Introduction to Distributed Databases
Distributed DBMS 是一種將單一邏輯資料庫分散到多個物理資源上的系統,跟 parallel DBMS 的差異在於分散式的節點相對距離較遠,且可能要通過公共網路進行通信。
在此之前,我們已經學過了許多在 single node 環境下的資料庫技術,如 :
- Optimization & Planning
- Concurrency Control
- Recovery
而這些技術在分散式系統中都會有不同的挑戰,也是這篇要討論的主題。
System Architecture
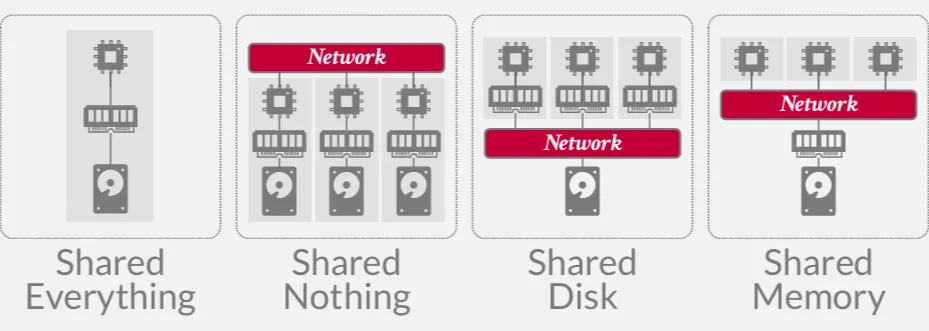
DBMS 的 system architecture 定義了 CPU 可以直接訪問那些共享資源,其中 single node 的架構就是 shared everything,而在分散式系統中,我們主要討論的是另外三種架構 :
- Shared Memory : 不同的 CPU 可以訪問同一個記憶體位置,這種架構幾乎沒有人使用
