Timestamp Ordering Concurrency Control
Timestamp Ordering (T/O) concurrency control 是一種樂觀的併發控制協議。 這種協議會假設衝突不常發生,因此不會在讀取或寫入資料庫之前獲取鎖。 T/O 的主要概念是為每個交易分配一個 timestamp,如果 ,則 DBMS 需要確保執行計劃等價於一個交易順序為 的序列。
而實現 T/O 需要單調遞增的 timestamp,通常有以下幾種方法 :
- system clock : 使用系統的時鐘來生成 timestamp,有可能會受到夏令時間 (daylight savings time,會在夏令時調整時鐘) 等等時鐘回撥問題的影響
- logical counter : 使用邏輯計數器來生成 timestamp,這種方法可能會有溢出問題,並且很難在分散式系統中維持一致性
- hybrid clock : 結合系統時鐘和邏輯計數器,如節點 A 上次發出的 ts=(1000,0),但系統時鐘回撥到 900,下一個事件會回傳 (1000,1)。
Basic Timestamp Ordering (BASIC T/O)
Basic Timestamp Ordering (BASIC T/O) 是一種基本的 T/O 協議,會在 runtime 及每一次操作時檢測衝突。
在這個協議中,事務讀寫都不需要加鎖,且每條資料 都會有兩個 timestamp,分別是 read timestamp () 和 write timestamp (),Basic T/O 會在每次操作時檢查這些時間戳。如果交易試圖讀取未來的資料,該交易將被中止並重新啟動。
Read Operation
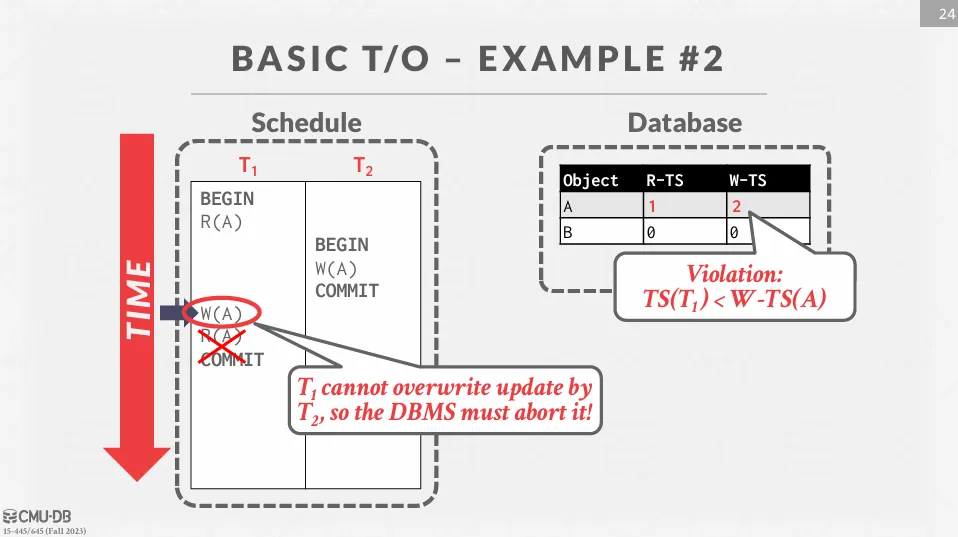
- 檢查 是否大於 ,如果小於則代表 試圖讀取未來的資料,因此 會被中止並重新啟動,否則 可以讀取
