Concurrency Control Theory
對於 DBMS 來說,除了基本的 CRUD 操作外,我們還有兩個問題需要解決 :
- 如何在同時更新時避免 race condition (concurrency control)
- 當資料庫發生故障時,我們如何保證資料的完整性 (recovery)
在接下來的幾篇中,我們會探討如何解決第一個問題,也就是 concurrency control。
Transaction
Transaction 是 DBMS 中最基本的操作單位,指的是一系列操作的執行,且這些操作要麼全部執行成功,要麼全部不執行。
舉例來說,假如你要從 Andy 的銀行帳戶中轉出 $100 給他的經紀人,這個交易涉及以下步驟 :
- 確認 Andy 帳戶中是否有 $100
- 從 Andy 的帳戶中扣除 $100
- 將 $100 加到他的經紀人的帳戶
這個交易要麼全部完成 (即上述三個步驟都成功執行),要麼不會改變任何帳戶的狀態。
The Strawman System
Strawman system 是一個簡單的 transaction system,它只有一個 thread 來執行所有的 transaction,因此不管在任何時刻都只能有一個 transaction 在執行。
這個系統的處理方式是將所有檔案都複製一份,然後對這個新的檔案進行修改,如果成功就全部覆蓋,這種方式雖然簡單但是缺點是顯而易見的,就是無法利用多核來處理獨立的 transaction。
為了提高效率,我們必須允許多個 transaction 同時執行,但這樣就會產生正確性的問題,如 :
- Temporary Inconsistency : 交易在執行過程中,資料庫可能暫時處於不一致的狀態,如 Andy 的帳戶已經扣除了 $100,但經紀人的帳戶還沒有加上 $100,這是可以接受的
- Permanent Inconsistency : 如果兩個 transaction 同時執行,可能會導致資料庫的最終狀態不正確,如扣除 Andy 帳戶的 $100 卻沒在經紀人帳戶中加上 $100,這是不可接受的
為了避免 permanent inconsistency,我們需要保證 transaction 有 ACID 特性。