- Shared Disk : 不同的 CPU 可以透過網路訪問同一塊邏輯硬碟,但各自有各自的記憶體
- Shared Nothing : 每個節點都有自己的 CPU、Memory、Disk,節點之間會透過網路來通信。缺點是較難確保一致性,較難進行擴容
在分散式系統中,節點與節點之間的關係可以分為兩種 :
- Homogeneous (同質節點) : 每個節點在叢集中能夠執行相同的任務,在擴容以及故障恢復比較簡單
- Heterogeneous (異質節點): 節點被分配特定的任務,因此不同節點之間需要進行通信才能完成任務,可以在一個物理節點上執行多個虛擬節點
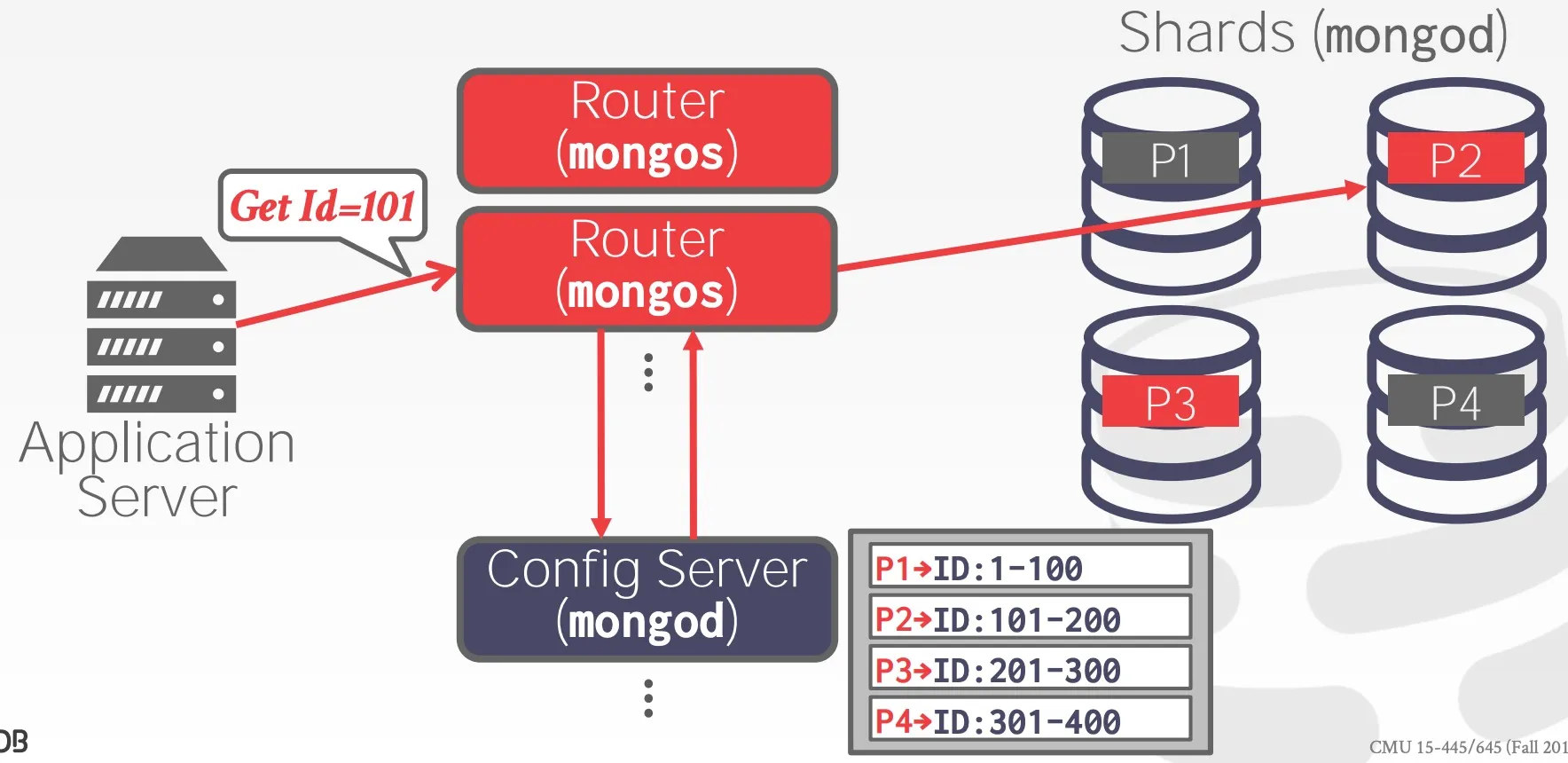
以 MongoDB 為例,它的集群有三種節點,分別是 Router、Config Server、Shard。 使用者會發送請求給 Router,Router 會根據 Config Server 的設定來將請求轉發給 Shard。
Partitioning Schemes
