P1 - Buffer Pool Manager
在這個 project 中,我們需要實現一個 buffer pool manager,總共有 3 個 task :
- LRU-K Replacement Policy
- Disk Scheduler
- Buffer Pool Manager
我採取的做法都是只求通過不求效能,如果想要進行效能優化,可以參考最下方 References 中的文章。
Background
這個 project 就是要實作 buffer pool manager,主要是負責把硬碟上的 page load 到記憶體中,並且提供一個介面讓上層可以讀取 / 寫入 page。
在開始之前,我們可以先來看一下 bustub 的 IO 架構圖 :
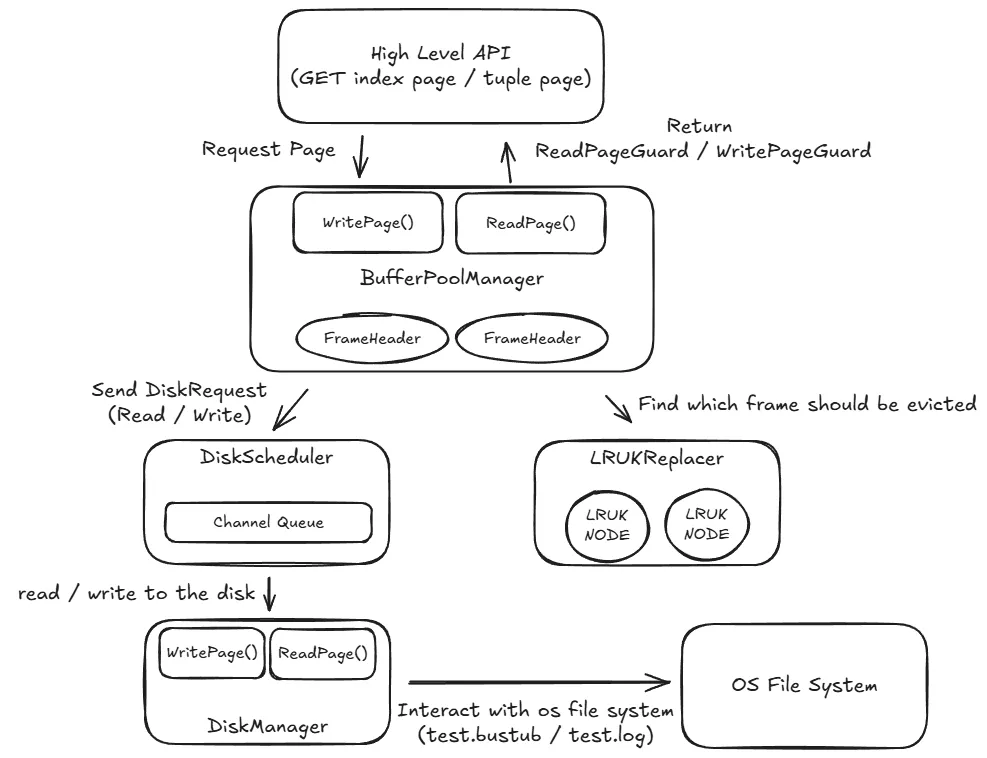
用文字來描述的話,大致流程如下 :
- 上層呼叫
BufferPoolManager的 API 來獲得PageGuard BufferPoolManager會先檢查 page 是否在 buffer pool 中,並把 metadata 放在FrameHeader中 (包含 pin_count、is_dirty 等等)- 如果 page 不在 buffer pool 中,
BufferPoolManager會先檢查 free list 是否有空間,如果沒有的話就呼叫LRUKReplacer來找一個 page 來 evict,LRUKReplacer會根據LRUKNode中的歷史紀錄來決定要 evict 哪個 page - 如果要 evict 的 page 是 dirty 的話 (或其他需要 flush 的情況),就會傳送一個
DiskRequest給DiskScheduler,DiskScheduler會把 request 放到 queue 中,並由背景的 worker thread 來處理 - 接著 worker thread 會呼叫
DiskManager來讀取 / 寫入資料到硬碟
Task 1 - LRU-K Replacement Policy
Task 1 的目標是實現 LRU-K replacement policy,主要包括 LRUKReplacer 跟 LRUKNode 兩個 class。
基本上就是維護 node_store_ 跟 LRUKNode 中的 history_ 就好,可以順便對 LRUKNode 寫一些 get function 來方便取得資料。
LRU-K 的邏輯如下 :
- 當一個 page 被 access 的時候,就會把當前的 timestamp 加到
history_中,當history_的大小超過 K 的時候,就會把最早的 timestamp 移除 - 當要 evict 的時候,會先找出所有
IsEvictable的 node,然後分成兩組,一組是history_中有 K 個 timestamp 的,另一組是不滿 K 個的 - 會優先排除不滿 K 個 timestamp 的 node,找出這組中最後一個 timestamp 最早的 node 來 evict
- 如果所有 node 都滿 K 個 timestamp 的話,就在這組中找出最後一個 timestamp 最早的 node 來 evict
實作上大致如下,其實都非常直觀,沒有特別需要注意的地方 :
Evict: 主要是實作上面提到的邏輯RecordAccess: 更新history_中的資料SetEvictable: 判斷IsEvictable的情況並刪除即可Remove: 檢查IsEvictable之後就可以直接刪除Size: 直接回傳curr_size_
Task 2 - Disk Scheduler
Task 2 的目標是實現 disk scheduler,主要是要實作 DiskScheduler 中的兩個 function :
Schedule: 只需要將 r 丟到request_queue_中即可StartWorkerThread: 設計一個 while 迴圈並執行 request,最後再設定 callback 為 true 即可,拿到std::nullopt就可以跳出迴圈
以及要注意註解掉建構子中的 throw error,這樣才能正常執行 test。
Task 3 - Buffer Pool Manager
Task 3 的目標是實作 buffer pool manager,主要會用到的 class 有 PageGuard、BufferPoolManager、FrameHeader。
這個 task 相對於前兩個要花蠻多時間思考的,我認為可以先思考在單線程下的邏輯,最後再來處理有關鎖的問題。
PageGuard 是一個可以對 frame 進行讀寫的 class,分成 ReadPageGuard 跟 WritePageGuard 兩個 class,只有拿到 PageGuard 才能對 frame 進行讀寫,如 WritePageGuard::GetDataMut() 會回傳可修改的 char[]。
同時,這個 class 還需要搭配 FrameHeader 中的 rwlatch_ 來確保多線程下的安全性,我們會在後面討論這個部分。
兩個 class 的邏輯大致相同 (只有鎖的種類不同而已),這裡以 ReadPageGuard 為例,主要包含以下幾個 function :
