P3 - Query Execution
在這個 project 中,我們需要實現一個 query execution engine,總共有 4 個 task :
- Access Method Executors
- Aggregation & Join Executors
- HashJoin Executor and Optimization
- External Merge Sort + Limit Executors
Background
這個 project 的背景知識相對比較複雜,需要大量閱讀程式碼來了解整個結構。
我會介紹一下整個 SQL 從輸入到執行的流程以及資料儲存的結構來方便大家理解。 如果還是有卡住的話,我建議可以先去看一些已經實現好的 Executor 來了解整個流程。
SQL Query Journey
這邊會用一個簡單的 SQL 當作範例,簡單介紹一下 bustub 中 SQL 是怎麼被執行的。 範例這部分我是用 AI 幫忙生成的,不一定是真正的欄位但能了解意思就好 :
SELECT s.id, s.name, e.course
FROM student s
JOIN enrollment e ON s.id = e.sid
WHERE s.age > 18
LIMIT 10;
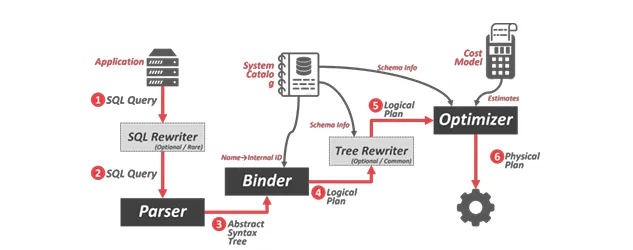
Entrypoint
Shell 的入口點在 src/tools/shell/shell.cpp,負責創建 BustubInstance 實例並呼叫 bustub->ExecuteSql() 來執行 SQL。
BustubInstance 的 ExecuteSql() 函數是執行 SQL 的主要入口,它會呼叫 ExecuteSqlTxn() 來執行查詢,如果出現錯誤則會呼叫 Abort()。
Parser
首先 query 會先進入 parser,parser 的作用是將 SQL 解析成 AST,這部分 bustub 是使用第三方的工具 libpg_query 來完成的。
在 ExecuteSqlTxn() 中 bustub 會呼叫 ParseAndSave() 來將 SQL 解析成 AST,並把結果存到 statement_nodes_ 中。
以上面的 SQL 為例,解析後的 AST 可能會長這樣 :
PGSelectStmt {
targetList: [
PGResTarget { name: "id", val: PGColumnRef { fields: ["s", "id"] } },
PGResTarget { name: "name", val: PGColumnRef { fields: ["s", "name"] } },
PGResTarget { name: "course", val: PGColumnRef { fields: ["e", "course"] } }
],
fromClause: [
PGJoinExpr {
jointype: JOIN_INNER,
larg: PGRangeVar { relname: "student", alias: "s" },
rarg: PGRangeVar { relname: "enrollment", alias: "e" },
quals: PGAExpr { op: "=", lexpr: "s.id", rexpr: "e.sid" }
}
],
whereClause: PGAExpr { op: ">", lexpr: "s.age", rexpr: 18 },
limitCount: 10
}
Binder
接著這個 AST 就會交給 binder,binder 的作用是透過 Catalog 將 AST 中的名稱綁定到實際的資料庫物件上。
在 ExecuteSqlTxn() 中,BindStatement() 函數會負責這個工作。
以上面的 SQL 為例,綁定之後的 AST 可能會長這樣,可以看到它已經有 table_oid 跟 col_idx 了 :
SelectStatement {
select_list_: [
BoundColumnRef { col_name: "id", type: INTEGER, table_oid: 1, col_idx: 0 },
BoundColumnRef { col_name: "name", type: VARCHAR, table_oid: 1, col_idx: 1 },
BoundColumnRef { col_name: "course", type: VARCHAR, table_oid: 2, col_idx: 1 }
],
table_: BoundJoinRef {
type: INNER_JOIN,
left: BoundBaseTableRef {
table: "student",
alias: "s",