Partitioning Schemes 是一種把資料庫分散到多個節點上的方法,也常被稱作 sharding。
Naive Table Partitioning
假設一個節點有足夠的容量,我們可以讓一個節點儲存一張表,缺點是可能導致資料不均勻。
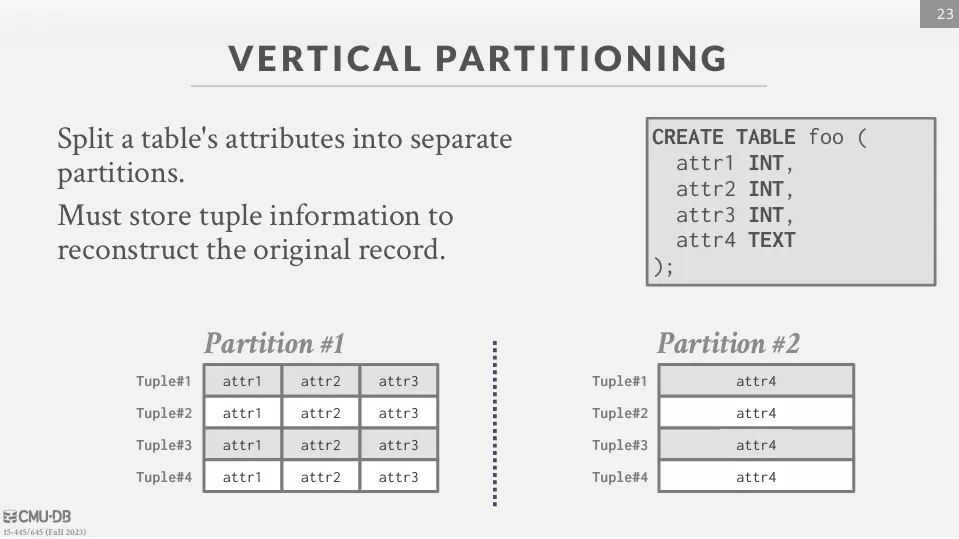
Vertical Partitioning
將表格的屬性拆分成不同的分區。每個分區必須儲存元組訊息,以便能夠重建原始記錄。
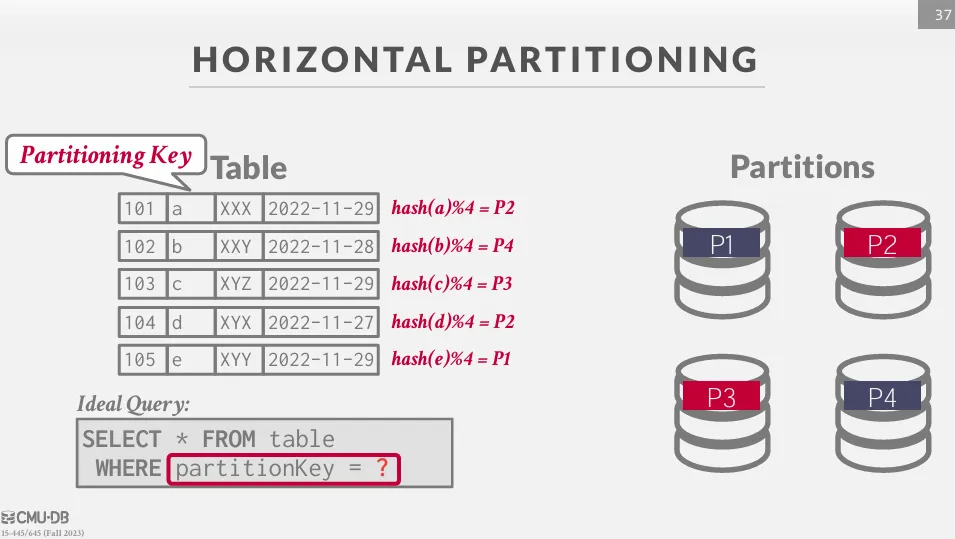
Horizontal Partitioning
將表的資料切成多個不相關的子集,並且找到一個 key 來將資料平均分配到不同的節點上,常見的分配方式有 :
- Range Partitioning
- Hash Partitioning
- Predicate Partitioning
通常會使用 partitionKey 來查詢資料。
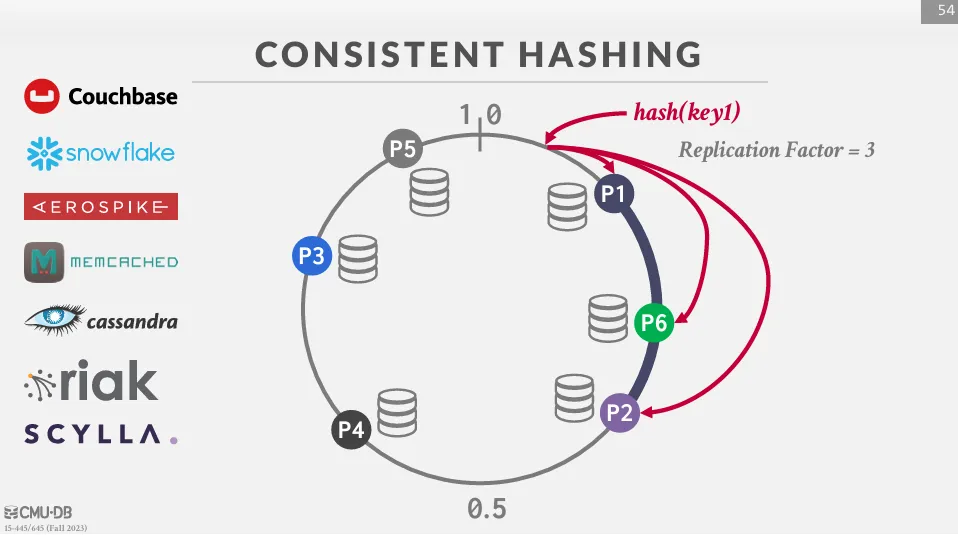
