Multi-Version Concurrency Control
這篇筆記會介紹 Multi-Version Concurrency Control (MVCC) 的概念及其實作細節。
Multi-Version Concurrency Control
多版本併發控制 (MVCC) 是一種廣泛應用於現代 DBMS 的技術,這種技術會透過維護資料庫中每個邏輯對象的多個物理版本來實現併發控制,允許同時讀寫操作而不互相阻塞。 當交易需要讀取資料時,只會讀到該交易開始之前的最新版本。
MVCC 涉及多個設計決策,這些決策會影響資料庫的性能、存儲需求以及如何處理不同的併發場景 :
- Concurrency Control Protocol : 可搭配 2PL (MV-2PL)、TO (MV-TO)、OCC 等方法
- Version Storage : 決定如何存儲和管理多個版本的資料
- Garbage Collection : 隨著時間的推移,某些舊版本的資料變得無用,因此需要有一個機制來清理這些版本
- Index Management : 多版本的存在會對索引結構的設計造成挑戰,特別是如何快速找到正確版本的資料
- Deletes : 當刪除某個資料時,如何處理該資料的不同版本
Snapshot Isolation
快照隔離 (SI) 是基於 MVCC 的一種隔離級別。 每個交易在啟動時獲得一個一致性快照,只包含已提交的資料,並在整個執行期間與其他交易隔離。
