[Loki] 惡作劇之神 - Loki 解密日誌迷宮
Background
首先來了解一下 Loki 這個工具出現的背景,下圖說明了一般情況下如何用傳統的監控方式進行錯誤分析。
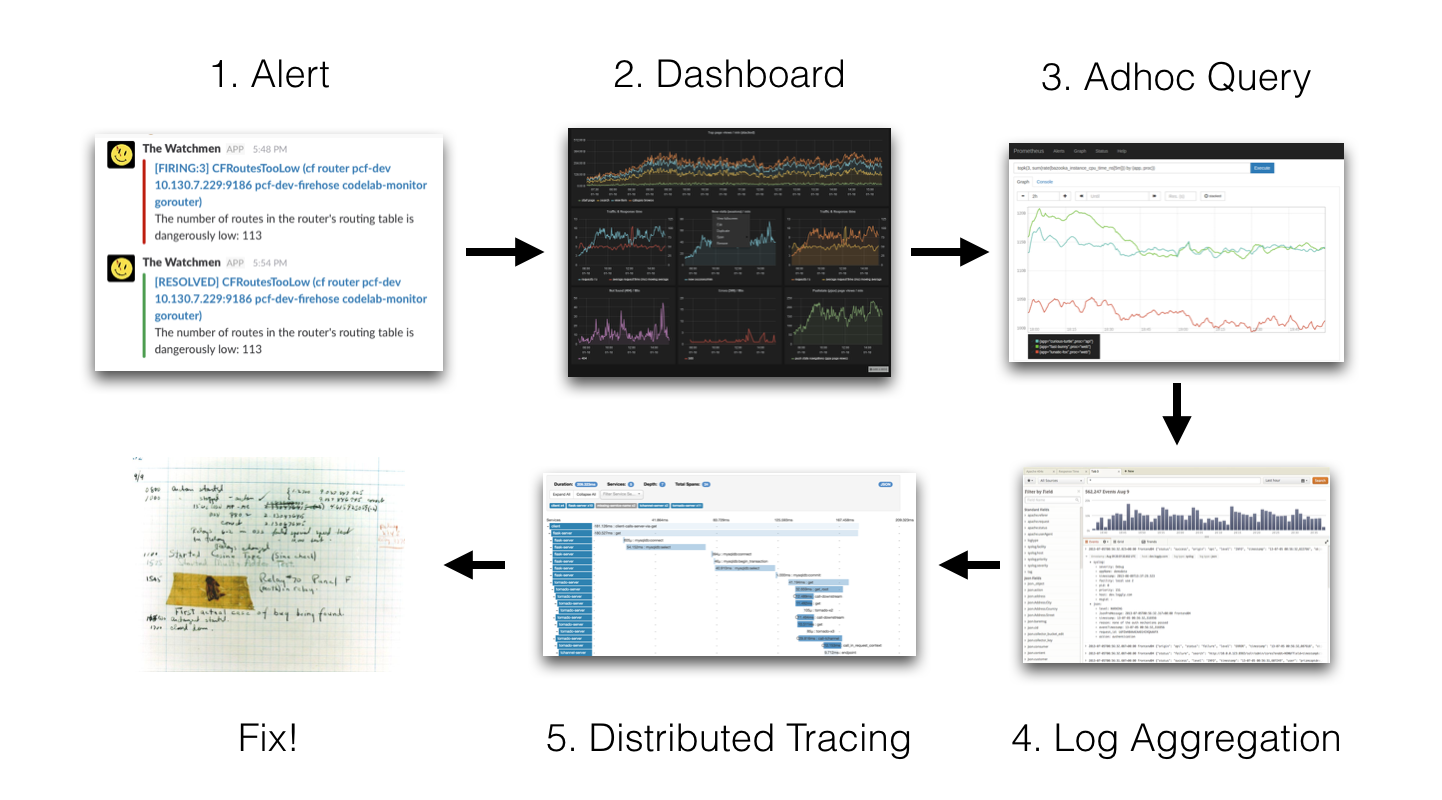
首先 Prometheus 會依據一些指標來發送警報給負責人,負責人就去會查看儀表板來查看到底是哪個服務出錯,找到之後就會透過日誌來查看錯誤,或者使用類似 Jaeger 的追蹤工具來查看請求的流程。
在 Loki 出現之前,如果我們需要查看 k8s 中的日誌,我們可以使用 kubectl logs -l name=XXX | grep XXX 指令來查看,這樣的缺點是需要逐一查看每個 pod,並且當 pod 被重啟時就有可能會導致日誌丟失,同時,在儀表板跟 CLI 中切換也是一件麻煩的事情。
我們當然可以使用類似 ELK 的系統來儲存和查看日誌,但是 ELK 本身並不是為日誌所設計,因此就會有一些缺點,例如儲存成本非常昂貴。
也因此,Grafana Labs 推出了 Loki 這個開源的日誌蒐集工具,目的就是 Keep it simple. Just support grep!。
Introduction
Like Prometheus, but for logs.
Loki 是在 2018 年的 KubeCon 中由 Grafana Labs 發布的開源軟體,是一個受到 Prometheus 啟發的水平可擴展、高可用、多租戶的日誌聚合系統,與 Prometheus 的不同之處在於它專注於日誌而不是指標,並透過 push 模型來收集日誌。
從整體的架構來看,主要可以分為三個部分 :
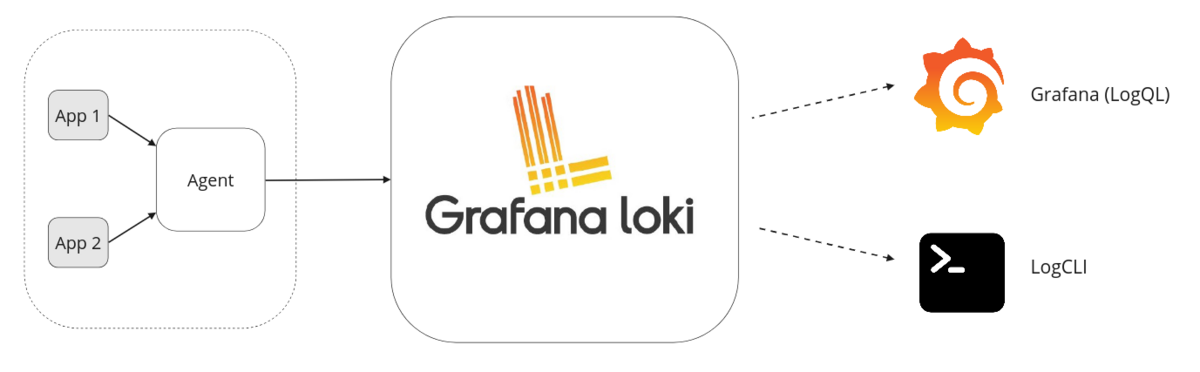
- Agent : 常見的有 Promtail、Alloy 跟 Fluentd 等,用於收集日誌和標籤並透過 HTTP request 將日誌發送到 Loki
- Loki : 用於接收、存儲日誌以及處理查詢
- Grafana : 可以使用 LogQL 來查詢並顯示 Loki 中的日誌
Loki 具有以下特點 :
- 擴展性 (Scalability) : Loki 有三種不同的部屬模式,可以將所有的組件都部屬在單一節點上,也可以將每個組件分開部屬,以滿足不同的需求
- 多租戶性 (Multi-tenancy) : Loki 可以允許多個租戶共享實例。每個租戶的資料都可以透過設定 ID 與其他租戶完全隔離
- 儲存效率 (Storage Efficiency) : Loki 使用了經過壓縮的 chunks、較小的索引以及使用物件存儲,大幅降低了儲存成本
- 警報 (Alerting) : Loki 中的
ruler組件可以用來監控日誌中的異常 - Grafana 整合 : Loki 與 Grafana 的整合非常緊密,可以方便的使用 LogQL 語言來查詢日誌
Architecture
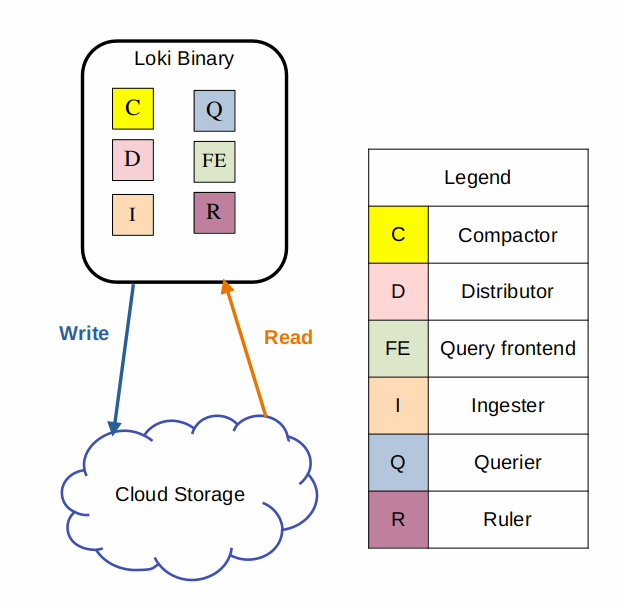
Loki 是 microservice-based 的架構,可以將所有的組件分開部署,並使用 -target 控制這個容器應該擔任的角色,具體的組件如下圖所示 :
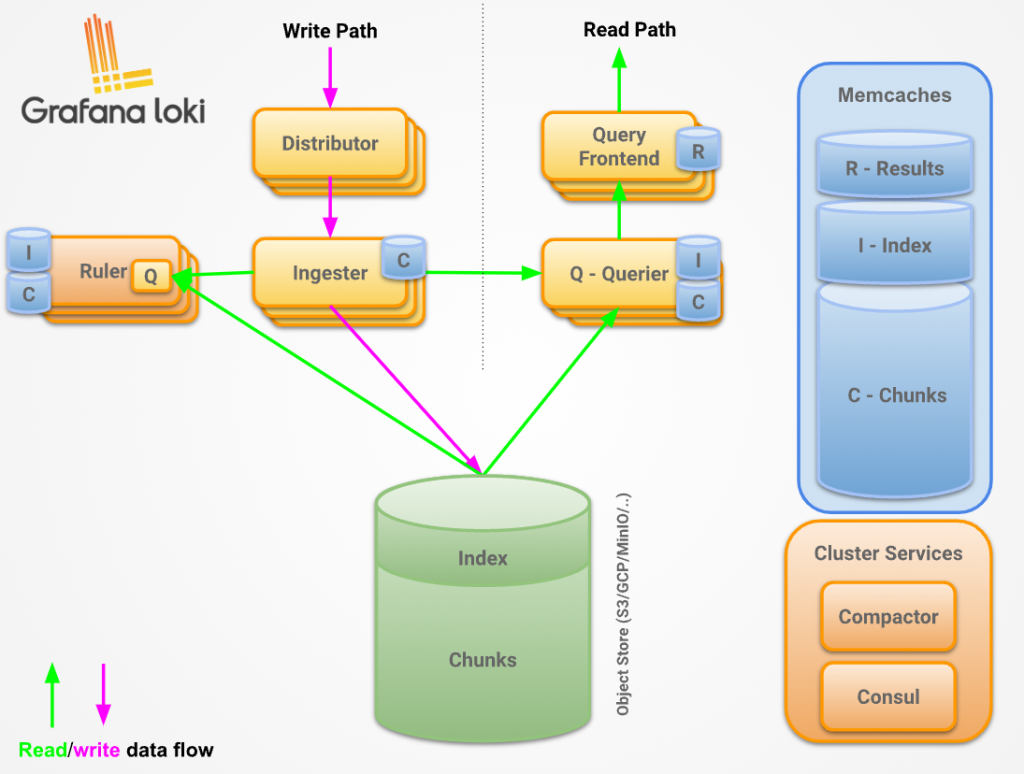
當資料寫入時,流程如下 :
- Distributor 接收包含日誌流和日誌行的 HTTP POST 請求