oid: 1,
schema: [id:INTEGER, name:VARCHAR, age:INTEGER]
},
right: BoundBaseTableRef {
table: "enrollment",
alias: "e",
oid: 2,
schema: [sid:INTEGER, course:VARCHAR]
},
condition: BoundBinaryOp {
op_type: EQUAL,
left: BoundColumnRef { col_name: "id", table_oid: 1, col_idx: 0 },
right: BoundColumnRef { col_name: "sid", table_oid: 2, col_idx: 0 }
}
},
where_: BoundBinaryOp {
op_type: GREATER_THAN,
left: BoundColumnRef { col_name: "age", table_oid: 1, col_idx: 2 },
right: BoundConstant { value: 18, type: INTEGER }
},
limit_: BoundConstant { value: 10, type: INTEGER }
}
Planner
綁定好物件之後就會交給 planner,planner 的作用是將綁定好的 AST 轉換成執行計劃 (PlanNode)。
Planner 的 PlanQuery() 函數會將 Binder 轉換為 PlanNode,這是一個樹狀結構,表示 SQL 語句的執行計劃。
以上面的 SQL 為例,轉換後的執行計劃可能會長這樣 :
LimitPlanNode {
limit_: 10,
child_: ProjectionPlanNode {
expressions_: [
ColumnValueExpression { col_idx: 0 }, // s.id
ColumnValueExpression { col_idx: 1 }, // s.name
ColumnValueExpression { col_idx: 4 } // e.course (after join)
],
output_schema_: Schema([id:INTEGER, name:VARCHAR, course:VARCHAR]),
child_: FilterPlanNode {
predicate_: ComparisonExpression {
op_: GREATER_THAN,
left_: ColumnValueExpression { col_idx: 2 }, // s.age
right_: ConstantValueExpression { value: 18 }
},
child_: NestedLoopJoinPlanNode {
join_type_: INNER,
join_predicate_: ComparisonExpression {
op_: EQUAL,
left_: ColumnValueExpression { col_idx: 0 }, // s.id
right_: ColumnValueExpression { col_idx: 3 } // e.sid
},
output_schema_: Schema([id:INTEGER, name:VARCHAR, age:INTEGER, sid:INTEGER, course:VARCHAR]),
left_child_: SeqScanPlanNode {
table_oid_: 1, // student table
output_schema_: Schema([id:INTEGER, name:VARCHAR, age:INTEGER])
},
right_child_: SeqScanPlanNode {
table_oid_: 2, // enrollment table
output_schema_: Schema([sid:INTEGER, course:VARCHAR])
}
}
}
}
}
Optimizer
接著就會交給 optimizer 來優化執行計劃,這裡 bustub 採用的是 rule-based 的方式,也就是它會一條一條規則的套用到執行計劃上。
Optimizer 的 Optimize() 函數會檢查這些規則並套用到 PlanNode 上,比如說我們要實作的 OptimizeNLJAsIndexJoin。
以上面的 SQL 為例,優化後的執行計劃可能會長這樣,改成使用 NestedIndexJoin 並做了 predicate pushdown :
LimitPlanNode {
limit_: 10,
child_: ProjectionPlanNode {
expressions_: [