ACID - Atomicity
DBMS 需要保證 transaction 的原子性,即所有操作只有全部完成跟全部未完成兩種結果,如果在過程中出現錯誤,DBMS 需要回滾到原本的狀態。
主要有兩種策略 :
- Logging : 目前主流的實作方式,會記錄交易過程中的每一項變更,並同時保存在記憶體跟硬碟上
- Shadow Paging : 將交易需要修改的頁面複製,並只在新的頁面中修改,當交易提交時才會覆蓋原本的檔案,通常在 single thread 的環境中使用
ACID - Consistency
Consistency 表示在資料庫中的邏輯是正確的,主要分為兩種 :
- Database Consistency : 遵循 integrity constraints,例如人的年齡不可能是負數,可以使用 SQL 中的
CHECK或CONSTRAINT來實現 - Transaction Consistency : 如果交易前是一致,交易後也應該是一致的
需要特別注意的是,ACID 中的 Consistency 跟 CAP theorem 中的 Consistency 是不同的,前者是指資料庫的邏輯正確性,後者是指所有節點在同一時間看到的資料是一致的。
ACID - Isolation
不同的交易在執行過程中應該互相隔離且互不影響,就像在單獨運行一樣。 但在實際情況中,由於效能問題,DBMS 需要將多個同時執行的交易交錯執行,並同時保持隔離性。
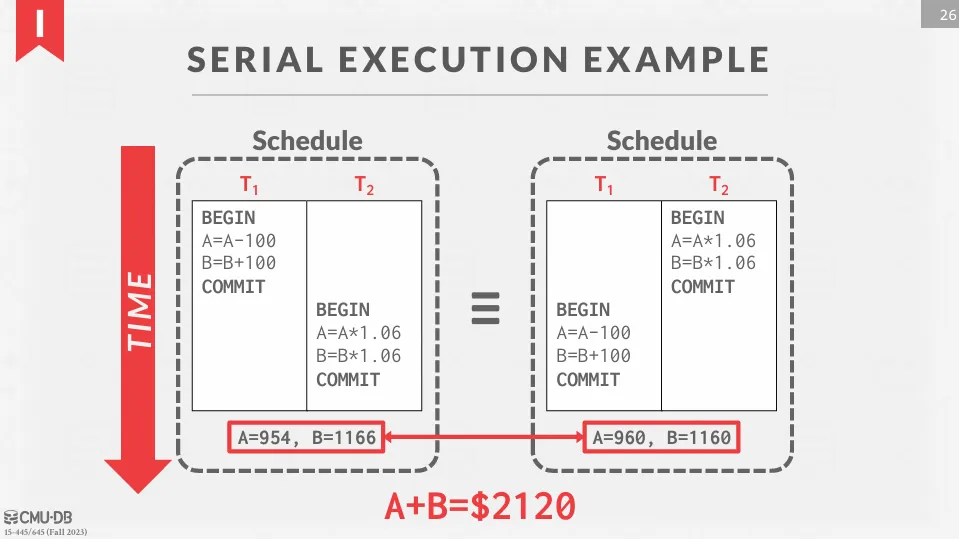
舉例如下,有兩個交易 t1 和 t2 :
- t1 : A 轉給 B 100 元
- t2 : A 和 B 獲得 6% 利息
當這兩個交易發生之後,不管順序如何,DBMS 需要確保最後兩者加起來的結果是 元。
Concurrency Control
Concurrency control 指的是 DBMS 如何決定多個交易操作的正確順序,大致有兩種不同類型的策略 :
- Pessimistic (悲觀) : DBMS 假設會發生衝突,可以透過鎖定資源來實現