- 如果讀取成功,則更新
- 為了確保 的可重複讀,DBMS 會儲存一個 的副本到 的本地空間中
Write Operation
- 檢查 是否小於 和 ,如果小於則代表 試圖覆蓋未來的資料,因此 會被中止並重新啟動,否則 可以寫入
- 如果寫入成功,則更新
- 為了確保 的可重複讀,DBMS 會儲存一個 的副本到 的本地空間中
Example
建議搭配 2023 年的投影片一起看,方便理解上方的讀寫操作。 PPT Link
Thomas Write Rule (TWR)
針對 的寫入情境,在 BASIC T/O 裡面是要被終止的。
但 Thomas 觀察到,由於沒有其他操作依賴於這個寫入操作 (會寫入到 local copy 中),因此我們可以忽略這個寫入操作 (但還是要寫入 local copy),並且不需要終止交易。
這樣做會使 serializability 從 conflict serializability 降低到 view serializability。
Summary
對於 BASIC T/O 來說,它的優缺點如下 :
- 優點
- 無需加鎖,所以不會造成死鎖
- 缺點
- 長的交易可能會因為衝突而導致產生 starvation
- 複製資料、維護 timestamp 會增加系統的開銷
- 可能產生無法恢復的 schedule,比如有一個交易寫入了資料,然後另一個交易讀取並提交了這個資料,接著第一個交易因為衝突而被中止
Optimistic Concurrency Control (OCC)
Optimistic Concurrency Control (OCC) 是一種樂觀的並發控制協議,在最後的提交階段才會檢查衝突。 OCC 適合在衝突較少的情況下使用,比如當所有交易都是唯讀的,或者當交易訪問不重疊的資料子集時。
在 OCC 中,執行主要分為三個階段 :
- Read Phase
- Validation Phase