ColumnValueExpression { col_idx: 0 }, // s.id
ColumnValueExpression { col_idx: 1 }, // s.name
ColumnValueExpression { col_idx: 4 } // e.course
],
child_: NestedIndexJoinPlanNode {
outer_child_: FilterPlanNode {
predicate_: ComparisonExpression { op: GT, left: age, right: 18 },
child_: SeqScanPlanNode { table: "student" }
},
key_predicate_: ColumnValueExpression { col_idx: 0 }, // s.id
inner_table_oid_: 2,
index_oid_: 5,
index_name_: "enrollment_sid_idx"
}
}
}
Executor
最後就是交給 executor 來將 PlanNode 轉換成對應的 Executor,這裡 bustub 採用的是 pull-based 的 volcano model,也就是每個 Executor 都有 Init() 跟 Next() 兩個方法,並且上層的 Executor 會不斷呼叫下層的 Executor 的 Next() 來取得資料直到回傳 false 為止。
Executor 的入口點在 src/execution/executor_engine.cpp,它會呼叫 ExecutorFactory::CreateExecutor() 來遞迴地針對不同種類的 PlanNode 創建對應的 Executor。
同時它也會呼叫 Init() 來初始化整個 executor 樹,最後呼叫 PollExecutor() 來不斷的 pull 資料直到沒有資料為止。
除此之外,ExecutorContext 也會在這個時候被創建,它包含了 Transaction、Catalog、BufferPoolManager 等等執行時需要的物件。
Storage Structure
在了解了整個 SQL 的執行流程之後,我們還需要了解一下資料庫中的結構以及這些結構是如何被儲存的。
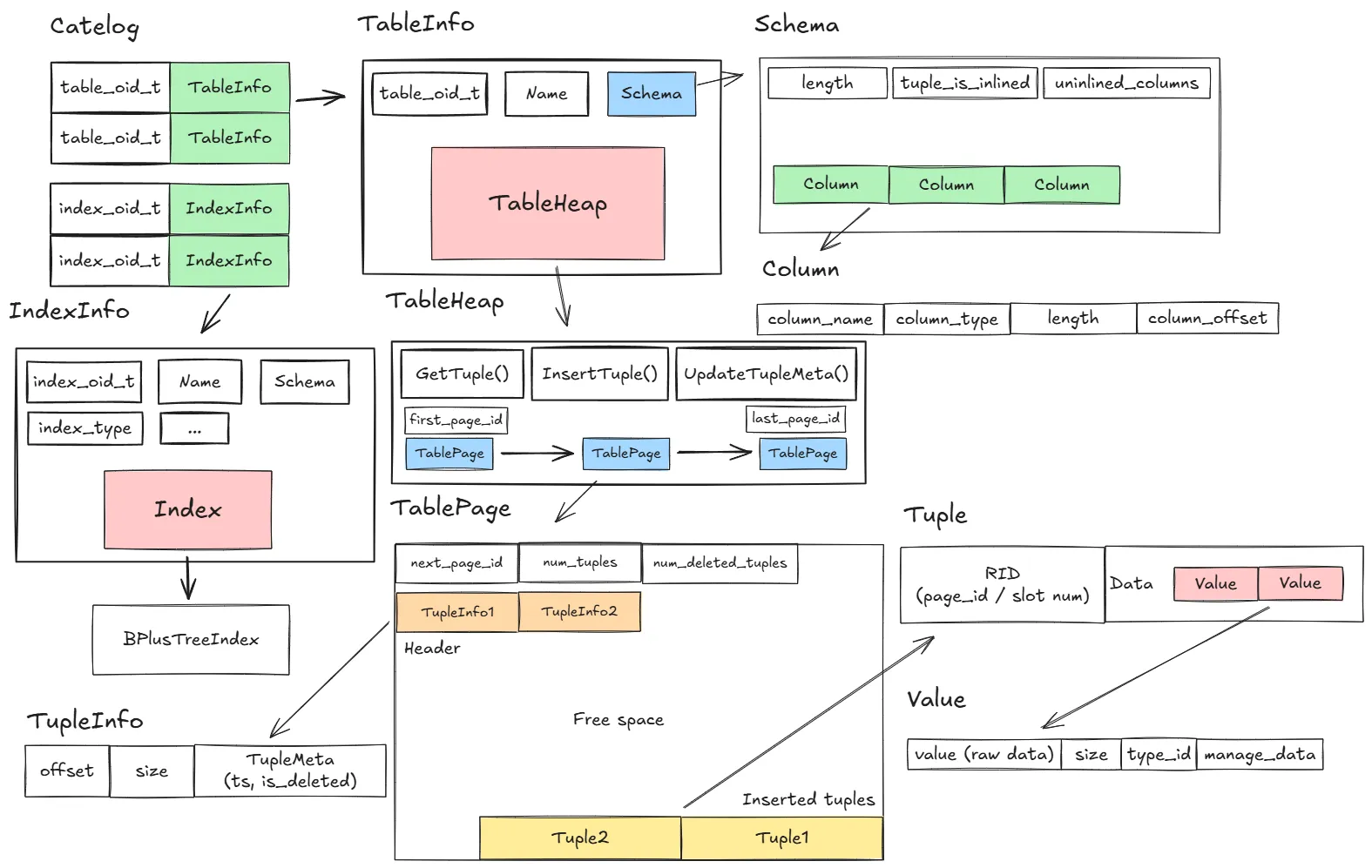
Catalog: 最頂層的結構,負責管理資料表跟索引,有CreateTable()、GetTable()、CreateIndex()、GetIndex()等等方法TableInfo: 代表一個資料表,包含了Schema、TableHeap、TableOid、Name等等資訊IndexInfo: 代表一個索引,包含了Schema、Index、IndexOid、Name等等資訊TableHeap: 代表 page 的儲存結構,維護first_page_id_跟last_page_id_方便插入跟查詢資料,同時提供了很多很有用的方法,例如InsertTuple()、GetTuple()、UpdateTupleMeta()、UpdateTupleInPlaceWithLockAcquired()TablePage: 代表一個 page,採用 slotted-page 的結構來儲存 tupleTuple: 代表一筆資料,包含了RID(由 page id / slot num 組成) 跟data,data裡面有多個Value,Value可以代表不同的資料型態TupleInfo: 代表 tuple 在 page 中的 offset 跟 size 以及TupleMeta,TupleMeta包含了is_deleted_跟ts_(timestamp)Schema: 代表資料表的 schema,包含了多個ColumnColumn: 代表一個欄位,包含了欄位名稱、欄位類型、欄位長度等等資訊
在 executor 中,如果我們要讀取資料表的資料,通常會要通過 exec_ctx_->GetCatalog() 先取得 Catalog,然後再繼續往下取得 TableInfo、TableHeap 等我們需要的資訊。
整體來說單一的函數實作起來難度應該不是太高,所以下面我就簡單說明一下流程跟一些可能會用到的方法就好。
Task 1 - Access Method Executors
SeqScan
使用 TableIterator 來掃描,注意跳過被刪除的資料跟 WHERE 條件,可以用 Evaluate() 來判斷 WHERE 條件。
Insert
除了 TableHeap::InsertTuple() 之外,還需要新增索引,可以用 InsertEntry() 來新增索引,key 可以用 KeyFromTuple() 來取得。
需要注意要有一個參數負責記錄之前有沒有回傳過結果了,因為上層會不斷呼叫 Next(),如果已經回傳過結果了就要回傳 false,包括後面的一些 executor 也是一樣。