- Distributor 對請求中包含的每個日誌流進行哈希運算,根據一致性哈希環 (Consistent Hash Ring) 的資訊,確認每個流應被發送到哪個 Ingester
- Distributor 將每個日誌流發送到對應的 Ingester 實例以及配置的副本 (根據 Replication Factor)
- Ingester 接收到日誌流後,會為該流的數據創建一個新的 chunk 或者將數據追加到已存在的 chunk 中
- Ingester 確認寫入操作完成,向 Distributor 發送回應
- Distributor 等待多數 (Quorum) Ingester 的寫入確認
- 寫入操作成功 (失敗) 後,Distributor 向客戶端回應操作結果
當讀取資料時,流程如下 :
- Query Frontend 收到包含 LogQL 查詢的 HTTP GET 請求
- Query Frontend 將查詢分解為多個子查詢,並將這些子查詢傳遞給 Query Scheduler
- Querier 從 Query Scheduler 中提取子查詢
- Querier 將子查詢發送到所有的 Ingester,用於讀取記憶體中的數據
- 如果有的話,Ingester 會在記憶體中查找並返回相關數據
- 如果 Ingester 返回的數據不足或沒有數據,Querier 會從後端存儲中延遲加載相關數據,並對其執行查詢
- Querier 對所有接收到的數據進行迭代與去重處理,生成子查詢的結果
- Query Frontend 等待所有的子查詢完成並由 Querier 返回結果
- Query Frontend 將所有子查詢的結果合併,並將結果返回給客戶端
Storage
前面提到,Loki 最大的優勢就在於它使用了 Object Storage (如 GCS、S3、MinIO) 來存儲日誌,所有的資料都可以被分成 index 和 chunks 兩部分來存儲。
在 2.0 版本之前,Loki 需要將 index 和 chunks 分別儲存在不同的地方,index 儲存在 NoSQL / key-value 的資料庫中,chunks 儲存在物件存儲中。 在 2.0 版本之後,Loki 引進了 index shipper 來使 index 也能夠以物件存儲的形式儲存,減少了 Loki 的對外部服務的依賴,一開始採用的是 BoltDB,在 2.8 版本之後改為使用 tsdb
- Index : 用於存儲日誌的 metadata,例如日誌的標籤、時間等,是 key-value 的形式
- Chunks : 用於存儲日誌的內容
下圖展示了 Loki 如何儲存 index 和 chunks :

Loki 會將 label 進行 hash 來生成唯一的 stream ID,所有具有相同 stream ID 的 log line 都會被存儲在同一個 chunk 中。 當 chunk 被填滿時,Loki 會將這個 chunk 壓縮並上傳到物件存儲中,並且在 index 中記錄一些 metadata 跟該 chunk 的時間範圍。
Multi-tenancy
當 Loki 在 Multi-tenancy 模式下運行時,記憶體和物件儲存中的所有資料都可以按租戶 ID 進行分區,租戶 ID 會依據請求中的 X-Scope-OrgID HTTP header 來決定。
當 Loki 不處於 Multi-tenancy 模式時,header 會被忽略且租戶 ID 將設定為 fake。