- Read : 交易從快照中讀取數據,因此讀操作不會被其他交易的寫操作阻塞,這使得快照隔離特別適合只讀交易
- Write : 寫操作在交易的私有工作空間中進行,只有當交易成功提交後,這些更改才會對其他交易可見
- Write Conflicts : 如果兩個交易更新同一個對象,會以先提出的交易為主
- Write Skew Anomaly : 兩個交易分別修改不同的對象,最終可能導致非可序列化的調度,如下方的圖片範例
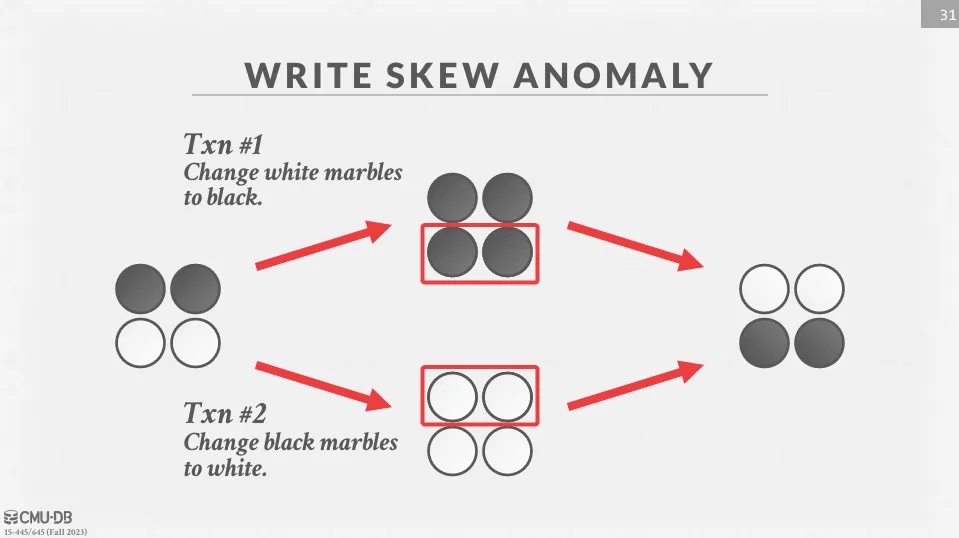
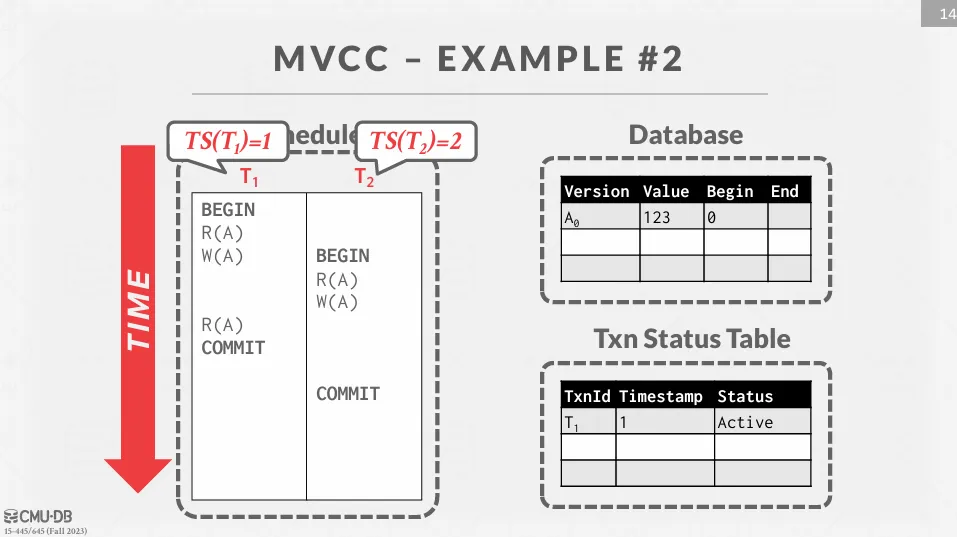
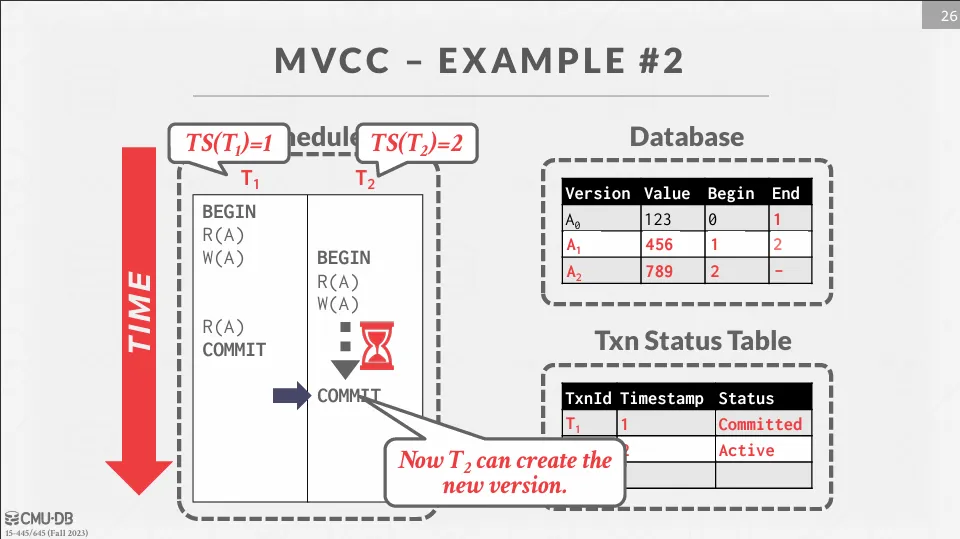
Example
先修改 ,創造一個新的版本 ,並將 的結束時間改成 1。
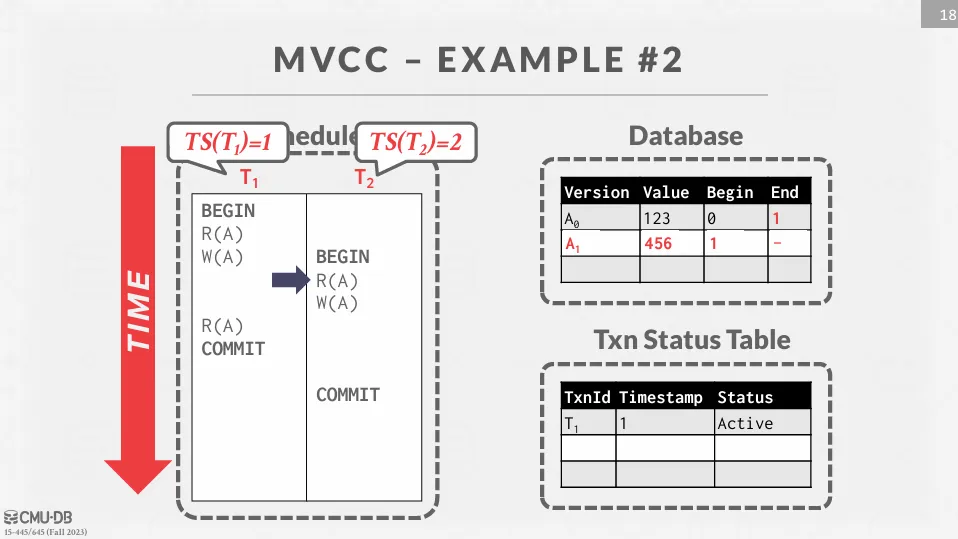
此時 想讀取 ,因為 還沒提交,所以 只能讀取 。
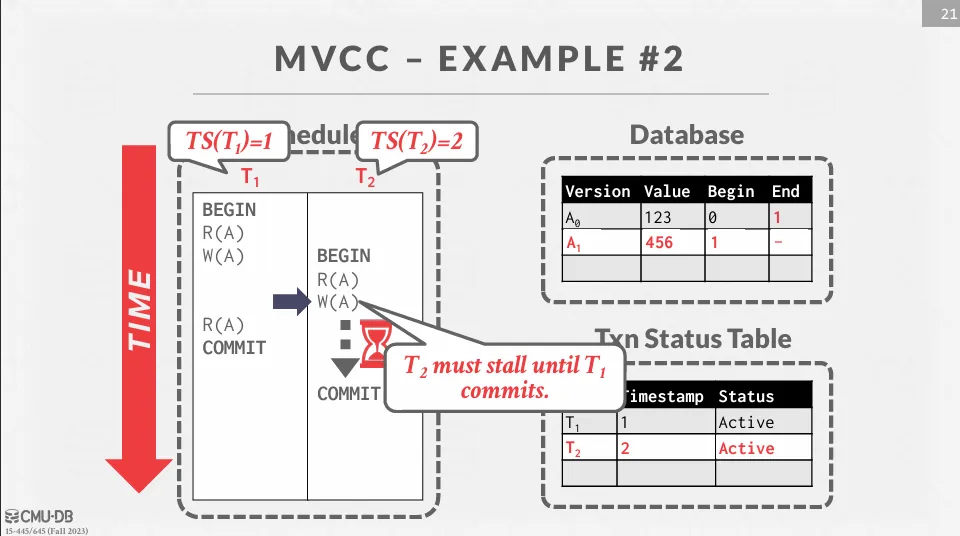
接著 想要修改 ,但是有另一個 active 的事務正在修改 ,所以 會被 block。
直到 commit 之後, 才能創建新的版本 ,並將 的結束時間改成 2。
Concurrency Control Protocol
可以使用前面所介紹過的併發控制方法 :
- Two-Phase Locking
- Timestamp Ordering
- Optimistic Concurrency Control