如果使用 hash partitioning,則可以使用 consistent hashing 來減少節點變動時的資料重新分配。
將每個 hash 值到邏輯環上的一個位置,然後由最接近該位置的節點 (順時針方向) 負責該鍵。 當一個節點被添加或移除時,只有相鄰的節點之間的鍵會被移動,並且只有 1/n 的鍵會被重新分配。 除此之外,我們也可以利用 consistent hashing 來做 replication。
Distributed Concurrency Control
在分散式系統中,交易會訪問一個或多個分區的資料,這時候就會需要複雜的協調,即所謂的 transaction coordination。
通常分為中心化和去中心化兩種方式。
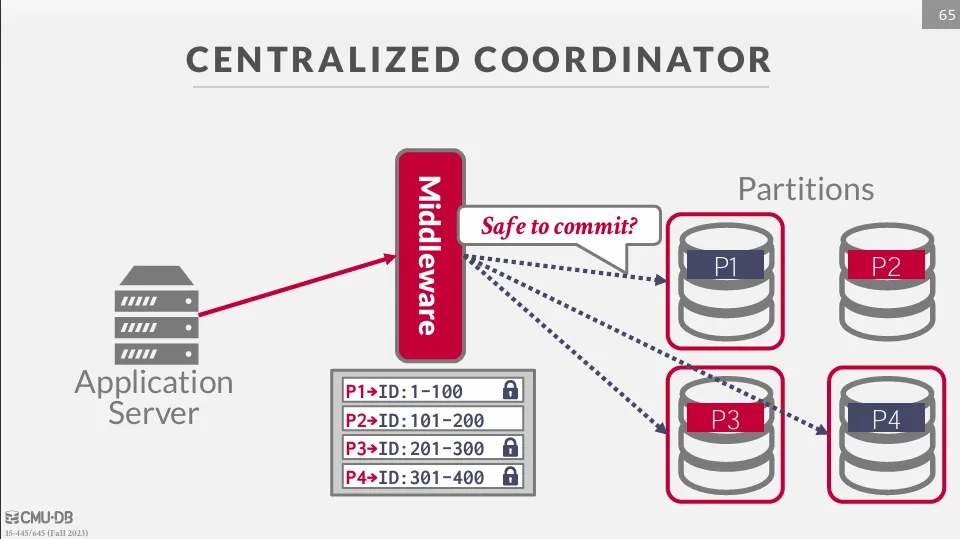
Centralized Coordinator
Transaction Processing Monitor (TP Monitor)
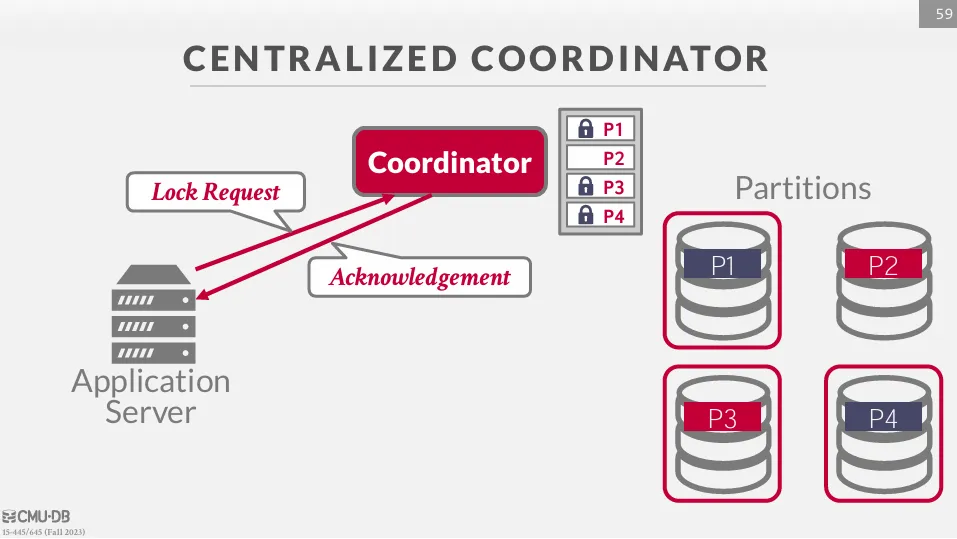