Components
Distributor
Distributor 是 Loki 的入口,它接收來自搜集器的日誌並將其分發給 Ingester。 由於 Distributor 是 stateless 的,所以通常會在 Distributor 前面部屬一個負載均衡器,以便將流量分發到多個 Distributor 上,這樣做可以最大程度的減輕 Ingester 的壓力並防禦 DDoS 攻擊。
Distributor 有以下幾個主要功能 :
-
Validate
確保傳入的格式符合規範,像是檢查標籤是否有效,時間戳是否合法等
-
Preprocessing
Distributor 會將標籤進行排序方便後面進行哈希運算,例如將
c=b,a=b轉換為a=b,c=b -
Rate limiting
可以對每個不同的租戶進行限流,以防止某個租戶的日誌過多導致系統壓力過大
Loki 允許我們在集群級別進行限流,會根據當前 Distributor 的數量來計算,舉例來說,假如有 10 個 Distributor 且我們的限流為 10 MB/s,那麼每個 Distributor 的限流就是 1 MB/s
-
Forwarding
一旦日誌被驗證並預處理,Distributor 就會將日誌轉發給指定的 Ingester
-
Replication factor
為了降低單個 Ingester 可能遺失資料的風險,Distributor 會將寫入資料轉發到多個 Ingester,這個數量由 Loki 的設定檔中的
replication_factor決定,預設為 3Distributor 會透過 ring 來判斷目前那些 Ingester 是活著的,並將資料轉發給這些 Ingester 並等待回應
-
WAL (Write-Ahead Log)
除了 Replication factor 之外,Ingester 還會有 Write-Ahead Log (WAL) 來保證在重新啟動時不會遺失資料
-
-
Hashing
Distributor 會將日誌流進行哈希運算,並根據一致性哈希環 (Consistent Hash Ring) 的資訊,確認每個流應被發送到哪個 Ingester
-
Quorum consistency
所有的 Distributor 都會共享同一個 ring 以確保寫入請求可以被路由到任一個 Ingester
Loki 使用了 dynamo-style quorum consistency 來確保寫入的一致性,這意味著至少需要
replication_factor / 2 + 1個 Ingester 回應才會顯示成功,否則會重新進行寫入
Ingester
Ingester 是 Loki 的核心,它負責接收日誌並將其寫入物件存儲中,同時也負責從記憶體中讀取日誌並提供給 Querier 進行查詢。
Ingester 包含一個生命管理器 (Lifecycler),用於管理在哈希環內的生命週期,分別為 :
- PENDING : 當 Ingester 啟動並在等待一個舊的 Ingester 做 handoff 時就會處於 PENDING 狀態 (需要注意 handoff 這個機制已經棄用)
- JOINING : 當 Ingester 正在將令牌插入到哈希環中時就會處於 JOINING 狀態,此時已經可以接收寫入請求
- ACTIVE : 完成初始化並開始接收讀寫請求時就會處於 ACTIVE 狀態