可以參考 這篇文章 來了解更多關於 MVCC 的併發控制協議。
Version Storage
在 MVCC 中,版本存儲決定了如何在資料庫中存儲同一邏輯對象的不同物理版本,以及交易在運行時如何找到對應的可見版本。
每個元組都會在資料庫中維護一個 version chain,這是一個根據時間戳排序的 linked list,每當一個對象被更新時,DBMS 會在鏈中添加一個新版本,相關的索引通常指向 head (最新或最舊的版本)。 在查詢時,DBMS 會遍歷版本鏈,直到找到對應交易可見的正確版本。
主要有以下三種方法來存儲版本 :
- Append-Only Storage
- Time-Travel Storage
- Delta Storage
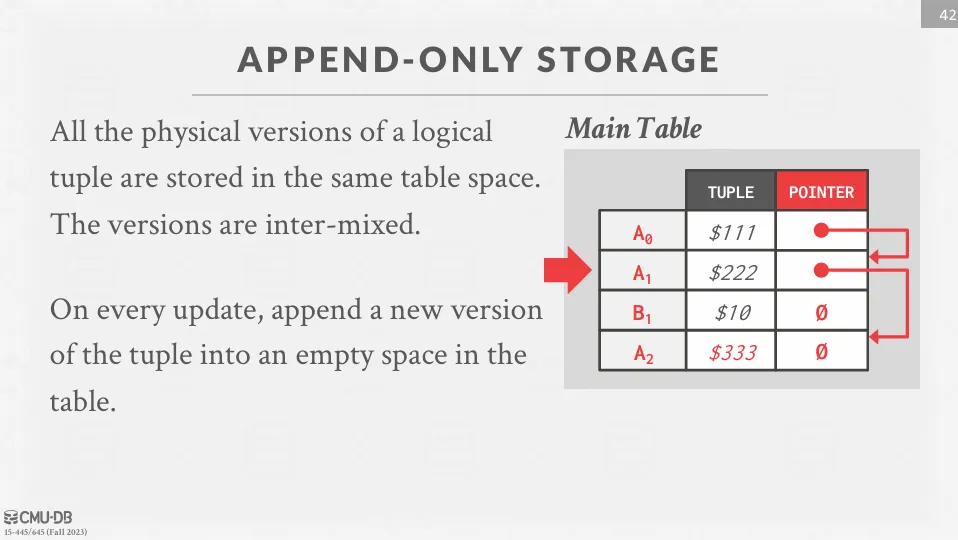
Append-Only Storage
所有元組的物理版本都存儲在同一個表中。每次更新時,DBMS 會將新的元組版本附加到表中,並更新版本鏈。
有兩種方向可以選擇 :
- Oldest-to-Newest (O2N) : 最舊的版本在前面,最新的版本在後面,查詢時需要遍歷整個鏈條
- Newest-to-Oldest (N2O) : 最新的版本在前面,最舊的版本在後面,每次插入新版本時,需要更新索引指針
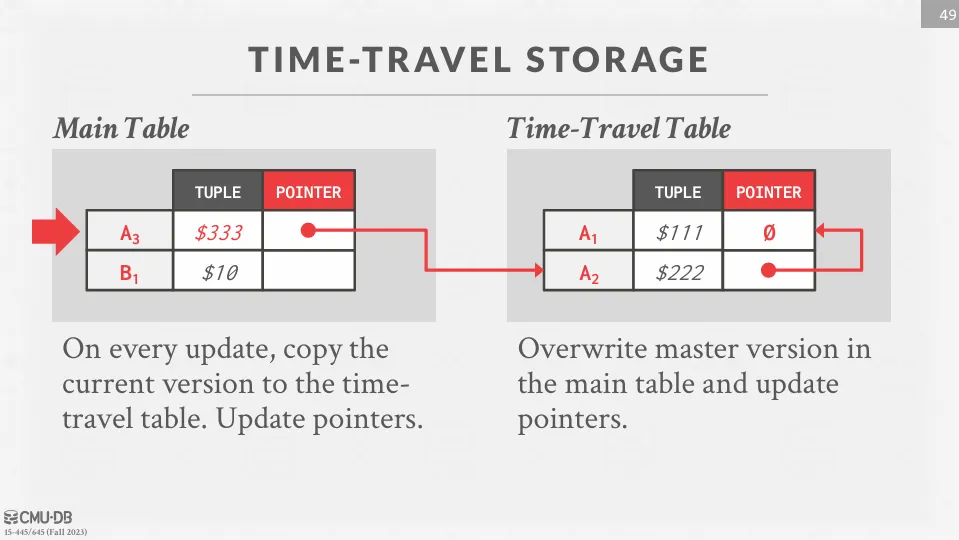
Time-Travel Storage