Update
先把舊的 TupleMeta 使用 UpdateTupleMeta() 標記為刪除,接著把 index 刪除,然後再插入新的 tuple 並插入新的索引。
Delete
沒啥特別好說的,就是把 TupleMeta 標記為刪除,然後刪除索引。
IndexScan
用 pred_keys_ 判斷是點查詢還是範圍查詢,如果是點查詢就用 ScanKey() 查詢每一個 key,如果是範圍查詢就直接用 B+ tree 的迭代器來掃描。
IndexScan Optimizer
首先要先遞迴來遍歷整個 AbstractPlanNodeRef,接著檢查是不是 seq_scan + filter 的組合,並看看有沒有 index 可以用。
有三種情況要處理 :
SELECT * FROM t1 WHERE v1 = 1;
SELECT * FROM t1 WHERE 2 = v1;
SELECT * FROM t1 WHERE v1 = 1 OR v1 = 2;
對於前兩種情況,我們需要檢查謂詞是否為 ComparisonExpression,且比較類型為 Equal。
接著檢查左右子節點,確保一邊是 ColumnValueExpression (變數),另一邊是 ConstantValueExpression(常數)。
再來檢查 ColumnValueExpression 的 col_idx 是否與某個可用索引的第一個鍵值欄位相符。
最後檢查 GetTupleIdx() == 0,這個檢查確保了這個欄位屬於當前正在掃描的這張表。
對於第三種情況,我們需要遞迴地分析。
如果表達式是一個 LogicExpression 且邏輯類型是 LogicType::Or,那麼我們就遞迴地對其左右子表達式應用前兩種情況的判斷邏輯。
Task 2 - Aggregation & Join Executors
Aggregation
首先要完成 CombineAggregateValues 中幾種函數的實作,這部分比較簡單,主要是要注意 NULL 的處理。
這個 executor 是一個 pipeline breaker,所以在 Init() 的時候就要把所有資料都讀進來並計算好結果,可以利用 MakeAggregateKey、MakeAggregateValue 並丟到 InsertCombine() 來做。
最後輸出的時候要把 AggregateKey 跟 AggregateValue 的條件也一起輸出方便上面的 Projection 使用。
需要特別處理 empty input 的情況,可以呼叫 GenerateInitialAggregateValue() 來產生初始值。
NestedLoopJoin
需要處理 INNER JOIN 跟 LEFT JOIN 兩種情況。
這裡我的做法是先讀左邊的一個 tuple,然後重新 Init() 右邊的 executor,接著不斷呼叫右邊的 Next() 並用 EvaluateJoin 來判斷有沒有符合條件,如果有就把兩個 tuple 合併起來並回傳。
如果是 LEFT JOIN 的話,當右邊的 executor 掃描完之後還沒有找到符合條件的 tuple,就要回傳左邊的 tuple 並把右邊的欄位設為 NULL,可以使用 ValueFactory::GetNullValueByType() 來產生 NULL。
NestedIndexJoin
整體邏輯跟 NestedLoopJoin 差不多,差別在於右邊的 executor 是一個 IndexScan,所以每次讀左邊的 tuple 之後要用 KeyPredicate 來生成 probe key。
Task 3 - HashJoin Executor and Optimization
HashJoin
這個 task 要做的事情還蠻多的,除了 Init() 跟 Next() 之外,還要實作針對 std::vector<Value> 的 hash 方法。
我實作了一個 JoinKey 的 class 來代表 join key,並且實作了 operator== 跟 std::hash 來讓它可以被 hash,這部分可以大致參考 AggregationPlanNode 的實作。
在 Init() 的時候可以先把一邊的資料都讀進來並建立 hash table,我的儲存方式是 std::unordered_map<JoinKey, std::vector<Tuple>>。
在 Next() 的時候就不斷讀另一邊的資料,然後用 join key 去 hash table 裡面找有沒有符合的 tuple,如果有就把兩個 tuple 合併起來並回傳,需要特別處理一對多的情況。
HashJoin Optimizer
有兩種情況可以優化成 HashJoin :
SELECT * FROM t1 JOIN t2 ON t1.v1 = t2.v1;