- LEAVING : 當 Ingester 準備離開哈希環時就會處於 LEAVING 狀態,此時依然可以處理讀取請求來提供記憶體中的資料
- UNHEALTHY : 當 Ingester 無法發送 heartbeat 時就會處於 UNHEALTHY 狀態
Ingester 接收到的每個 log stream 會被組織成多個 chunks 儲存在記憶體中,並在可配置的時間後 flush 到物件存儲中。
在以下的情況下,chunk 會被標記成 read-only 並壓縮 :
- Chunk 被寫滿
- Chunk 有一段時間沒有被寫入
- 發生 flush
每當有 chunk 被標記成 read-only 時,就會有新的 chunk 被創建。
如果 Ingester 突然崩潰,未被寫入物件存儲中的 chunk 會被丟失,因此 Loki 通常會設置 replica factor 並使用 WAL 來保證在 Ingester 重啟時不會遺失資料。
當 Ingester 要將 chunk 寫入物件存儲中時,會依據租戶 ID、標籤、內容來計算一個 hash 值,讓後端不需要重覆儲存相同的 chunk,但如果有資料寫入失敗,則會在後端儲存多個副本,Querier 會在查詢時進行去重。
Loki 預設為接受無序的日誌,但可以透過設定 unordered_writes 來接受有序的日誌,如果設置成有序的話,則會在 Distributor 中進行驗證。
對於相同納米的 timestamp,如果內容完全相同,則 Loki 會將其視為重複的日誌,並且只會儲存一份。
Query Frontend
Query Frontend 是一個可選的組件,可以用於加速查詢。當有 Query Frontend 時,應該要將查詢的流量導向到 Query Frontend 上,再由 Query Frontend 將查詢分發給 Querier。
Query Frontend 是一種無狀態的組件,在大多數情況下只需要兩個就足夠了。
以下是 Query Frontend 的主要功能 :
-
Queueing
即使沒有獨立的 Query Scheduler,Query Frontend 也可以將查詢排隊
排隊功能可以帶來以下的好處 :
- 防止 Querier 的記憶體溢出 (OOM) : 如果發生了 OOM,也可以進行重試,提升查詢的穩定性,同時也可以降低記憶體的需求
- 負載均衡 : 將大型查詢分散到多個 Querier 上,避免單個 Querier 被壓垮
- 租戶的公平調度 : 可以用於防止單一租戶的 DDoS 影響到其他租戶
-
Splitting
Query Frontend 可以將大型查詢分割成多個子查詢來並行處理,在進行合併,可以避免單個查詢過於龐大而導致 OOM
-
Caching
Query Frontend 提供了多種不同的 cache 策略,用於提升查詢的速度 :
- Metric queries : 可以快取前端的 metric 查詢結果,如果塊取的結果不完整,則可以使用子查詢來補全。此外,可以選擇性地將查詢與 step 參數對齊,以提高 cache 的命中率,並將結果快取到 redis 或 memory 中。
- Log queries : 對於 log query,Query Frontend 使用 negative cache 來記錄空的時間段
- Index stats queries (索引統計查詢) : 主要用於 Loki 內部,類似 Metric queries,只能在 single store 的 tsdb 中使用