DBMS 維護一個獨立的 time travel table,用來存儲元組的舊版本。 每次更新時,DBMS 會將舊版本複製到 time travel table 中,並在主表中覆蓋元組為新版本,主表中的元組指向時間旅行表中的舊版本。
Delta Storage
類似於 time-travel storage,但僅存儲元組之間的 Delta,而不是完整的舊版本,DBMS 可以通過逆向應用增量數據來重建舊版本。 這種方式通常比 time-travel storage 寫入更快,但查詢舊版本時會更慢。

Garbage Collection
在 MVCC 中,隨著時間的推移,某些舊版本的資料變得無用。 像是一些沒有任何 active 的交易可以看到的版本,或是該交易是被一個 abort 的交易創建的,這時候就需要有一個機制來清理這些版本。
在 GC 中,我們需要討論兩個方向 :
- 如何找到無用的版本
- 如何確定何時可以安全的回收
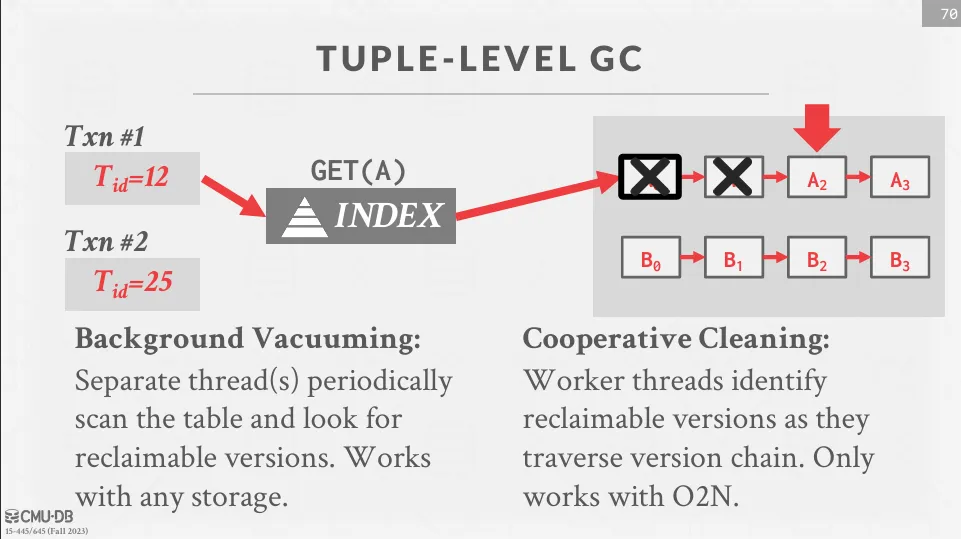
Tuple-level GC
Tuple-level GC 通過直接檢查元組來檢查舊版本的資料,有兩種常見的方式 :
- Background Vacuuming
- Cooperative Cleaning
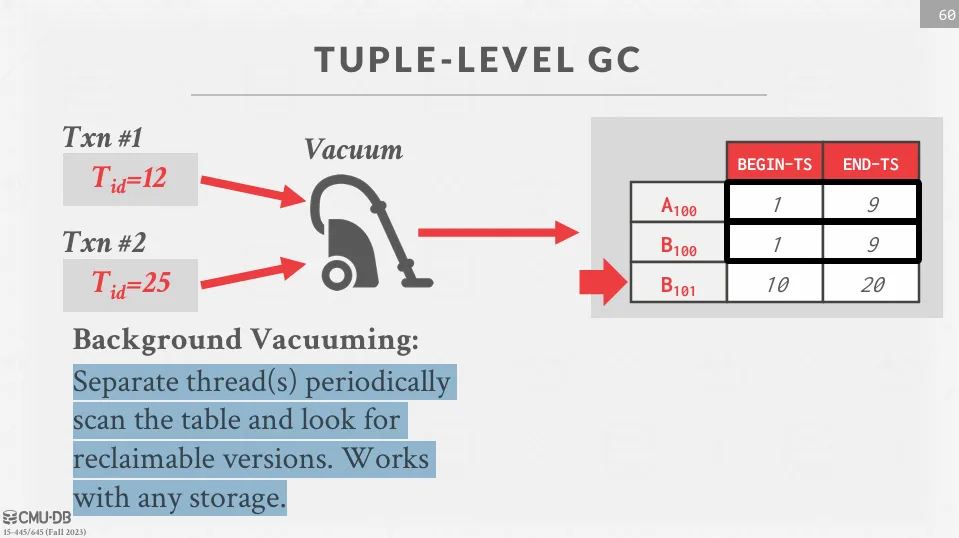
Background Vacuuming
假設有兩個 active 的事務,timestamp 分別是 12 跟 25,並且還有一個在背景執行的 vacuum thread。 這個 thread 會定期檢查所有的 tuple,並將那些沒有 active 事務可以看到的版本刪除。