要實現中心化的協調就需要有一個元件來管理所有的交易,這個元件被稱作 Transaction Processing Monitor (TP Monitor)。 每次發送請求時,都要經過 TP Monitor 來進行協調。
舉例如下所示 :
假設一個 DBMS 有四個 partitions,分別是 P1、P2、P3、P4,並且有一個 TP Monitor 來管理所有的交易。 這時有一個交易需要修改 P1、P3、P4 上的資料,那麼它首先要向 TP Monitor 請求 P1、P3、P4 上的鎖
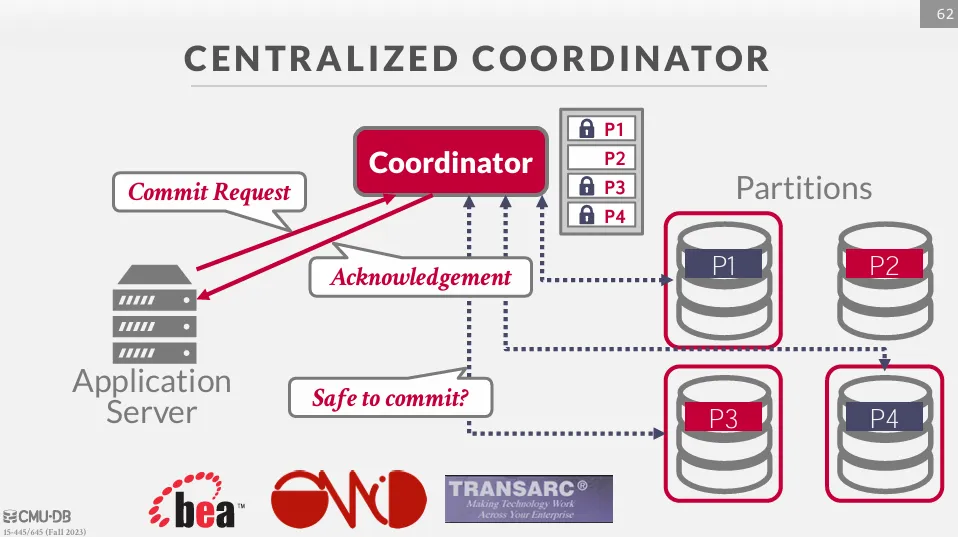
拿到鎖之後才能修改資料,修改完畢後再向 coordinator 發送 commit 請求,coordinator 會向所有的分區詢問這個交易是否可以 commit,最後返還 ACK 給使用者。
Middleware
這種 coordinator 可以被當成一個 middleware,負責協調所有的交易。
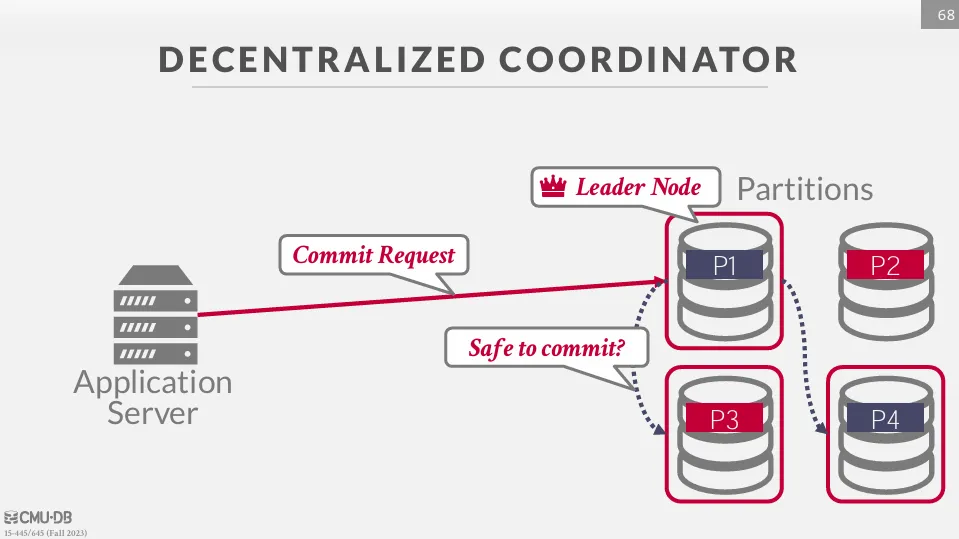