- Optimistic (樂觀) : DBMS 假設不會發生衝突,直到 commit 時才會檢查衝突並回滾
我們會在接下來的幾節裡面詳細討論不同的 concurrency control 策略,如 Two-Phase Locking (2PL) 跟 Optimistic Concurrency Control (OCC)。
Schedule
DBMS 的執行順序被稱為 execution schedule。 我們希望可以盡量交錯交易來最大程度的提高倂發性,這樣當某個交易在等待資源 (disk IO、page fault) 或 CPU 有空閒時,就可以繼續執行其他交易。
我們需要保證 schedule 是 serial schedule 或是等價於 serial schedule (serializable schedule)。 也就是說,這些交易的結果應該與某個 serial schedule 的結果相同,這樣才能保證交易的正確性。
以上面的例子來說,不管是 t1 先執行還是 t2 先執行,最後的結果都應該是 元,這兩個 schedule 都是 serial schedule。
Conflict
既然我們要最大化倂發性,那我們就需要知道哪些操作是可以交錯執行的,哪些操作是不能交錯執行的。
當兩個操作滿足以下條件時,我們稱之為 conflict :
- 這兩個操作來自不同的交易
- 這兩個操作的目標資源是同一個,且至少有一個操作是 write
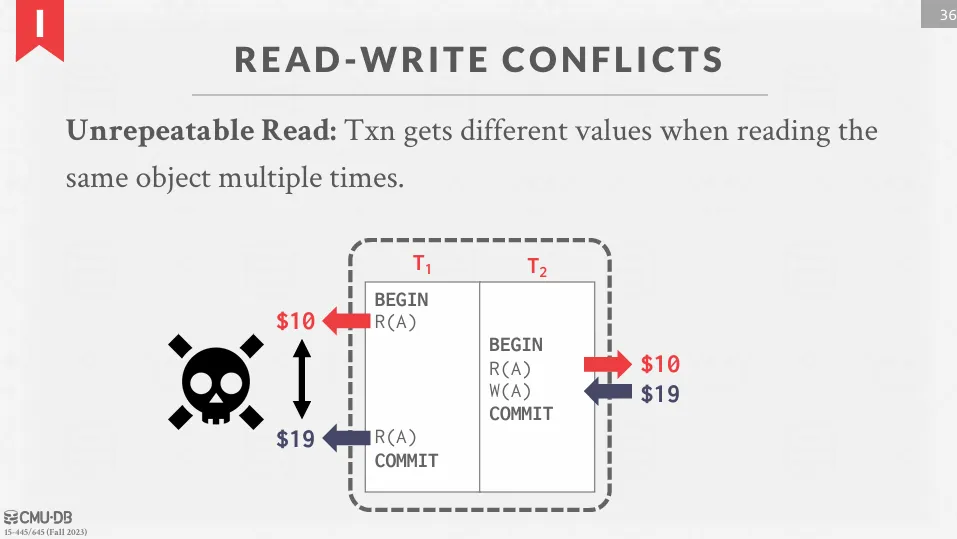
Read-Write Conflict
當一個交易多次讀取同一個資源但得到的結果不同時,就是 read-write conflict (unrepeatable read)。
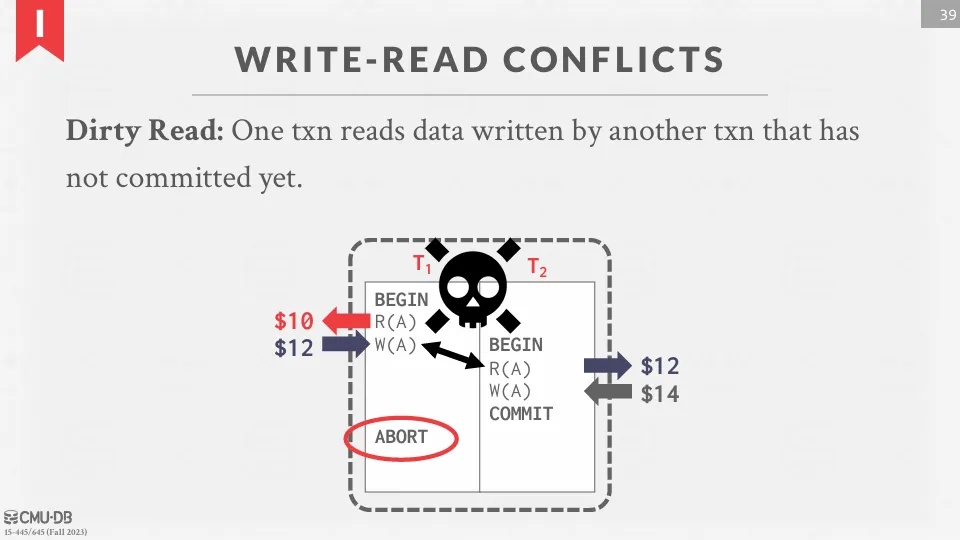
Write-Read Conflict
當一個交易可以讀取到另一個交易尚未提交的值時,就是 write-read conflict (dirty read)。
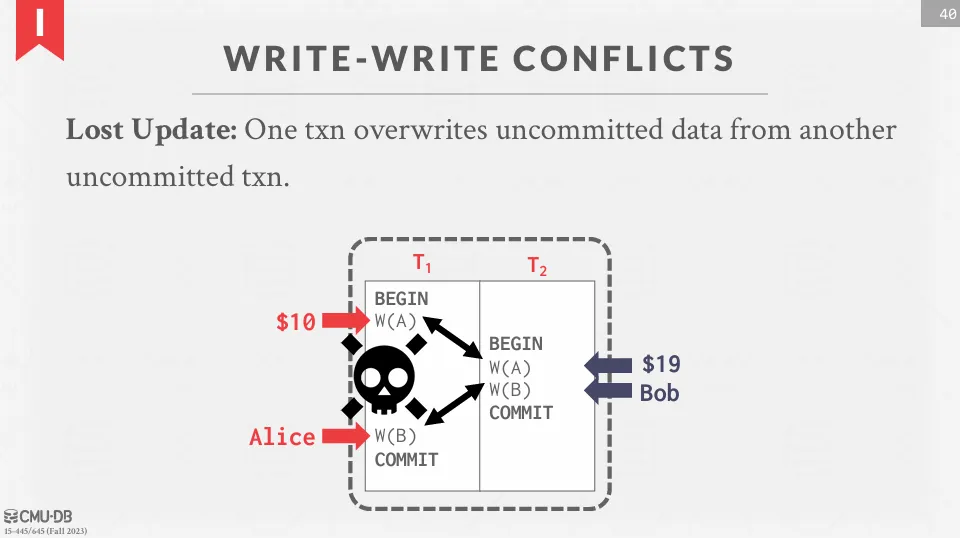
Write-Write Conflict