- Log volume queries (日誌量查詢) : 主要用於 Loki 內部,類似 Metric queries,只能在 single store 的 tsdb 中使用
Query Scheduler
Query Scheduler 是 Loki 的一個可選組件,提供比 Querier Frontend 更進階的排隊功能,如階層式的隊列。
可以參考 advanced queuing functionality。
Querier
Querier 負責實際執行 LogQL 查詢,它會從 Ingester 跟 Object Storage 中讀取資料,並將結果返回給 Query Frontend。
由於 replication_factor 的存在,有時候 Querier 會收到重覆的資料,因此 Loki 會在 Querier 中進行去重。
Index Gateway
Index Gateway 負責處理有關於 metadata 的查詢,例如 label names 等等的查詢。
Query Frontend 會跟 Index Gateway 查詢日誌量,以便決定該用甚麼方法進行查詢分片。 Querier 則會向 Index Gateway 查詢 chunks 的引用,以便知道要查詢哪些 chunks。
Compactor
Compactor 會定期運行,從物件存儲中讀取 tsdb 檔案進行合併後再寫回物件存儲中,此外,Compactor 也負責日誌的保留跟刪除功能,通常會使用單一的實例。
Ruler
可以在物件存儲中設定告警規則,Ruler 會定期檢查這些規則並發送告警,也可以將這些規則委託給 Query Frontend 來執行,這種模式稱為 Remote Rule Evaluation。
Other Components
除了之外,目前也有一些基於布隆過濾器 (Bloom filter) 的組件在筆者寫這篇文章時還在處在實驗性的階段,例如 :
- Bloom Planner
- Bloom Builder
- Bloom Gateway
這三個組件旨在利用布隆過濾器來加速 chunk 的查詢,快速過濾掉那些不可能符合條件的 chunk。
Deployment Mode
如前所述,Loki 是一個有很多微服務組成的分散式系統,因此可以根據不同的需求來部署不同的模式。
Monolithic mode
最簡單的部屬方法就是單體部屬模式,將所有的組件都部屬在同一個節點上,對於 20GB/day 左右的日誌量來說,這樣的部屬方式是足夠的。
這種方式同樣也可以做水平擴展,只需要在設定檔中設定 ring 和 memberlist_config 就可以了。
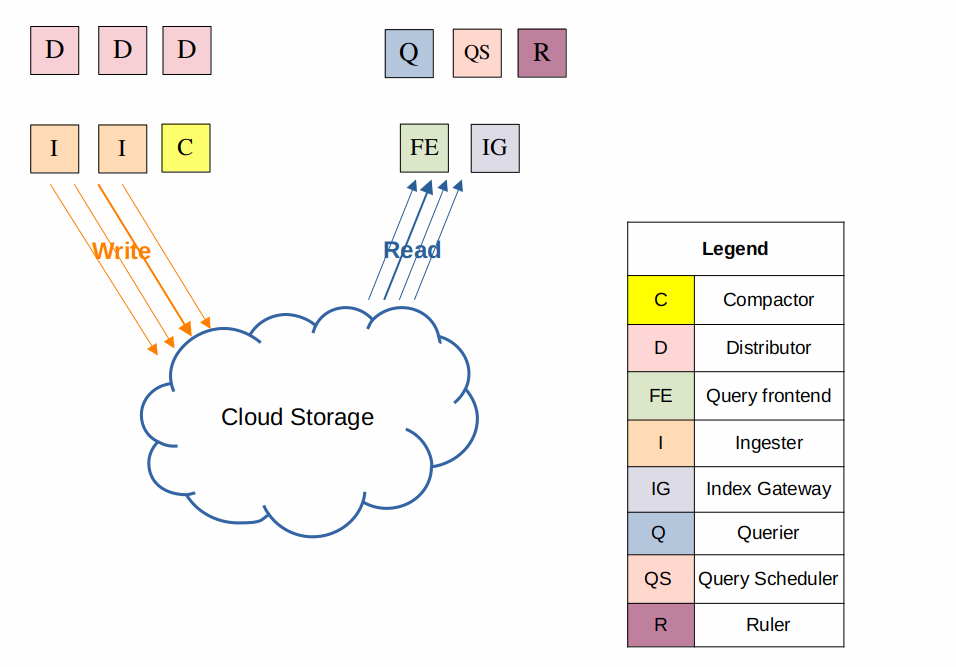
Simple scalable mode
這種模式是 Helm Chart 預設的部屬方式,將組建分成讀取、寫入、後端三個部分,並使用 Nginx 作為反向代理來分開轉發讀寫請求,對於 TB 級別的日誌量來說,這樣的部屬方式是足夠的。
target=write: Distributor、Ingester,是有狀態的,由 k8s statefulset 控制target=read: Querier、Query Frontend,是無狀態的,由 k8s deployment 控制target=backend: Compactor、Ruler、Index Gateway、Query Scheduler,是有狀態的,由 k8s statefulset 控制