ReadPageGuard: 取得 frame_->rwlatch 的鎖,並把 is_valid 設定為 trueReadPageGuard(ReadPageGuard &&that):PageGuard只能被 move 不能被 copy (這是為了避免資源管理上的問題),所以我們需要實作 move constructor,主要是把 that 的資料搬過來,然後把 that 的 is_valid 設定為 falseoperator=: 類似前面Drop: 先檢查 is_valid 是否為 true,如果是的話處理 pin_count 跟 SetEvictable 的情況,然後再把 is_valid 設定為 false
BufferPoolManager 則是用來管理 buffer pool 的 class,主要維護 page 跟 frame 的對應關係 (page_table_),除此之外也包含了 replacer_ 跟 disk_scheduler_ 來做頁面替換以及硬碟的讀寫。
主要需要實作的 function 如下 :
NewPage: 把next_page_id+1 之後使用disk_scheduler_->IncreaseDiskSpace新增 page 即可DeletePage: 先確定這個 page 有在page_table中,接著再檢查 pin_count 是否為 0,然後再檢查 is_dirty 看是否需要 FlushPage,最後再呼叫FrameHeader->Reset即可CheckedWritePage&CheckedReadPage: 這兩個函數是這個 task 最重要的函數,實作上也非常類似,主要邏輯如下 :- 如果這個 page 已經在 buffer pool 中了,那就要更新它的 metadata (pin_count, evictable, recordaccess)
- 如果
page_id不在 buffer pool 中,但是free_frame中有空間,那就可以 pop_front 一個 frame,然後更新 metadata - 如果
page_id不在 buffer pool 中,且free_frame也沒有空間,那我們就要使用replacer_來 evict 一個 frame,然後一樣更新 metadata
FlushPage: 檢查page_id是否在page_table中,然後檢查is_dirty,可以使用disk_scheduler_來把資料寫回硬碟,這個函數基本可以假設呼叫它的人都有 bpm 鎖,所以不需要再獲取FlushAllPages: 遍歷page_table中的資料,然後使用FlushPage來寫回硬碟GetPinCount: 檢查page_id是否在page_table中,然後回傳pin_count
討論完基本功能之後就可以開始思考 concurrency 的問題。 這個 task 有兩個鎖,一個是 bpm 的鎖,另一個是 frame 的鎖,我們需要確保這兩個鎖在使用上不會發生 deadlock。
這部分我覺得 這篇文章 有很詳細的說明,我也是參考這篇文章的做法來實作,這裡就簡單說明一下。
這篇文章列出了三個需要注意的地方 :
pin_count_跟rwlatch_的順序要遵守 pin -> lock -> unlock -> unpin 的順序- 用
bpm_latch_保護pin_count_跟SetEvictable的更新 - 獲取
rwlatch_的時候不能同時持有bpm_latch_
有關於第一點可以用反例來說明。 如果順序是先 lock 在 pin 的話,代表順序如下 :
- T1 拿到 frame 0 的鎖
- T1 執行
pin_count_++ - T1 做了一些事情後,
pin_count-- - T1 放掉 frame 0 的鎖
- T2 拿到 frame 0 的鎖
仔細思考的話可以發現,T1 在第 3 步驟的時候,pin_count_ 可能會變成 0,代表這段時間開始到 T2 拿到鎖之前,這個 frame 可能會被 evict 掉,導致 T2 拿到的 frame 是已經被 evict 掉的 frame。
第二點理解起來比較簡單,就是因為 pin_count_ 跟 is_evictable_ 需要是原子操作,所以需要用 bpm_latch_ 來保護。
第三點可以用測試案例 DeadlockTest 來解釋,這個測試如下 :
TEST(BufferPoolManagerTest, DeadlockTest) {
auto disk_manager = std::make_shared<DiskManager>(db_fname);
auto bpm = std::make_shared<BufferPoolManager>(FRAMES, disk_manager.get(), K_DIST);
auto pid0 = bpm->NewPage();
auto pid1 = bpm->NewPage();
auto guard0 = bpm->WritePage(pid0);
// A crude way of synchronizing threads, but works for this small case.