- Write Phase
Read Phase
在 read phase 中,交易會將讀取跟寫入的資料複製到私有空間中並記錄 read set 跟 write set,不會對資料庫進行任何修改。
Validation Phase
當進入 validation phase 後,系統會分配一個唯一的 timestamp TS,並檢查 read set 和 write set 是否與其他交易衝突。 如果有衝突,則交易會被中止並重新啟動。
DBMS 會檢查交易之間的 RW 衝突以及 WW 衝突,並確保所有衝突都朝同一個方向發生,主要有兩種方法來進行驗證 :
- Forward Validation
- Backward Validation
Forward Validation
當交易 要提交時,DBMS 會檢查所有尚未提交的交易 ,如果 ,則檢查以下三種情況 :
- 完成 read、validation、write, 才開始
- 的 write phase 完成於 的 write phase 開始之前,且不會覆蓋 需要讀的資料,用於避免 WR 衝突
- 的 read phase 完成於 的 read phase 完成之前,且 不會修改 需要的資料,用於避免 RW 衝突以及 WW 衝突
- 跟
Backward Validation
與 forward validation 類似,但檢查的方向相反,backward validation 會檢查所有已經提交的交易。
Write Phase
當進入 write phase 時,DBMS 會將私有空間中的修改寫入到資料庫中,並更新 write set 中的 。
有兩種寫入策略 :
- Serial Commits : 用一個全域的 latch 來確保同一時間只有一個交易在寫入資料庫
- Parallel Commits : 使用細粒度的鎖來允許多個交易同時寫入資料庫,需要按照 key 的順序來獲取鎖以避免死鎖
Example