DBMS 可以維護一個 dirty page bitmap 追蹤上次 vacuum 之後有哪些頁面被修改過,這樣就可以只檢查這些頁面,用空間換取時間
Cooperative Cleaning
Worker thread 在遍歷 version chain 時順便回收。這種方法僅適用於 O2N chains。
Transaction-level GC
在 Transaction-level GC 中,每個交易都會維護其自己的 read / write set。 當交易完成時,GC 可以根據這些集合來識別哪些元組版本可以被回收。

Index Management
在 MVCC 中,索引管理是關鍵的一環,因為它涉及如何有效地追蹤和查找不同版本的數據,需要將 primary index 和 secondary index 分開討論。
Primary Key Indexes
通常來說,primary key 不會常常被更新,因此在 B+ tree 中,我們可以直接將 primary key 指向 version chain 的 head (最新版本)。
如果更改了 primary key,則可以當作是刪除舊的 primary key 並插入新的 primary key。
Secondary Indexes
輔助索引的管理比主鍵索引更加複雜,因為這些索引需要考慮不同版本的元組如何影響索引,主要有兩種方法來管理 secondary index :
- Physical Pointers
- Logical Pointers
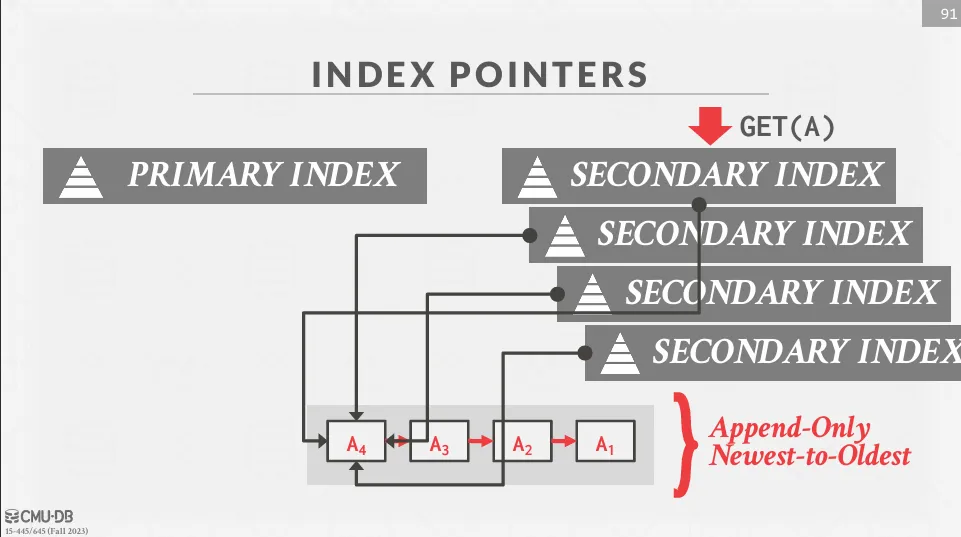
Physical Pointers
Secondary index 直接指向元組的物理位置 (如 RID),這樣在查詢時可以快速定位到元組。 但如果元組被更新或移動,則需要更新所有指向該元組的索引條目,假如有很多 secondary index,這會導致大量的索引更新操作。
以 PostgreSQL 為例,為了解決這個問題,PostgreSQL 使用了一種稱為 Heap-Only Tuples (HOT) 的技術。 當一個元組被更新時,如果新的版本可以放在同一個頁面中,PostgreSQL 會將新的版本插入到同一頁面中,並更新版本鏈,而不需要更新索引,這樣可以減少索引的更新次數。
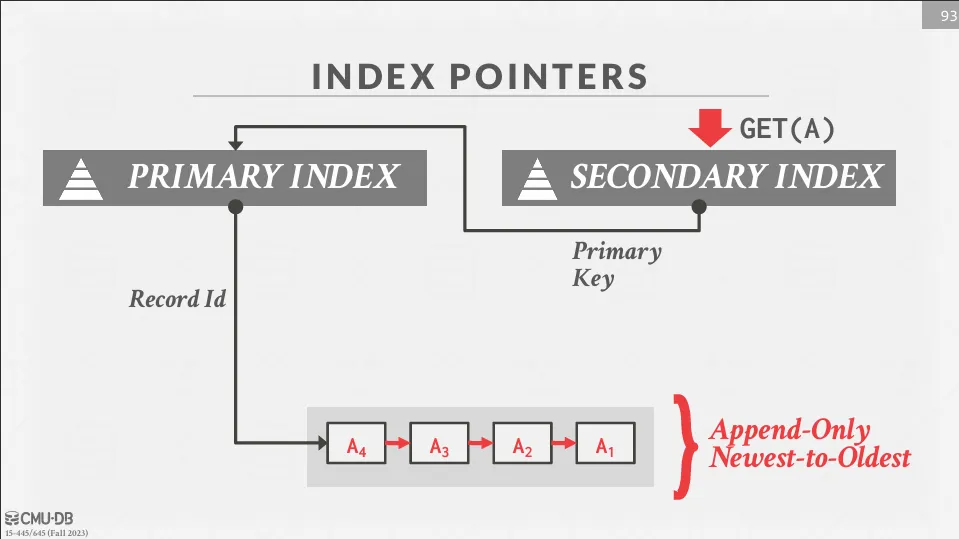
Logical Pointers
可以改為指向一個 indirection layer (如 primary key),這樣就可以避免更新 secondary index 的問題。
查詢的流程就變成了先通過 secondary index 找到 primary key,然後再通過 primary key (回表) 找到最新版本的元組。
有名的例子就是 MySQL 的 InnoDB 引擎,它使用 clustered index 作為 primary index,並且所有的 secondary index 都指向 clustered index 的 primary key。