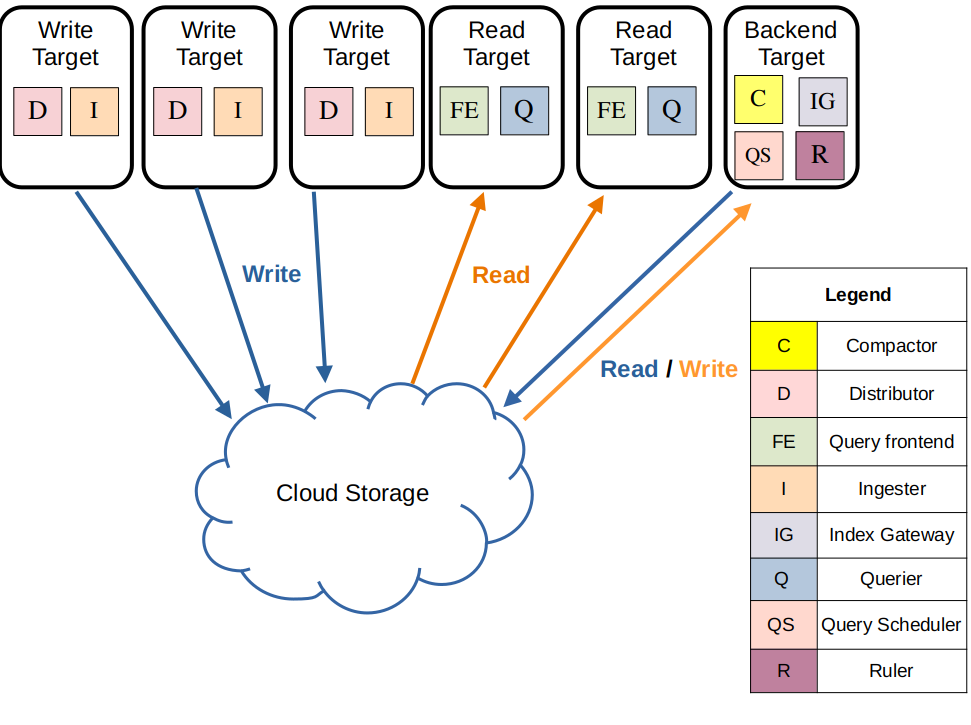
Microservices mode
也可以選擇將全部的組件都分開部署以提供最好的擴展性,但同時也會增加部署的複雜度。
Label
Labels 對於 Loki 來說是一個非常重要的組件,它不僅可以用於當 sharding key 來決定日誌的存儲位置,也可以用於查詢時的過濾,因此正確的使用 label 可以顯著提高 Loki 的效能。
Label Best Practices
接下來會透過一個例子來說明如何正確地使用 label 來提高 Loki 的效能。
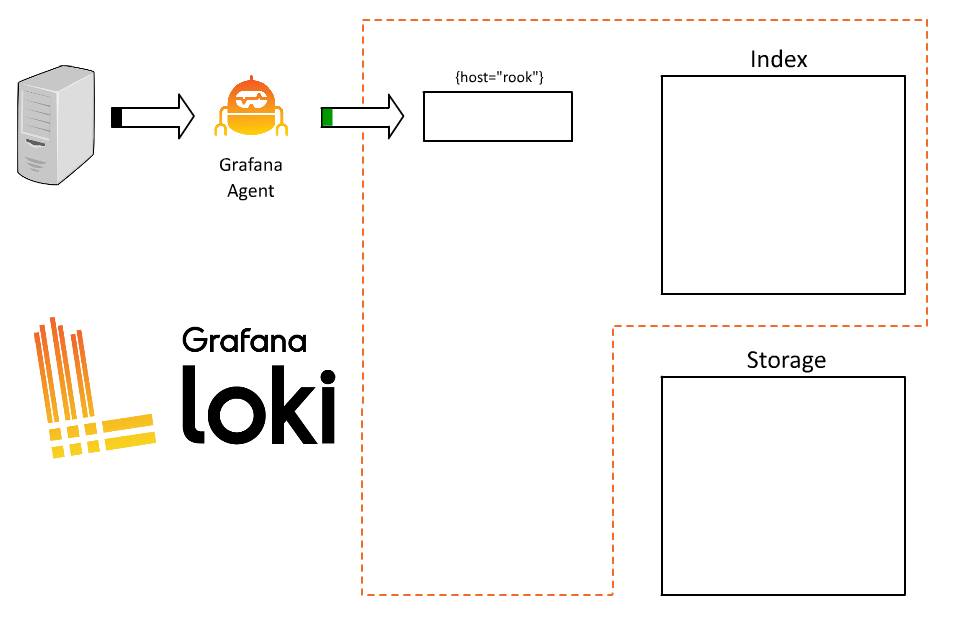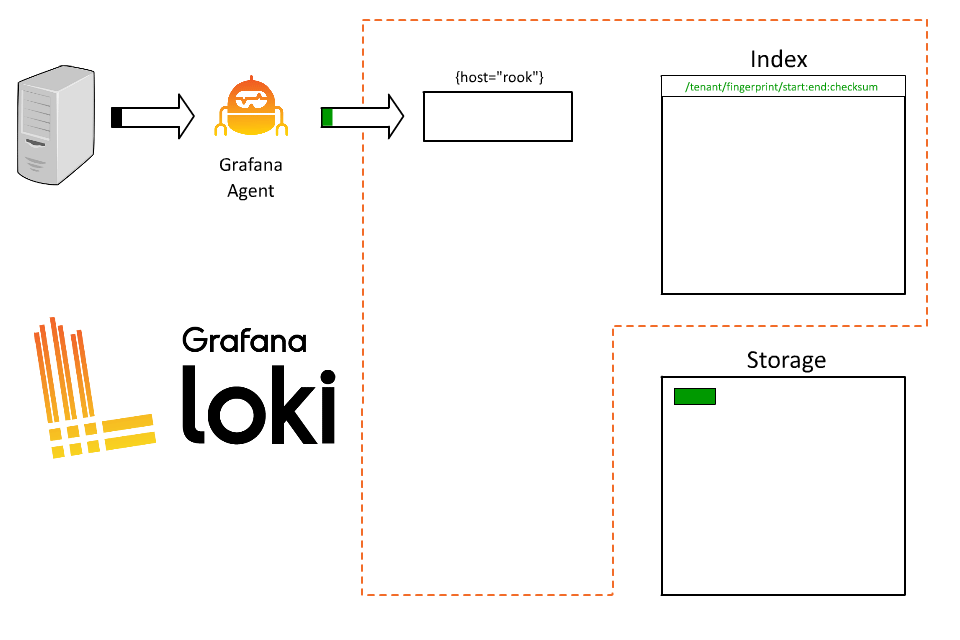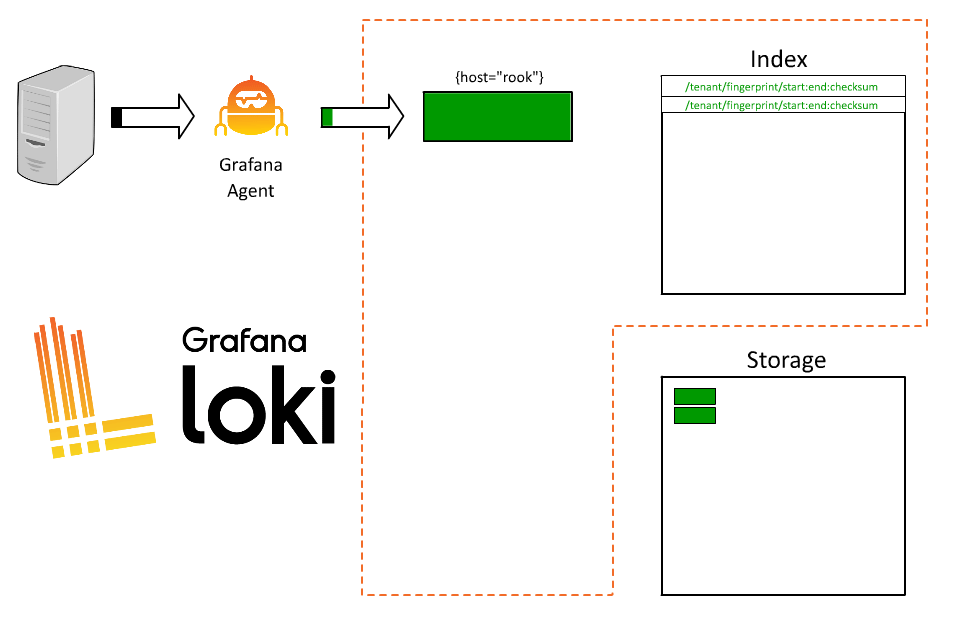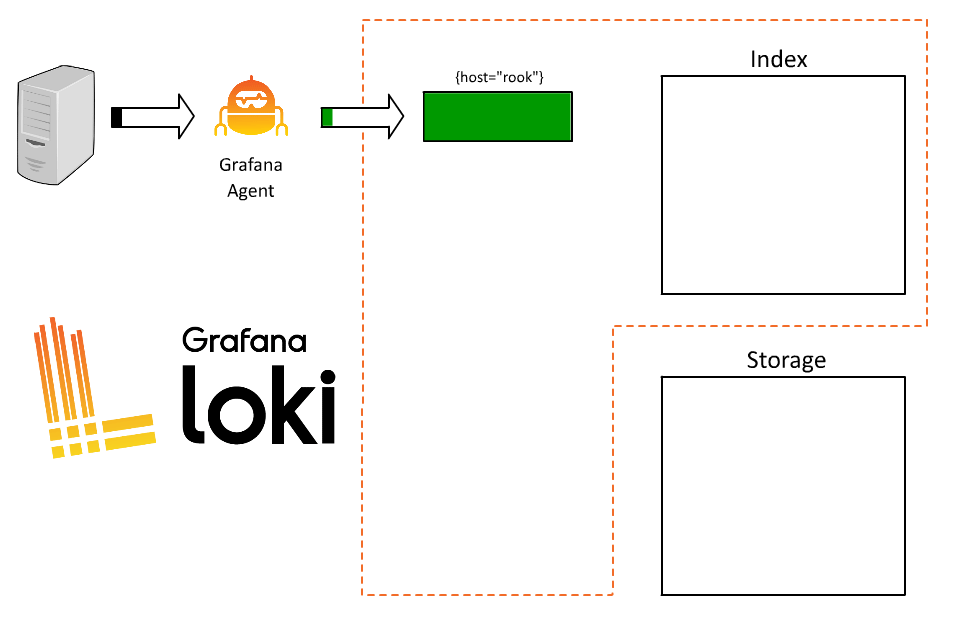
首先我們可以簡單的分配一個 label 來表示 host,例如 :
{host="rook"}
這時候 Loki 就會基於這個 label 來建立 stream,在固定的時間間隔後,Loki 會將這些 stream 壓縮成 chunks 並上傳到物件存儲中。
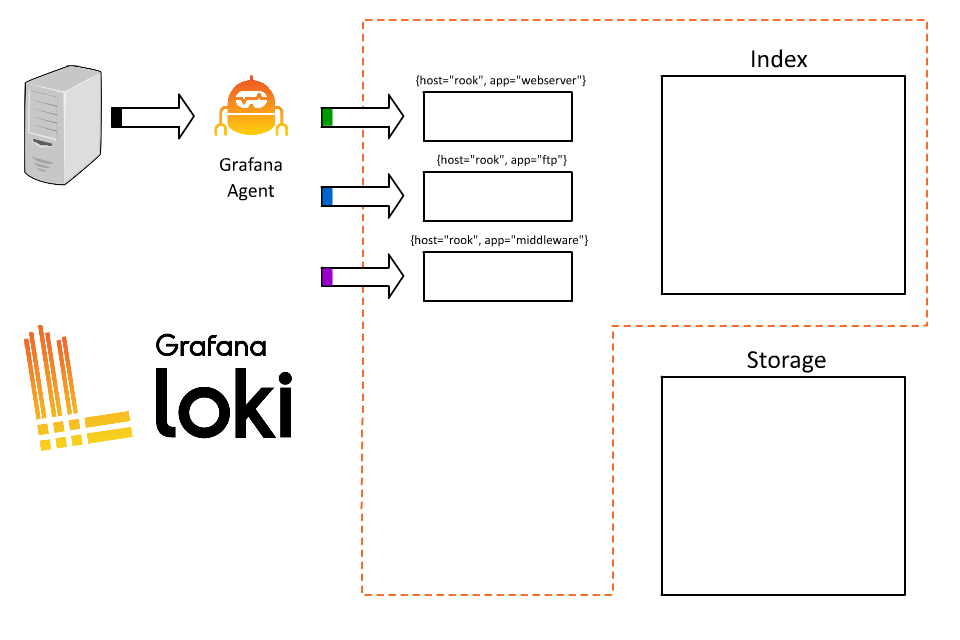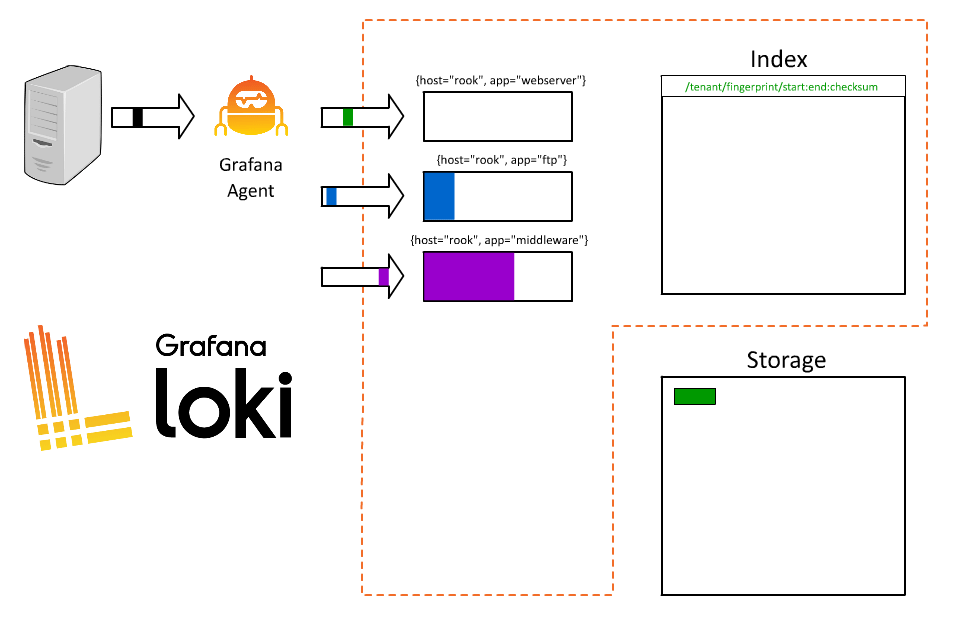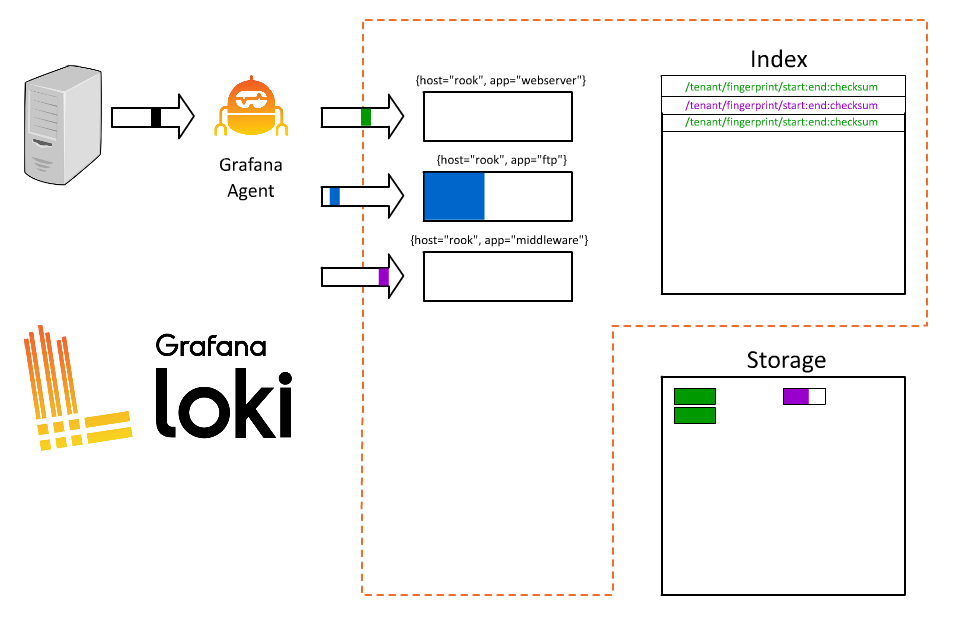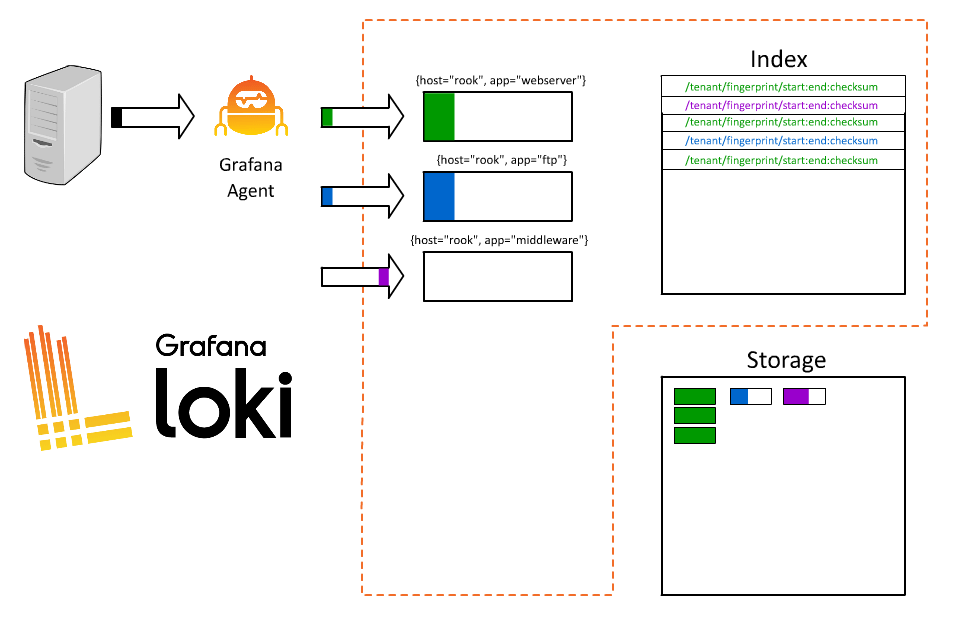
在 rook 這個 host 上,我們可能同時運行了很多個 service,使用者目前無法透過日誌知道這條 log 來自於哪個系統,因此決定可以再加上一個 label 來表示服務名稱,例如 :
{host=”rook”, app=”webserver”}
{host=”rook”, app=”ftp”}
{host=”rook”, app=”middleware”}
於是,我們就可以使用 app 來查詢了
接著使用者又遇到了新的問題,我想要查詢每筆訂單的日誌,但是 Loki 並沒有辦法直接查詢到這些日誌,因此決定再新增一個 label 來表示訂單 ID,例如 :
{host=”rook”, app=”webserver”, order_id=”123”}
{host=”rook”, app=”webserver”, order_id=”456”}
{host=”rook”, app=”webserver”, order_id=”789”}
這時候就遇到問題了,每筆 log 都被儲存在 short-lived 的 stream 中,當每個 stream 都被寫成獨立的文件時,就會產生非常多占用空間的小檔案,降低了 Loki 的效能。
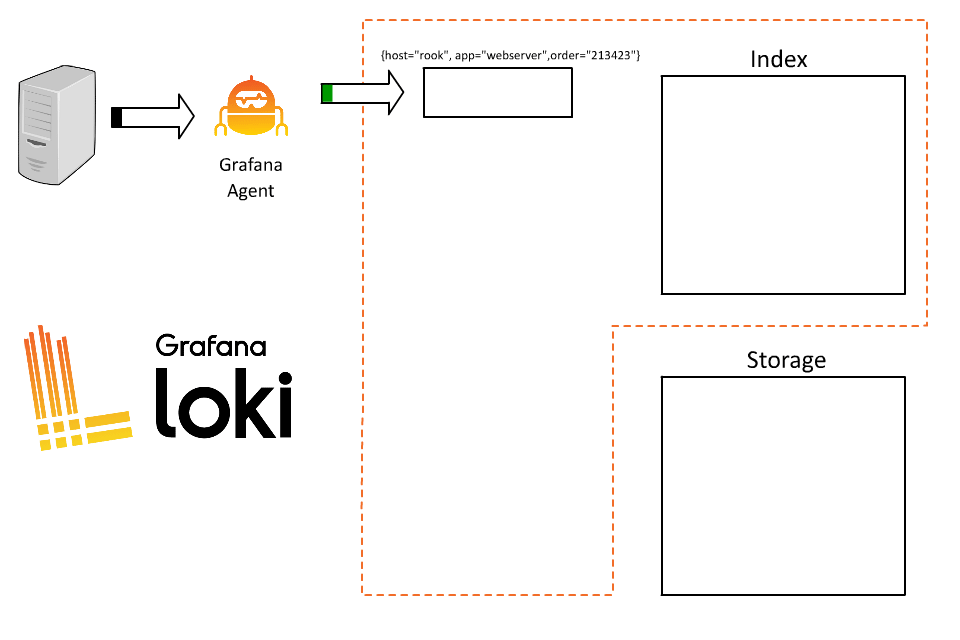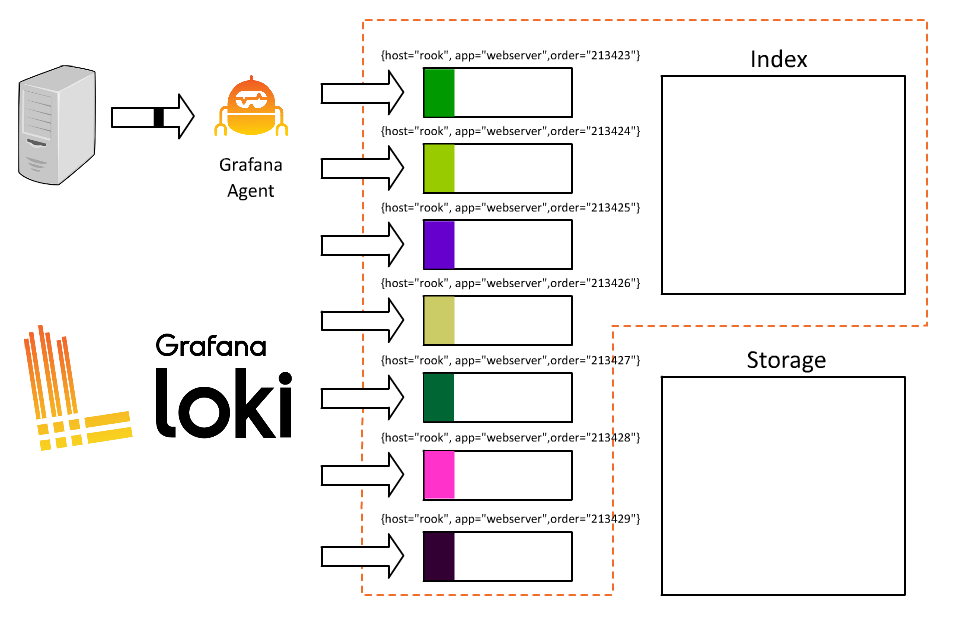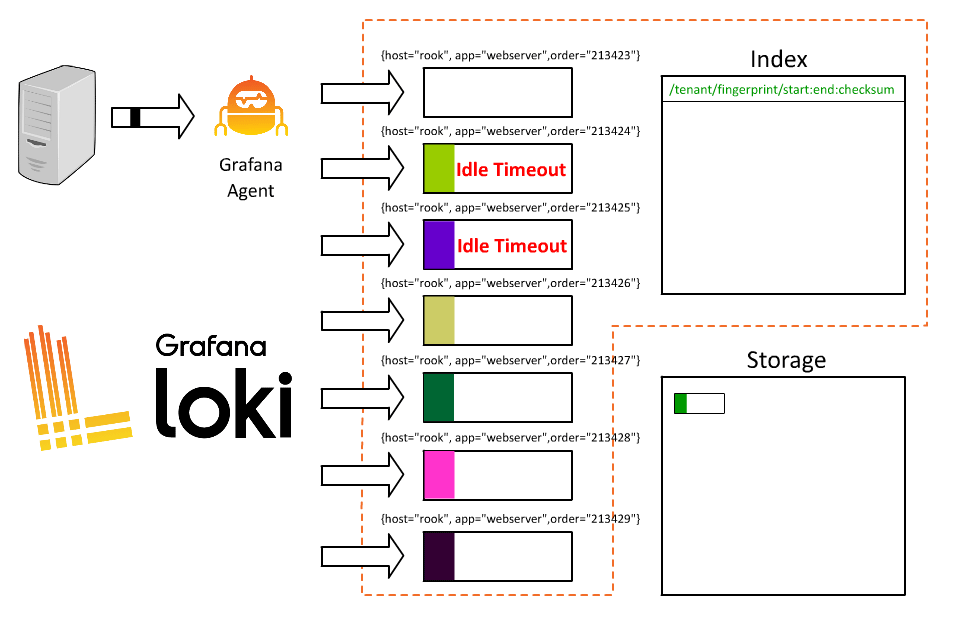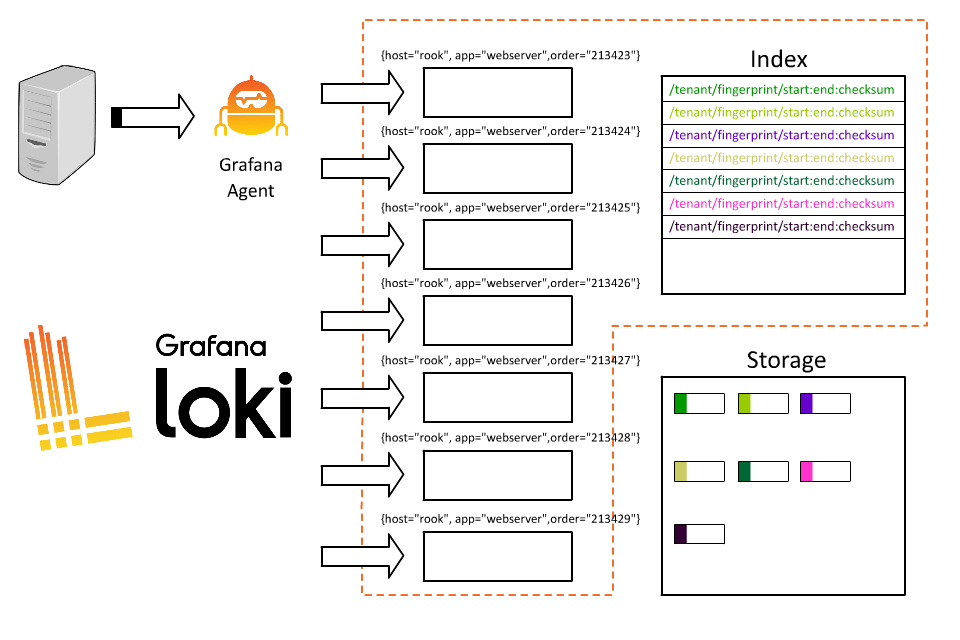
因此,與其它的日誌系統相比,我們需要在 label 的設計上有不同的思考方式,以下是一些 Loki 的 label 設計原則 :