一樣是建議搭配投影片一起看,方便理解上方的三個階段。 PPT Link
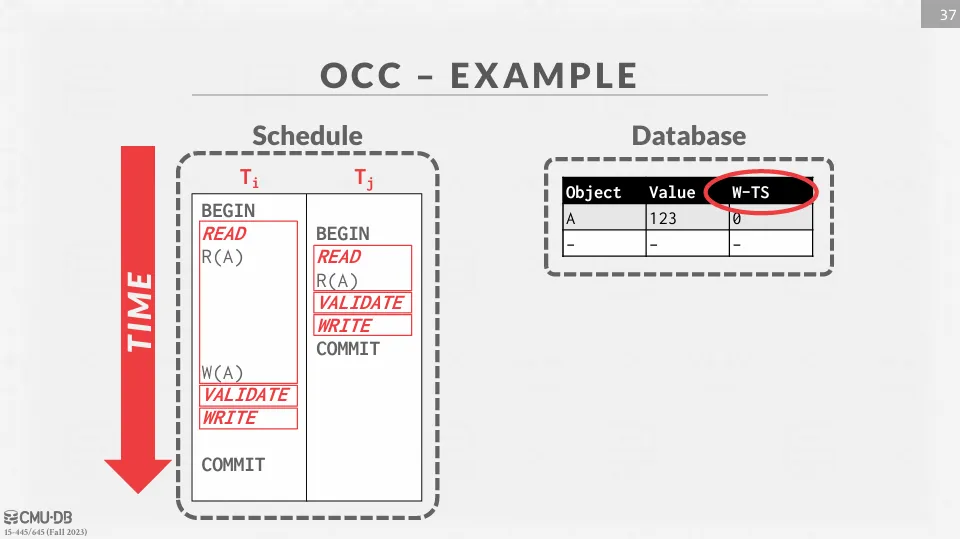
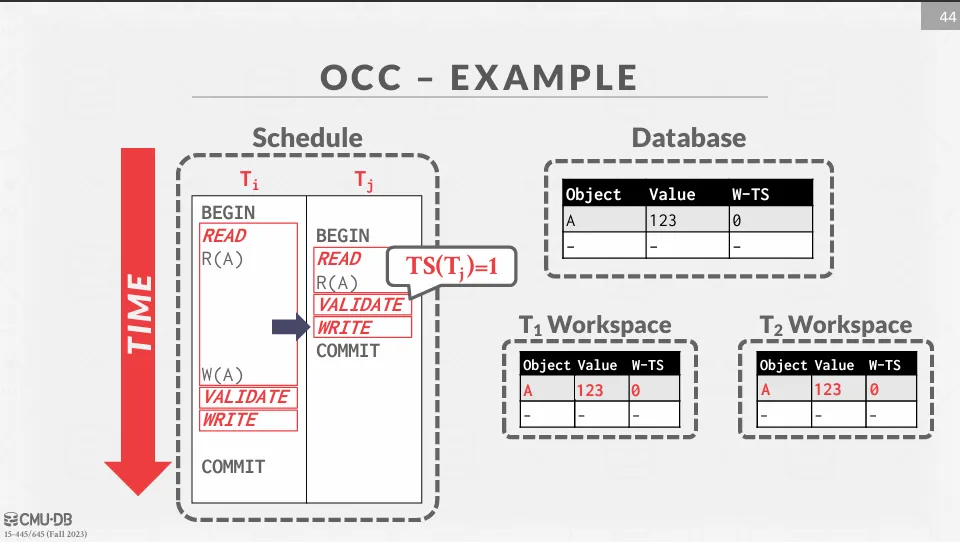
與 Basic T/O 相比,OCC 只需要儲存 。
接著 T1 跟 T2 會將資料放到私有空間中。
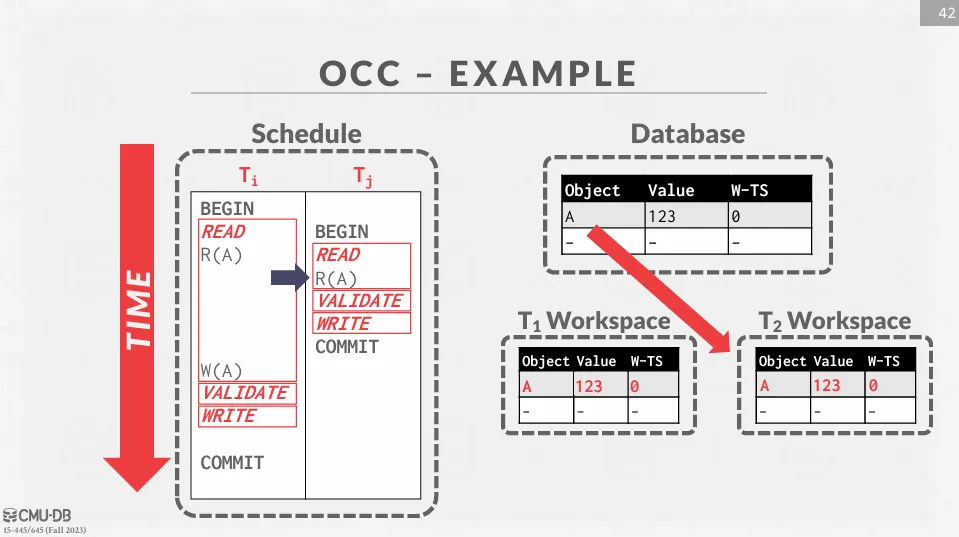
T2 完成整個交易,由於沒有資料要寫入,因此跳過 write phase,並獲得 timestamp 1。
T1 將值修改為 456,由於還不知道 timestamp,因此暫時為無限大。 接著進行 validation phase,由於 ,因此 T1 可以提交,並將 更新為 2。
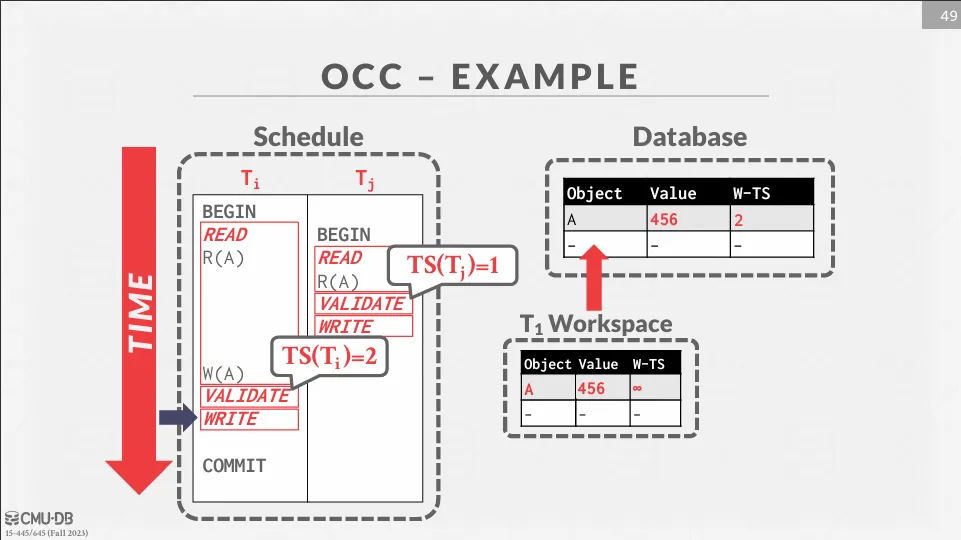
Summary
OCC 會有以下的問題 :
- 將資料複製到私有空間會增加系統的開銷
- validation / write phase 需要在全局的 critical section 中執行,這可能會造成瓶頸
- 由於交易只有在執行完成後才會進行驗證,因此 abort 會浪費大量已完成的工作
- timestamp 的分配可能會成為瓶頸
Dynamic Databases and Phantom Problem
到目前為止,我們只討論了資料庫的讀取以及更新,而沒有考慮到插入和刪除等等的操作。 這些操作可能會帶來新的問題,其中一個問題就是 phantom problem。
Phantom problem 是指在交易執行期間其他交易插入了新的資料,導致同樣的查詢產生了不同的結果,解決方式大致有以下三種 :
- Re-Execute Scans
- Predicate Locking
- Index Locking
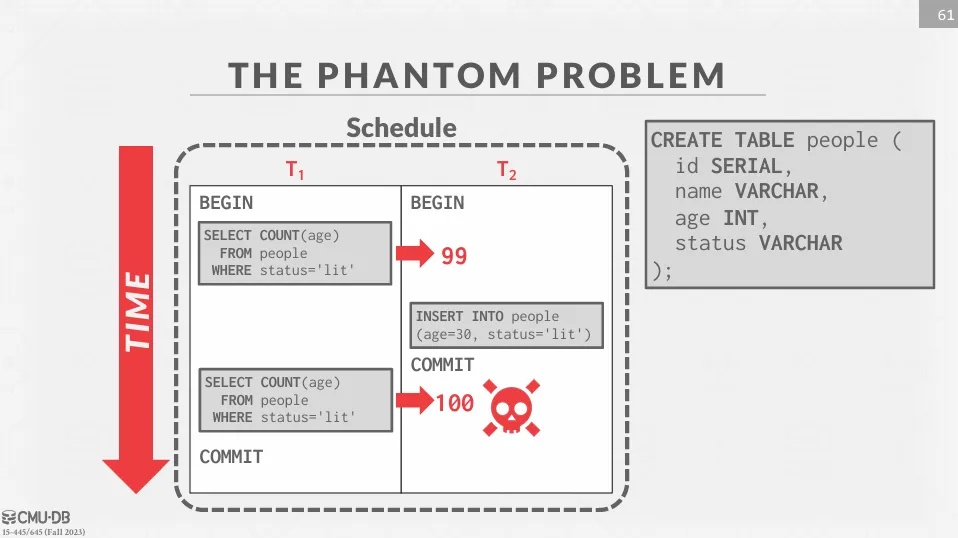