Decentralized Coordinator
再去中心化的架構中,執行某個交易時會選擇一個節點作為 master,負責協調所有的交易。
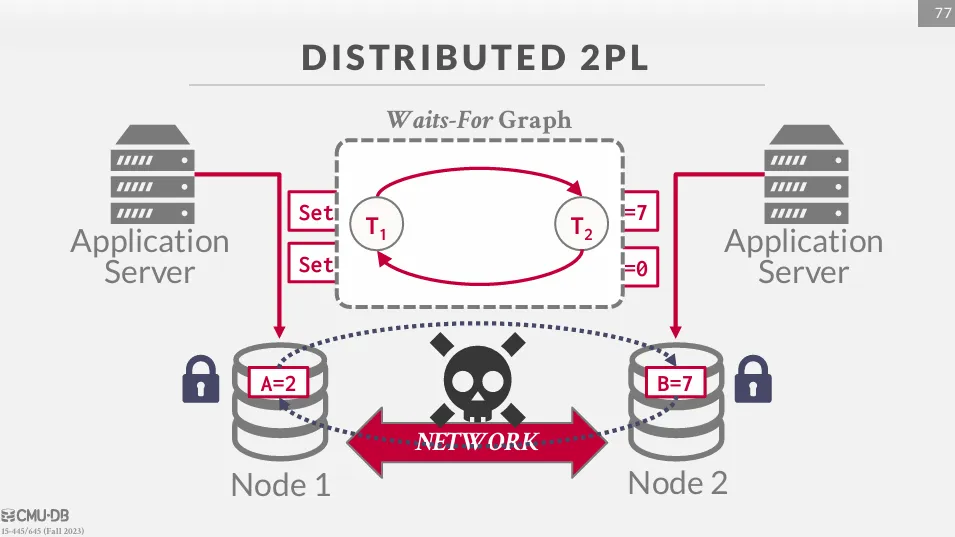
Distributed Concurrency Control
分散式的併發控制有很多挑戰,比如 :
- Replication
- Network Communication Overhead
- Node Failures
- Clock Skew
在下圖的例子中,我們可以看到由於沒有中心化的協調器,一旦發現如圖中的死鎖情況,就很難進行協調。
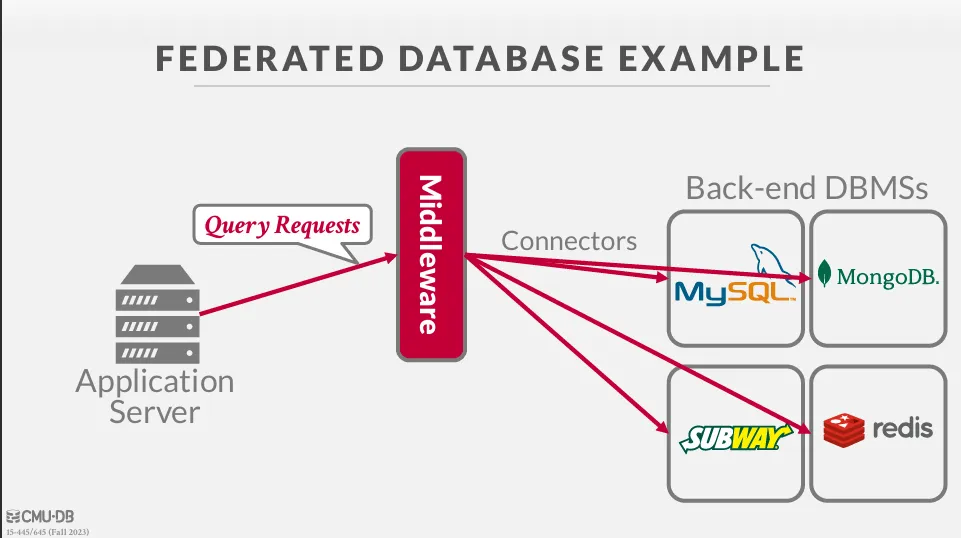
Federated Database
在前面的範例中,我們都假設資料庫是同一種的,但在實際應用中,我們可能會想要使用不同種類的資料庫,並只暴露一個統一的介面。
這種技術有很多的挑戰,像是 query optimization、data migration、data consistency,目前仍然沒有一個很好的解決方法。