- Describe infrastructure : 例如 region、zone、host、cluster、namespace、environment 等等
- Long-lived : 這些標籤應該長期存在
- Intuitive : 標籤應該是直觀的,例如
app、service、component等等
Automatic Stream Sharding
同時,為了防止同一個 stream 的流量太多導致所有的日誌都被分發到同一個 Ingester 中,Loki 也引入了 automatic stream sharding 機制,這樣可以讓 Loki 在寫入時自動將流量分發到不同的 Ingester 中。
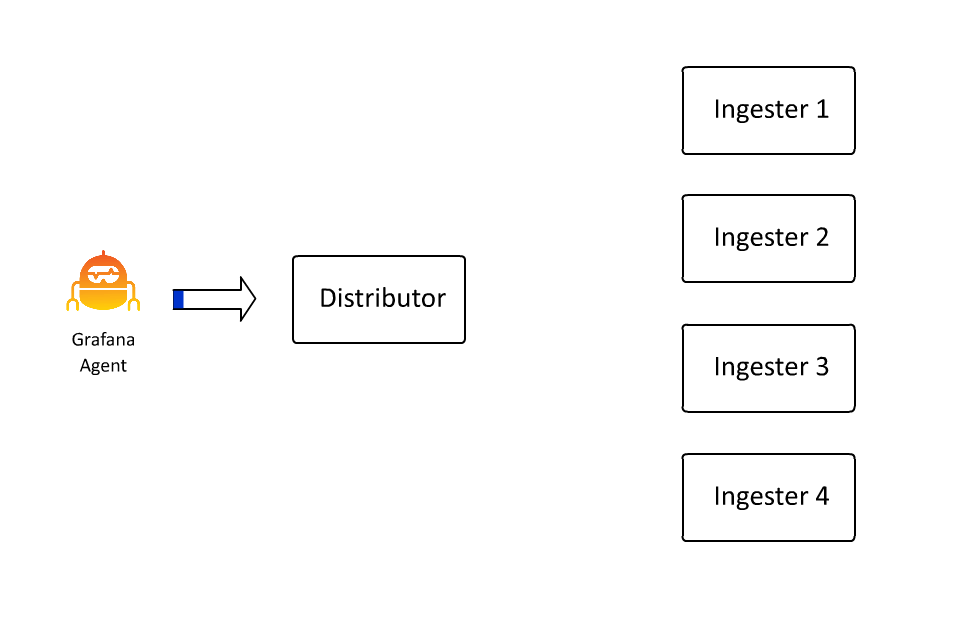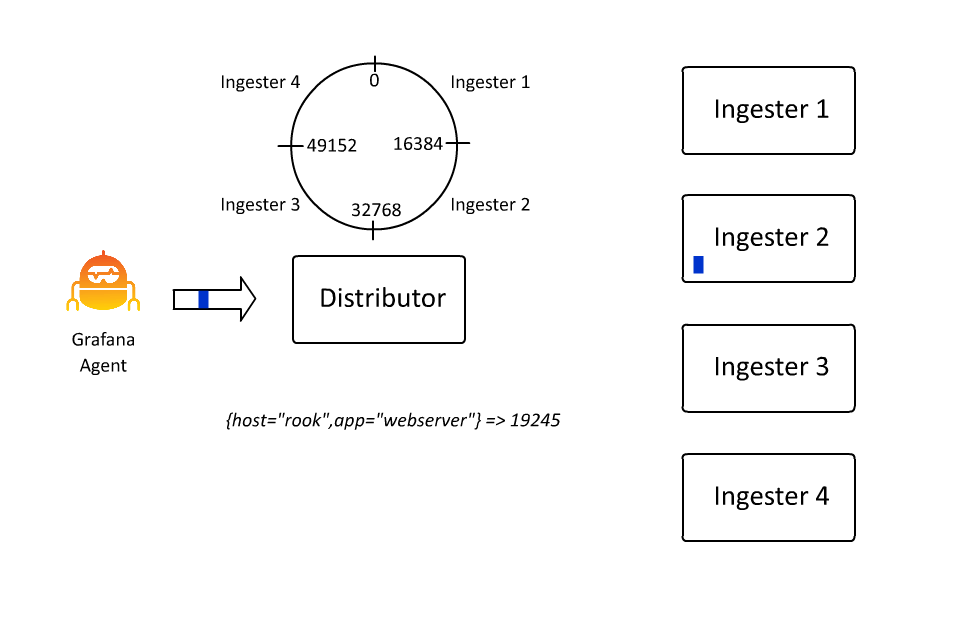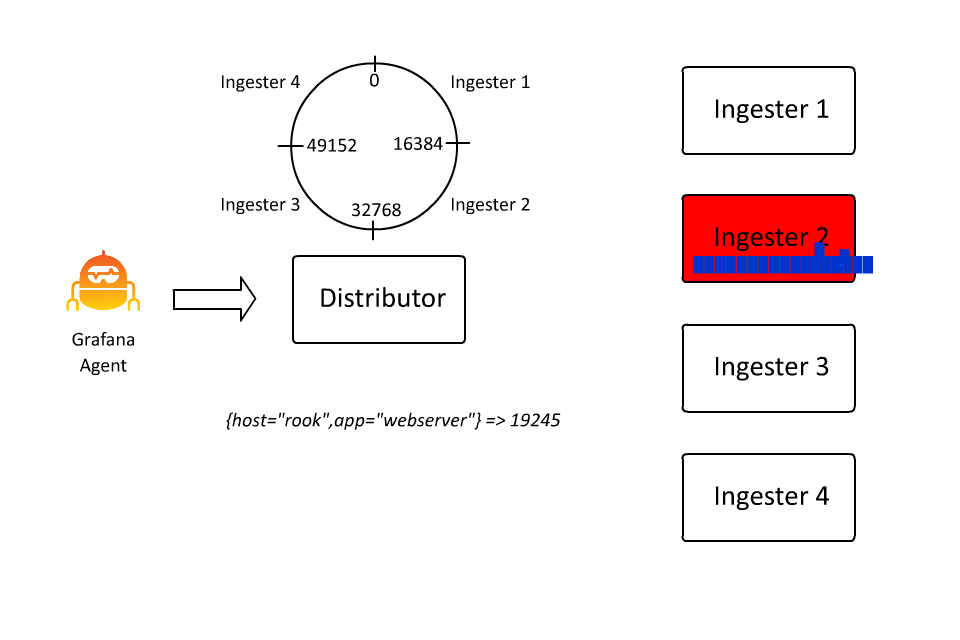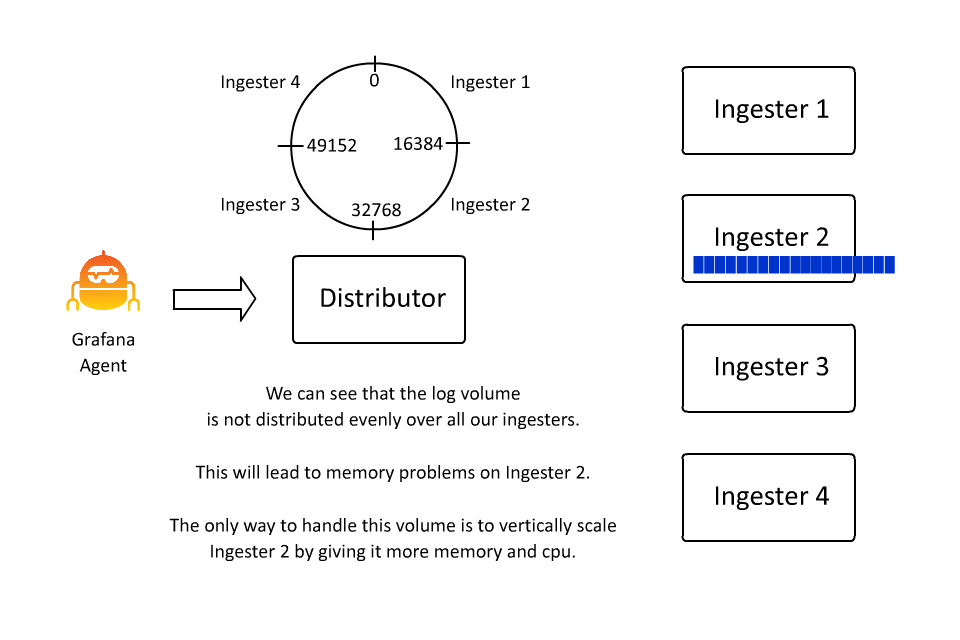
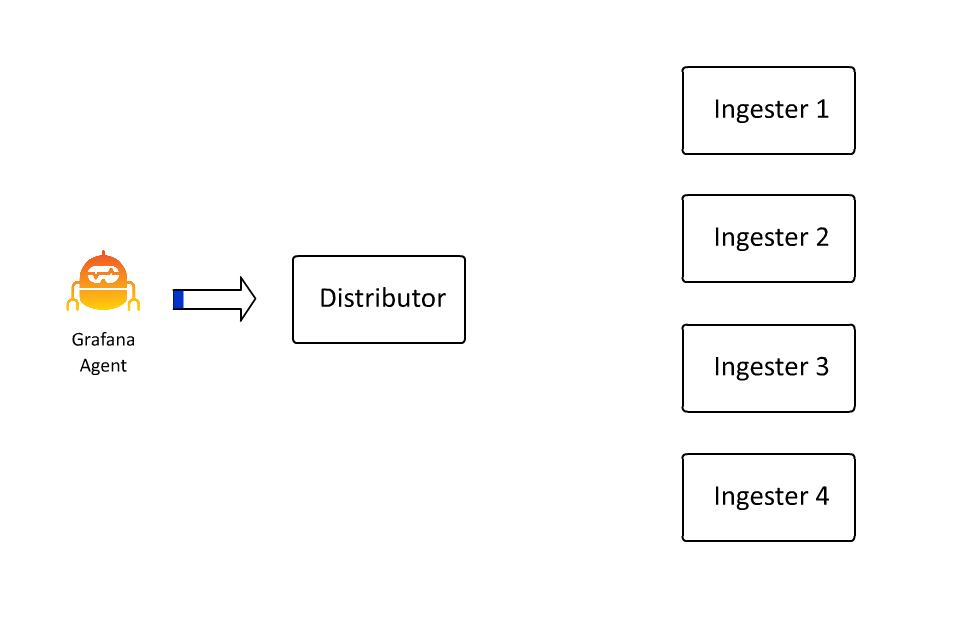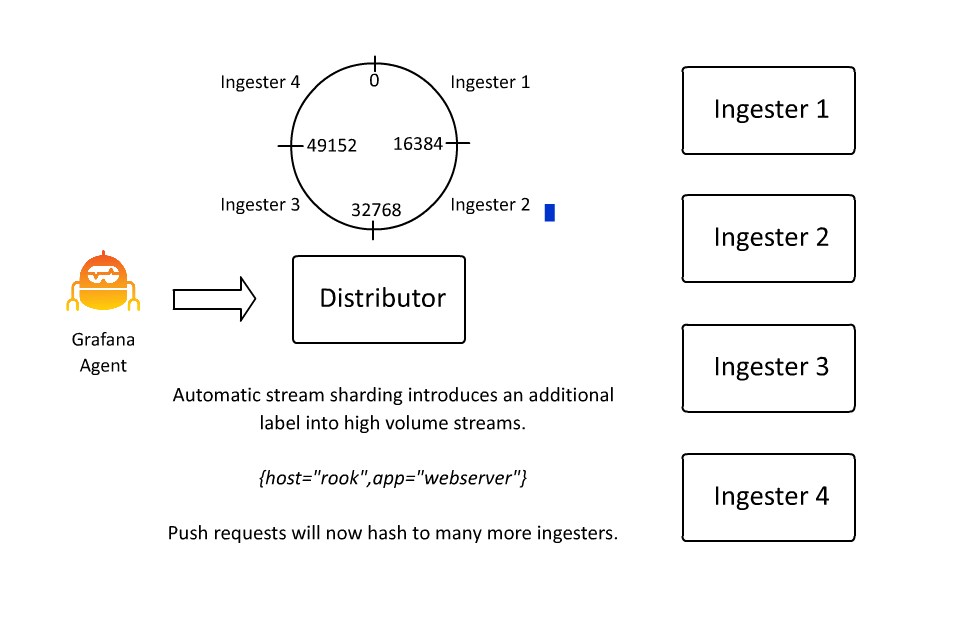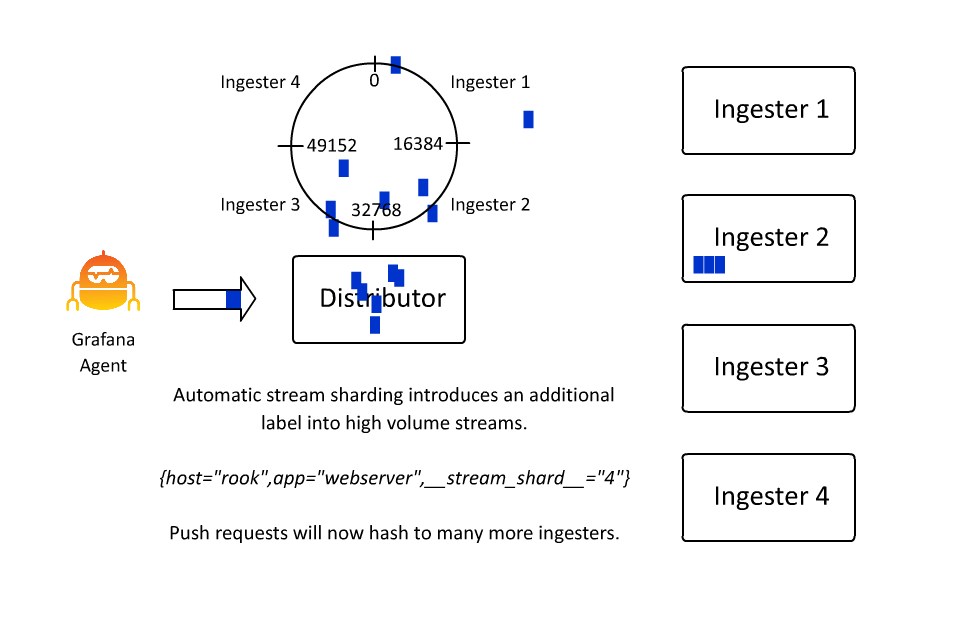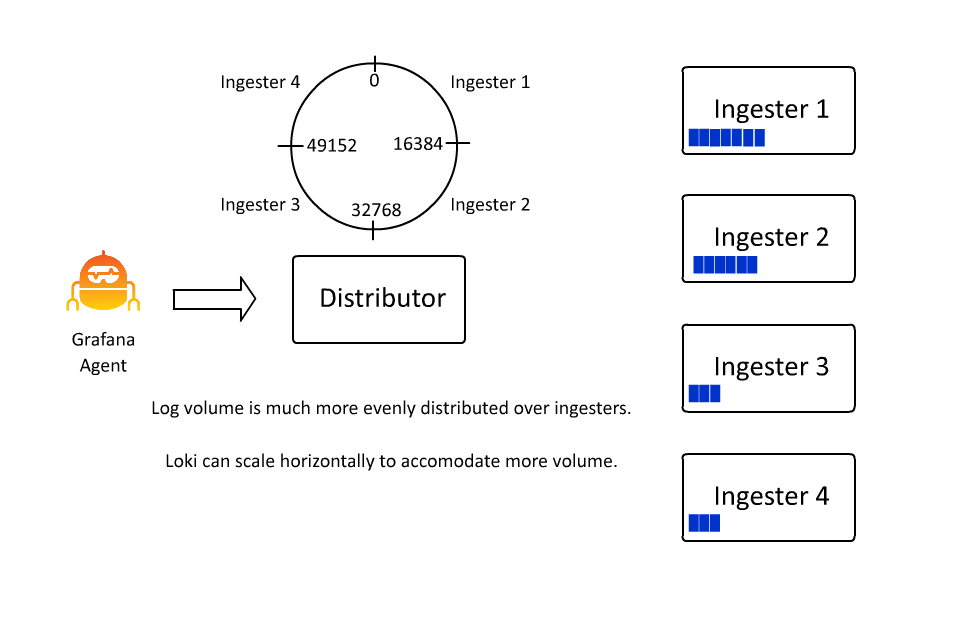
Structure Metadata
在這樣的 label 設計下有可能會產生一些問題,例如我們想要搜尋某個 Pod 的 ID,但是由於這個值是一個高基數的 label,因此我們不確定是不是應該把這個值放在 label 中。
在新版的 Loki 中,Loki 引入了 structured metadata 的概念,可以將 key-value 的值儲存在日誌行的旁邊而不是存在 label 中,這樣就可以避免產生高基數的 label 並且可以更快的查詢到這些資料。
Bloom Filter
那麼如果我想在 Loki 中搜尋唯一的 ID 時應該怎麼辦呢?
舉例來說,我可能會想做以下的搜尋 {env=”prod”} |= “603e0dcf-9b24-4c37-8f0d-6d8ebe5c5c8a”
Loki 會採用大量平行化的方式來處理這個問題,同時使用 Bloom filter 搭配 n-gram 來進行過濾。
- Bloom filter : 一種機率型資料結構,用於快速檢查一個元素是否在一個集合中,空間效率非常高
- n-gram : 一種將字串拆分成 n 個連續的子字串的方法,這樣做的原因是可以提高彈性與容錯,同時可以讓我們捕捉到 schemaless 的 log
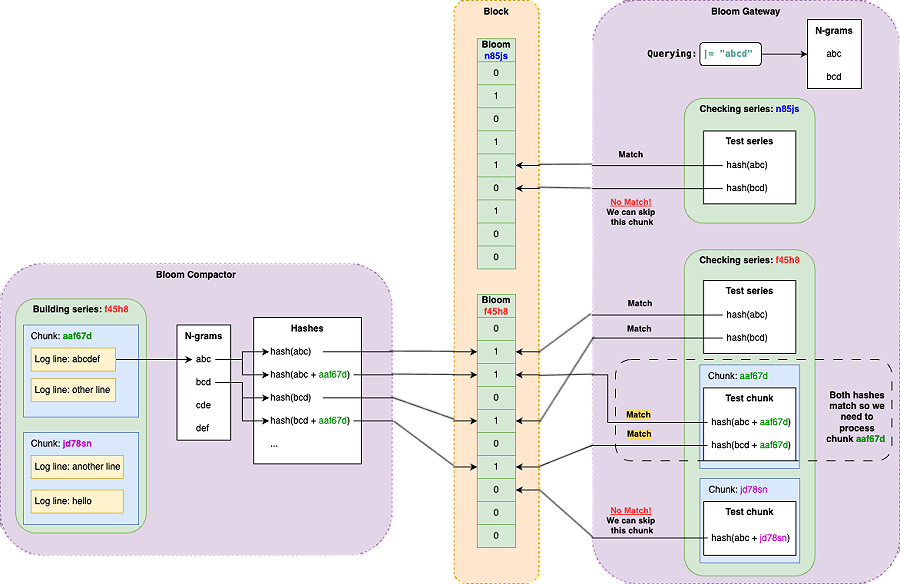
我們可以從上圖中看到兩個關鍵的組件,分別是 Bloom Compactor 跟 Bloom Gateway。
-
Bloom Compactor :
- 負責在 Loki 的物件儲存中的日誌區塊 (chunks) 建立 Bloom filter
- 針對每個日誌序列 (series,類似於 stream id) 建立 Bloom filter
- 從每個日誌序列的每個日誌行中提取 n-grams
- 將每個 n-gram 的雜湊值 以及 (n-gram + chunk ID) 的雜湊值 加入到對應日誌序列的 Bloom filter 中