std::atomic<bool> start = false;
auto child = std::thread([&]() {
// Acknowledge that we can begin the test.
start.store(true);
// Attempt to write to page 0.
auto guard0 = bpm->WritePage(pid0);
});
// Wait for the other thread to begin before we start the test.
while (!start.load()) {
}
// Make the other thread wait for a bit.
// This mimics the main thread doing some work while holding the write latch on page 0.
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
// If your latching mechanism is incorrect, the next line of code will deadlock.
// Think about what might happen if you hold a certain "all-encompassing" latch for too long...
// While holding page 0, take the latch on page 1.
auto guard1 = bpm->WritePage(pid1);
// Let the child thread have the page 0 since we're done with it.
guard0.Drop();
child.join();
}
先簡單敘述一下這個 Test 的邏輯,首先主執行緒會先取得 frame 0 的獨佔鎖,接著啟動一個子執行緒也來讀取 frame 0 的獨佔鎖,這時候主執行緒會先睡 1 秒鐘,然後再取得 frame 1 的獨佔鎖,最後主執行緒再釋放 frame 0 的獨佔鎖。
如果我們直接在 CheckedWritePage 中使用 std::scoped_lock 來鎖住 bpm 的鎖,那麼這個測試就會死鎖,流程如下 :
- 主執行緒取得 bpm 的鎖
- 主執行緒取得 frame 0 的獨佔鎖
- 主執行緒放棄 bpm 的鎖
- 子執行緒取得 bpm 的鎖
- 子執行緒等待 frame 0 的獨佔鎖
- 主執行緒等待 bpm 的鎖 (準備讀取 frame 1)
- 由於兩邊都在等待對方的鎖,所以就會死鎖
由上面的範例我們可以知道,我們必須要在取得 frame 的鎖之前放掉 bpm 的鎖,這樣才能避免死鎖的問題。
但這樣還有一個疑惑是,假設我們在取得 frame 的鎖之前放掉 bpm 的鎖,那麼在這段時間內,其他的執行緒就有可能會插隊,這樣會不會導致我們取得的 frame 不是我們想要的 frame 呢?
答案是不會,因為我們會在持有 bpm 的鎖的時候就更新 pin_count_ 跟 is_evictable_,所以即使其他執行緒插隊也不會導致我們要的 frame 被 evict 掉,只是會在執行順序上有些不同而已。
綜合以上的三個限制,我在實作上採取的方法是在 CheckedWritePage 中使用 std::unique_lock 來取得 bpm 的鎖,接著在創建 WritePageGuard 前解鎖,然後在 WritePageGuard 的 constructor 取得 frame 的鎖,最後在 Drop() 的時候先釋放 frame 的鎖,再使用 bpm 的鎖更新 frame 的 metadata。
Submit
make lru_k_replacer_test -j$(nproc) && ./test/lru_k_replacer_test
make disk_scheduler_test -j$(nproc) && ./test/disk_scheduler_test
make page_guard_test -j$(nproc) && ./test/page_guard_test
make buffer_pool_manager_test -j$(nproc) && ./test/buffer_pool_manager_test
make format && make check-format && make check-lint &&make check-clang-tidy-p1
make submit-p1
Takeaways
第一次寫這個作業的時候還是 2023 fall 的版本,想說改成 2024 fall 的版本應該一天就可以了,結果竟然花了一個禮拜才弄完 🫠
主要是因為新增的 PageGuard 導致實作上跟原本的差的有點多,但我相信這個 class 應該會讓後面的 project 實作上更簡單 (吧?)