SELECT * FROM t1 JOIN t2 ON t1.v1 = t2.v1 AND t1.v2 = t2.v2;
首先,跟其他 optimizer 一樣需要先把樹遞迴到底在開始。
對於第一種情況來說,需要檢查掃描方法是不是 NestedLoopJoin 且是透過 ComparisonType::Equal 跟 ColumnValueExpression 來 join 的,接著再確定他們是不是來自不同的 table。
對於第二種情況來說,還需要考慮 AND 的情況,可以用遞迴的方式來檢查 LogicExpression 是不是 LogicType::And,然後檢查左右子節點符不符合第一種情況的條件。
Task 4 - External Merge Sort + Limit Executors
External Merge Sort
首先要實作 TupleComparator::operator() 來比較兩個 tuple 的大小,這部分可以用 Value 裡面的 CompareEquals()、CompareLessThan() 來比較大小,要區分 ASC (DEFAULT) 跟 DESC。
接著實作 GenerateSortKey() 來產生排序的 key,可以用 MakeKeyFromTuple() 來產生。
然後需要實作 SortPage 跟 MergeSortRun 來代表硬碟上的 page 以及一個邏輯上的 run,可以自行依據需求寫一些 helper function。
在我自己的實作中,SortPage 會包含一個成員 char data_[BUSTUB_PAGE_SIZE],這個成員的前 4 個 byte 會用來記錄這個 page 裡面有多少個 tuple,剩下的空間就用來放 tuple 的資料。
這邊有兩個問題要注意,第一個是要在 MergeSortRun 中的 Iterator 保留上一次讀取的 ReadPageGuard,不然測試很容易超時。
第二個是如果遇到了 test incurred 0 times of disk deletion, which is too low 的錯誤訊息,代表有可能在 project 1 的時候就沒有正確使用 disk_scheduler_->DeallocatePage() 導致它抓不到 page 的刪除次數。
最後就是實作真正的 ExternalMergeSortExecutor 了,這裡我實作了 4 個 helper function 來分別處理不同的階段 :
CreateInitialRuns(): 從 child executor 拉 tuple,組成<sort_key, tuple>的 pair,滿一個 page 的大小就呼叫FlushRunToDisk()來把這些 tuple 排序並寫到硬碟上FlushRunToDisk(): 把一個 run 的 tuple 排序並寫到硬碟上,這裡可以用std::sort()來排序,並寫入到SortPage中最後把 page_id 記錄起來並塞回硬碟中MergeRuns(): 每次取出兩個 page 並呼叫MergeTwoRuns()來合併成一個新的 run,最後回傳新的 run 的 page_idMergeTwoRuns(): 運用兩個 iterator 來將兩個MergeSortRun合併成一個新的MergeSortRun
同時這個 executor 也是一個 pipeline breaker,所以在 Init() 的時候就要把所有資料都讀進來並排序好,最後在 Next() 的時候只需要不斷地從排序好的 run 中讀取 tuple 並回傳。
Limit
這應該是最簡單的 executor,只需要在 Next() 的時候計數,當超過 limit 的數量就回傳 false。
Submit
如果要執行 SQL,可以使用以下指令或是到這個網站上執行 :
make -j$(nproc) shell && ./bin/bustub-shell
測試的方式有點麻煩,要自己一個一個試 :
make -j$(nproc) sqllogictest && \
./bin/bustub-sqllogictest ../test/sql/p3.05-index-scan-btree.slt --verbose
make format && make check-format && make check-lint && make check-clang-tidy-p3
make submit-p3
Takeaways
這個 project 做起來其實蠻無聊的,因為大部分都是照著規格一步一步實作就好,沒有什麼特別的技巧,不過因為要看的東西不少,所以還是花了我蠻多時間的。
對於想要快速通關的人來說我覺得 AI 在這個 project 上面應該可以幫助很大,但要注意一定要能理解 AI 幫你寫的東西,因為下一個 project 會需要在這個 project 的基礎上繼續實作。