- 將 Bloom filter 聚合到區塊檔案 (block files) 中,並產生元數據檔案 (metadata files) 記錄 Bloom 區塊和對應的 TSDB 索引檔案的關聯
-
Bloom Gateway :
- 接收來自 Index Gateway 的區塊過濾請求
- 根據查詢的過濾表達式,提取 n-grams
- 使用這些 n-grams 查詢 Bloom filter,判斷哪些日誌區塊 可能 包含符合過濾條件的日誌
- 過濾掉被 Bloom filter 判斷為肯定不符合的區塊,只將可能符合的區塊送給後續的查詢引擎進行詳細掃描
透過上面這兩種方式,Loki 可以在不增加額外的資源的情況下,提高查詢的效能。
但是,並不是每種 LogQL 都能受益於 Bloom filter,以下是一些可以使用跟不能使用 Bloom filter 的例子 :
- 查詢應該包含至少一種過濾式
# 使用布隆過濾器
{host="rook", app="webserver"} |= "order=17863472" | logfmt
- 使用了
!=或!~的過濾式以及在 format 之後的過濾式不會使用布隆過濾器
# 不使用布隆過濾器
{host="rook", app="webserver"} != "debug"
{host="rook", app="webserver"} !~ "(staging|dev)"
# `level="error"` 使用布隆過濾器
# `traceID="3ksn8d4jj3"` 不使用布隆過濾器
{host="rook", app="webserver"}
|= `level="error"`
| logfmt
| line_format “ERROR {{.err}}”
|= `traceID=“3ksn8d4jj3”`
Reference
- Grafana Loki
- How to get started with logging using Grafana Loki
- Grafana Loki Deep Dive
- 可觀測性宇宙的第二十二天 - Grafana Loki 介紹 - 性價比的王者
- Loki: Prometheus-inspired, open source logging for cloud natives
- Open source log monitoring: The concise guide to Grafana Loki
- All the Components of Loki Explained | Grafana Labs
- Grafana Loki query acceleration: How we sped up queries without adding resources
- 手把手教你 Grafana Loki : 從入門到精通
- 【DevOps】Grafana + Loki + Promtail Logging system 小試牛刀
- Grafana Loki 简明教程
- Grafana 系列文章(九):开源云原生日志解决方案 Loki 简介
- Grafana 系列文章(十):为什么应该使用 Loki
- All things logs: best practices for logging and Grafana Loki
- Why You Should Consider Loki as an Alternative to Elasticsearch!
- How Loki Reduces Log Storage