Re-Execute Scans
在交易提交時,DBMS 會重新執行所有查詢,確保結果與第一次執行時一致。 如果有任何新增或刪除的記錄導致結果不同,DBMS 可以檢測到這種情況並適當處理。
缺點是在資料庫規模較大時,這種方法會增加系統的開銷。
Predicate Locking
這種方法基於查詢的條件 (如 WHERE 子句) 來鎖定滿足條件的所有資料。 通過鎖定與查詢條件匹配的所有潛在資料,防止其他交易對這些資料進行修改。
幾乎沒有 DBMS 使用這種方法,因為對每條新插入的資料進行檢測會導致性能嚴重下降。
Index Locking
通過索引來鎖定特定範圍內的資料,防止在鎖定範圍內插入新資料,從而避免幻影問題。
- Key-Value Locks:對索引中的單個鍵值進行鎖定,包括對不存在的鍵值進行虛擬鎖定
- Gap Locks:鎖定鍵值之間的間隙,防止在這些間隙中插入新資料
- Key-Range Locks:鎖定從一個現有鍵到下一個鍵的範圍,左閉右開
- Hierarchical Locking:允許交易持有更廣泛的鍵範圍鎖 (IX),並結合不同的鎖定模式來減少鎖管理器的負擔

Locking Without An Index
如果查詢的欄位沒有索引,那麼我們需要獲取 :
- table 上每個 page 的鎖
- table 本身的鎖
Isolation Levels
Serializability 是一種很實用的特性,它可以讓寫程式的人不用擔心併發所帶來的問題,但由於它的嚴格性會導致性能下降,因此有時候我們需要降低 isolation level 來提高性能。
更弱的 isolation level 會有更好的性能,但也會帶來更多的問題,如 dirty read、non-repeatable read、phantom read 等等。 如果要更詳細的了解,可以參考 這篇筆記。
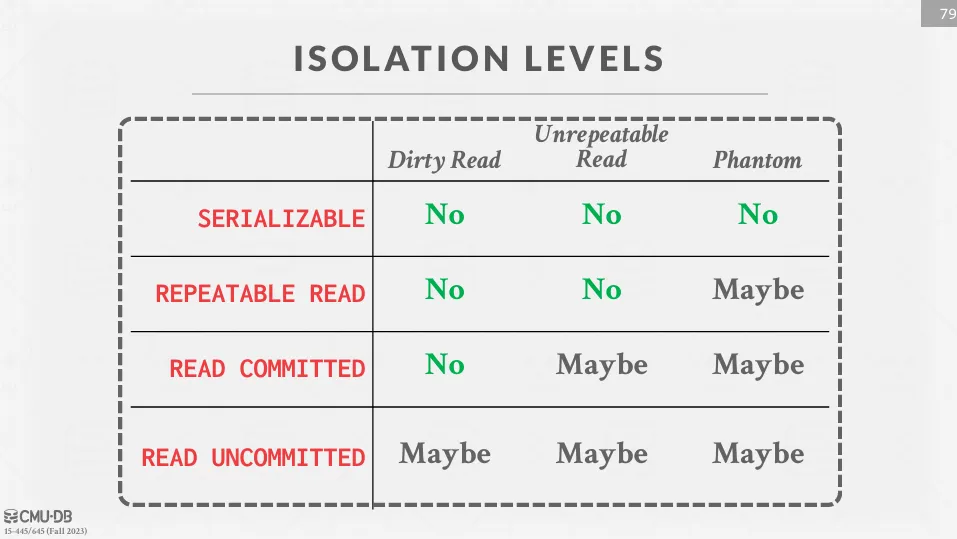
