = 'pg_stat_statements'
exit
sudo systemctl restart postgresql
sudo -i -u postgres
psql benchdb
CREATE EXTENSION pg_stat_statements;
\q
pgbench -c 10 -t 10000 benchdb
psql benchdb
\x
接著我們可能需要調整一下顯示方式,輸入 \x 來顯示單行,並查看 pg_stat_statements 的資料
SELECT * FROM pg_stat_statements;
-- result
-[ RECORD 1 ]----------+------------------------------------
userid | 10
dbid | 16411
toplevel | t
queryid | -8553890797533947962
query | CREATE EXTENSION pg_stat_statements
plans | 0
total_plan_time | 0
min_plan_time | 0
max_plan_time | 0
mean_plan_time | 0
stddev_plan_time | 0
calls | 1
total_exec_time | 36.871701
min_exec_time | 36.871701
max_exec_time | 36.871701
mean_exec_time | 36.871701
stddev_exec_time | 0
rows | 0
shared_blks_hit | 2653
shared_blks_read | 131
shared_blks_dirtied | 60
shared_blks_written | 7
local_blks_hit | 0
local_blks_read | 0
local_blks_dirtied | 0
local_blks_written | 0
temp_blks_read | 0
temp_blks_written | 0
--More--
這個 view 會記錄相同的 SQL 語句並生成統計資料 (不同參數算同一語句),我們可以重點注意幾個欄位 :
mean_exec_time: 平均執行時間stddev_exec_time: 執行時間的標準差,可以判斷查詢是否穩定shared_blks_hit: 從 shared buffer 中讀取的資料量shared_blks_read: 從 disk 中讀取的資料量temp_blks_read: 從 temp disk 中讀取的資料量,如果這個數值很大,表示這個查詢可能有 IO 問題temp_blks_written: 寫入 temp disk 的資料量blk_read_time: 讀取 disk 的時間blk_write_time: 寫入 disk 的時間
我們可以使用以下的指令來查詢前 10 個執行時間最長的 SQL 語句 :
SELECT
round((100 * total_exec_time / sum(total_exec_time) OVER ())::numeric, 2) AS percent,
round(total_exec_time::numeric, 2) AS total,
calls,
round(mean_exec_time::numeric, 2) AS mean,
substring(query, 1, 200) AS query
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 10;
除了安裝這個 extension 之外,我們也可以透過系統內建的 pg_stat_sys_table 和 pg_stat_user_table 來查看系統和使用者表的統計資料
psql -d benchdb
SELECT * FROM pg_stat_user_tables;
-- result
-[ RECORD 1 ]-------+------------------------------
relid | 24650
schemaname | public
relname | pgbench_branches
seq_scan | 5296
last_seq_scan | 2024-07-31 03:16:49.550047+00
seq_tup_read | 5296
idx_scan | 59414
last_idx_scan | 2024-07-31 03:16:49.729185+00
idx_tup_fetch | 59414
n_tup_ins | 1
n_tup_upd | 64707
n_tup_del | 0
n_tup_hot_upd | 64424
n_tup_newpage_upd | 283
n_live_tup | 1
n_dead_tup | 19
n_mod_since_analyze | 0
n_ins_since_vacuum | 0
last_vacuum | 2024-07-31 03:16:49.548988+00
last_autovacuum |
last_analyze | 2024-07-31 03:15:09.69068+00
last_autoanalyze | 2024-07-31 03:16:56.637775+00
vacuum_count | 3
autovacuum_count | 0
analyze_count | 1
autoanalyze_count | 1
--More--
我們可以注意一些參數,例如 :
seq_scan: 使用 sequential scan 的次數idx_scan: 使用 index scan 的次數n_live_tup: 表中存活的 tuple 數量n_dead_tup: 被刪除的 tuple 數量
我們可以使用以下提供的 SQL 來幫助我們獲得一些有用的資訊 :
那些 table 使用 index scan 的比例最多
SELECT schemaname,
relname,
seq_scan,
idx_scan,
cast(idx_scan AS numeric) / (idx_scan + seq_scan) AS idx_scan_pct
FROM pg_stat_user_tables
WHERE (idx_scan + seq_scan) > 0
ORDER BY idx_scan_pct;
實際讀取的資料量有多少是從索引獲取的
SELECT relname, seq_tup_read,
idx_tup_fetch,
cast(idx_tup_fetch AS numeric) / (idx_tup_fetch + seq_tup_read) AS idx_tup_pct
FROM pg_stat_user_tables
WHERE (idx_tup_fetch + seq_tup_read) > 0
ORDER BY idx_tup_pct;
可以告訴我們那些表經常進行全表掃描,可能需要建立 index
SELECT schemaname,
relname,
seq_scan,
seq_tup_read,
seq_tup_read / seq_scan AS avg,
idx_scan
FROM pg_stat_user_tables
WHERE seq_scan > 0
ORDER BY seq_tup_read DESC
LIMIT 25;
那些表常常進行寫入,那些表常常進行更新或刪除
SELECT relname,
cast(n_tup_ins AS numeric) / (n_tup_ins + n_tup_upd + n_tup_del) AS ins_pct,
cast(n_tup_upd AS numeric) / (n_tup_ins + n_tup_upd + n_tup_del) AS upd_pct,
cast(n_tup_del AS numeric) / (n_tup_ins + n_tup_upd + n_tup_del) AS del_pct
FROM pg_stat_user_tables
ORDER BY relname;
可以告訴我們那些表常常進行 HOT 更新
SELECT relname,
n_tup_upd,
n_tup_hot_upd,
cast(n_tup_hot_upd AS numeric) / n_tup_upd AS hot_pct
FROM pg_stat_user_tables
WHERE n_tup_upd > 0
ORDER BY hot_pct;
可以告訴我們 index 使用率和大小