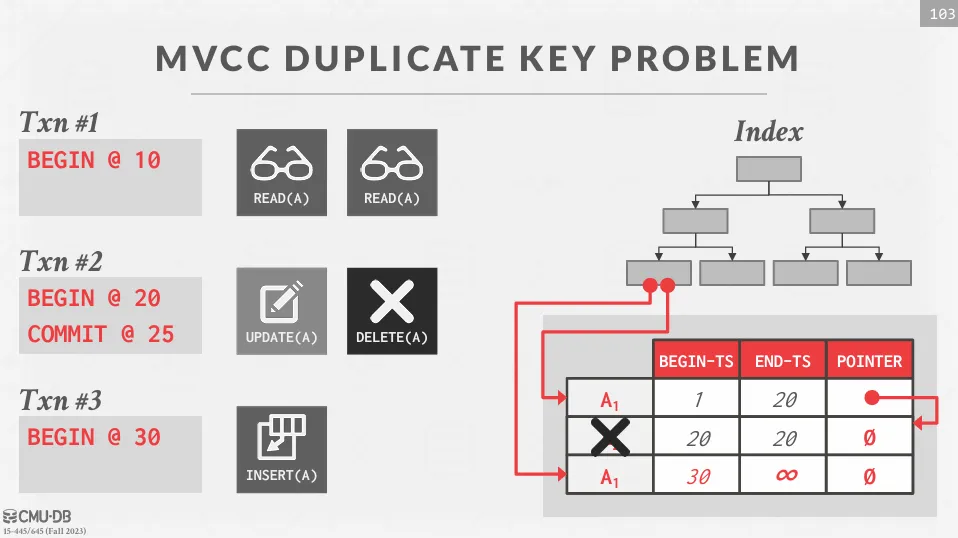
MVCC Duplicate Key Problem
在 MVCC 索引中,通常不會儲存元組和 key 的版本資訊 (MySQL 除外),因此 MVCC 系統需要支持多個版本的相同邏輯元組。
為了解決這個問題,索引的資料結構需要能支持 non-unique key,並且能夠存儲多個版本的元組,讀取的時候還需要通過可見性檢查來確定哪個版本是可見的。
Deletes
在 MVCC 中,刪除操作涉及到不同版本的資料行可能在不同交易中同時可見。 因此,DBMS 通常不會立即物理地刪除資料行,而是使用一些標記或策略來表示資料行已被邏輯上刪除。 當所有交易都無法再看到該資料行時,才會物理刪除該資料行。
常見的兩種方法是 :
- Deleted Flag
- Tombstone Tuple
Deleted Flag
當一個資料行被邏輯上刪除時,DBMS 會在該資料行的 header 中設置一個標記來表示此資料行已被刪除,如 PostgreSQL 的 XMAX 欄位。
Tombstone Tuple
當一個資料行被邏輯上刪除時,DBMS 會創建一個特殊的墓碑元組來表示該資料行已被刪除。 這個墓碑元組通常會被放入一個專門的空間中,並且使用特殊的 bit pattern 來減少存儲空間的使用。
Summary
下表是一些常見的 DBMS 及其 MVCC 的實作方式 :