並非所有的資料庫都支持所有的 isolation level,因此需要查看相應的文件。

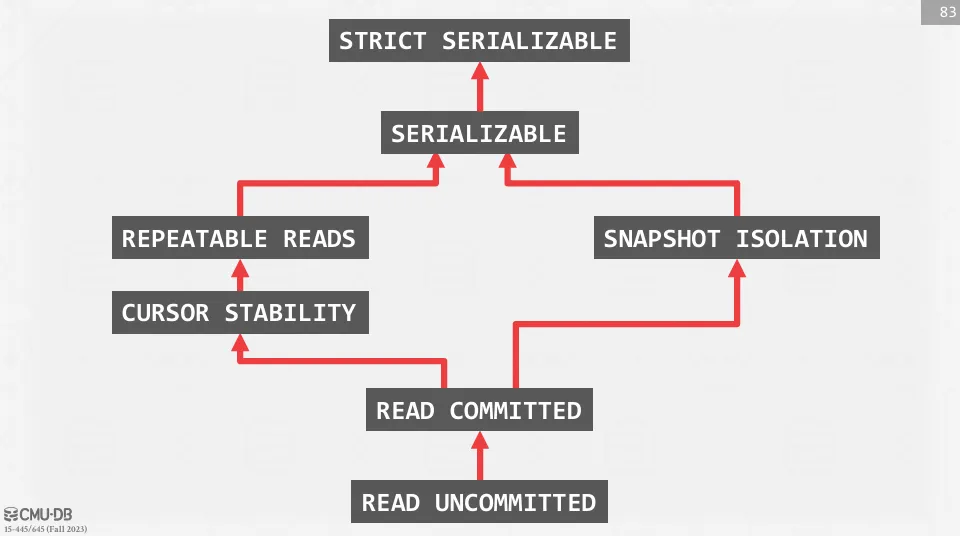
從下面這張圖來看,也有一些 isolation level 並不在 SQL-92 標準中,下面是一些常見的 isolation level 及其特性 :
- Read Uncommitted : 幾乎不提供任何保證,只在讀的時候加上 X lock
- Read Committed : 只會讀到已提交的資料,避免了 dirty read,如果是基於 MVCC 的話,看到的是執行這條指令時的快照
- Cursor Stability : 介於 Read Committed 跟 Repeatable Read 之間,確保不會有 lost update 問題,可以在基於 Read Committed 上多鎖住 cursor 當前的資料列來實現
- Repeatable Read : 保證交易在執行過程中多次讀取同一資料會得到相同的結果,可以基於 SS2PL 實現
- Snapshot Isolation : 保證交易在執行過程中讀到的是交易開始時的數據快照,採用先提交者勝出 (First Committer Wins) 的策略來解決寫衝突問題,可能會有 write skew 問題。同時也是 PostgreSQL 的在 Repeatable Read 的實現方式
- Serializable : 提供與 serializability 相同的保證,但允許更高的並發性,可以基於 SSI (Serializable Snapshot Isolation) 或是 SS2PL + phantom protection 來實現
- Strict Serializable : 要求 serializability,同時要求如果交易 在 之後開始,那麼在等價的序列中 也必須在 之後執行