SELECT schemaname,
relname,
indexrelname,
idx_scan,
pg_size_pretty(pg_relation_size(indexrelid)) AS idx_size
FROM pg_stat_user_indexes;
可以評估索引的效率,高 avg_tuples 值表示該索引在每次掃描時能夠獲取較多的相關數據
SELECT indexrelname,
cast(idx_tup_read AS numeric) / idx_scan AS avg_tuples,
idx_scan,
idx_tup_read
FROM pg_stat_user_indexes
WHERE idx_scan > 0;
Query Plan
PostgreSQL 提供了四種 scan 的方式,分別是 :
- Seq Scan : 全表掃描
- Index Scan : 索引掃描
- Index Only Scan : 只讀取索引的資料
- Bitmap Scan : 位圖掃描
詳細的說明可以參考 以 PostgreSQL 為例了解資料庫的 Query Plans
在 PostgreSQL 中,我們可以使用 EXPLAIN ANALYZE 指令來查看查詢的執行計劃,這個指令會告訴我們查詢的執行流程,以及每個步驟的執行時間和資料量
EXPLAIN (analyze, verbose, costs, timing, buffers) SELECT * FROM pgbench_tellers;
-- result
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Seq Scan on public.pgbench_tellers (cost=0.00..12.10 rows=10 width=352) (actual time=0.009..0.016 rows=10 loops=1)
Output: tid, bid, tbalance, filler
Buffers: shared hit=12
Query Identifier: 8245021215169886143
Planning Time: 0.038 ms
Execution Time: 0.027 ms
(6 rows)
我們可以注意以下重點 :
Seq Scan on public.pgbench_tellers: 這次使用的是全表掃描cost=0.00..12.10: 第一個數字代表節點前置作業所需的時間 (如果是 index scan,則可能代表定位到第一個索引的時間),第二個數字代表執行完成所預估的時間rows=10: 預估回傳的 row 數量width=352: 每行資料的平均大小actual time=0.009..0.016: 第一個數字代表節點開始處理的時間,第二個數字代表節點處理完成的時間rows=10: 實際回傳的 row 數量loops=1: 執行次數,如果有 join 的話可能會有多次執行Buffers: shared hit=12: 從 shared buffer 中讀取的 page 數量Planning Time: 0.038 ms: 計劃時間Execution Time: 0.027 ms: 執行時間

我們可以依據上面這張圖來計算 query 的 cost,進而產生最好的執行計劃
我們也可以在 PostgreSQL 中使用 pg_class 來查看 table 的相關資訊
SELECT relpages,
current_setting('seq_page_cost') AS seq_page_cost,
relpages * current_setting('seq_page_cost')::decimal AS page_cost,
reltuples,
current_setting('cpu_tuple_cost') AS cpu_tuple_cost,
relpages * current_setting('cpu_tuple_cost')::decimal AS tuple_cost
FROM pg_class
WHERE relname = 'pgbench_tellers';
-- result
relpages | seq_page_cost | page_cost | reltuples | cpu_tuple_cost | tuple_cost
----------+---------------+-----------+-----------+----------------+------------
7 | 1 | 7 | 10 | 0.01 | 0.07
我們也有可能遇到 query plan 估計的值與實際相差很大的情況,例如 :
CREATE TABLE test_estimate as SELECT * FROM generate_series(1, 10000) as id;
EXPLAIN ANALYZE SELECT * FROM test_estimate WHERE cos(id) < 4;
-- result
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Seq Scan on test_estimate (cost=0.00..220.00 rows=3333 width=4) (actual time=0.070..0.924 rows=10000 loops=1)
Filter: (cos((id)::double precision) < '4'::double precision)
Planning Time: 0.792 ms
Execution Time: 1.224 ms
(4 rows)
可以看到估計的 row 跟實際的 row 相差很大,這時候我們可能就需要使用 index 或是其他的手段來解決這個問題
CREATE INDEX idx_test_estimate ON test_estimate (cos(id));
ANALYZE test_estimate;
EXPLAIN ANALYZE SELECT * FROM test_estimate WHERE cos(id) > 4;
-- result
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Seq Scan on test_estimate (cost=0.00..220.00 rows=10000 width=4) (actual time=0.015..1.638 rows=10000 loops=1)
Filter: (cos((id)::double precision) < '4'::double precision)
Planning Time: 0.325 ms
Execution Time: 2.052 ms
(4 rows)
SQL Optimization
Join Order
PostgreSQL 會在 join 的時候嘗試不同的 join order 來找到最優的執行計劃,預設是 8 次,我們可以將其設置為 1 來強制使用手動的 join order
SELECT * FROM pg_settings WHERE name = 'join_collapse_limit';
SET join_collapse_limit = 1;
Avoid SELECT *
減少使用 SELECT *,有機會可以讓 index scan 變成 index only scan
Avoid Order By
由於 PostgreSQL 在執行 order by 的時候,會需要額外開啟一個排序的 buffer, 這樣會導致記憶體使用量增加,進而影響效能,因此我們應該盡量避免使用 order by,但如果有 index 則可以大幅減少這個問題
Avoid Distinct
在使用 distinct 時, PostgreSQL 需要產生一個額外的 Unique node 來處理,因此我們應該盡量避免使用 distinct
Parallel Query
PostgreSQL 可以使用平行的方式來執行 query,這樣可以大幅減少執行時間,可以透過以下指令來查看相關的設定 :
SHOW max_worker_processes;
SHOW max_parallel_workers_per_gather;
Shared Buffer
在不特別針對某個 table 的情況下,我們可以將 shared buffer 設置為 RAM 數量的 25% 左右,這是因為 PostgreSQL 使用了 OS 的 cache,因此不需要將 shared buffer 設置的太大