當兩個交易修改同一個資源,卻有一個交易被完全覆蓋時,就是 write-write conflict (lost update)。
Serializability
我們的目標是找到等價於 serial schedule 的 schedule,所以我們需要一個嚴格且可執行的標準來判斷一個 schedule 是否是 serializable。
要達成這個目標,有兩種主要的方法 :
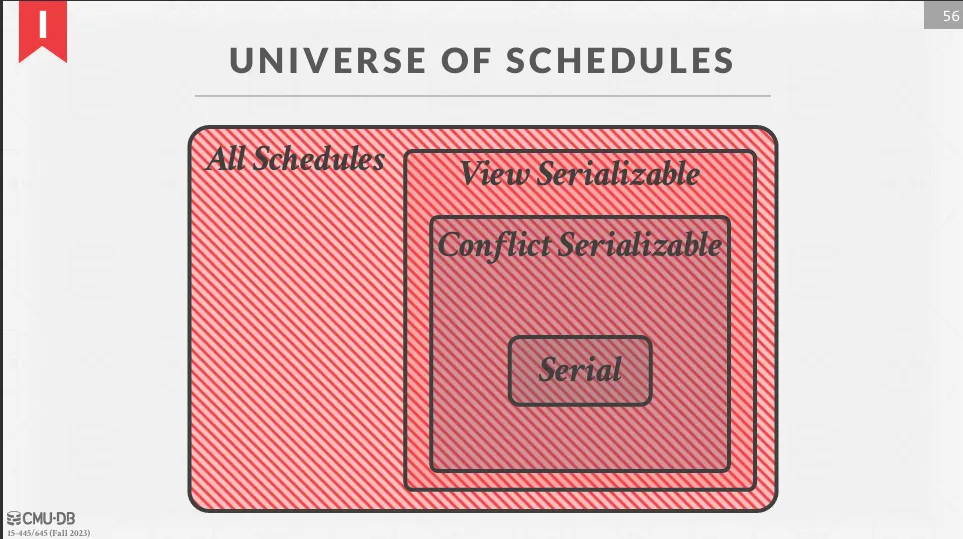
- Conflict Serializability : 大多數 DBMS 支持
- View Serializability : 沒有 DBMS 支持,因為很難判斷是否是 view serializable
Conflict Serializability
- Conflict equivalent : 兩個 scheduler 在交易中有相同的 action,且對於所有會互相衝突的操作 (如 read-write、write-read、write-write),這些操作在兩個 schedule 中的先後順序必須一致
- Conflict serializable : 如果一個 scheduler conflict equivalent 於某個 serial scheduler,則這個 scheduler 是 conflict serializable
如果我們可以通過交換不同交易中連續的 non-conflicting operations 來將一個 scheduler 轉換為 serial scheduler,則這個 scheduler 是 conflict serializable,但這種方式在多個交易的情況下不好用。
我們可以構建 dependency graph 來判斷是否是 conflict serializable。 在這個圖中,每個事務都是一個節點,如果事務 中的操作 與事務 中的操作 衝突且 在排程中先於 ,則從節點 到 有一條有向邊。 只有當這個圖是無環時,這個 scheduler 才是 conflict serializable。
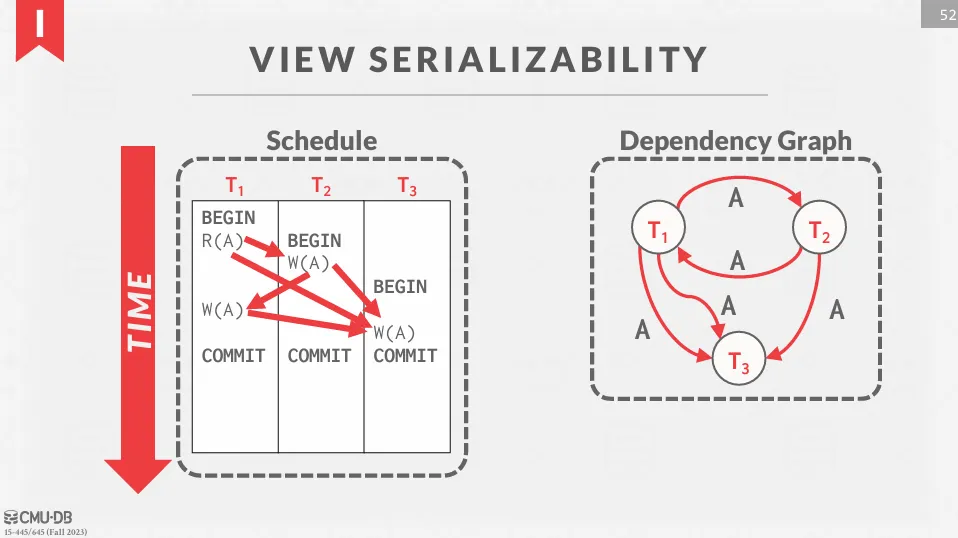
View Serializability
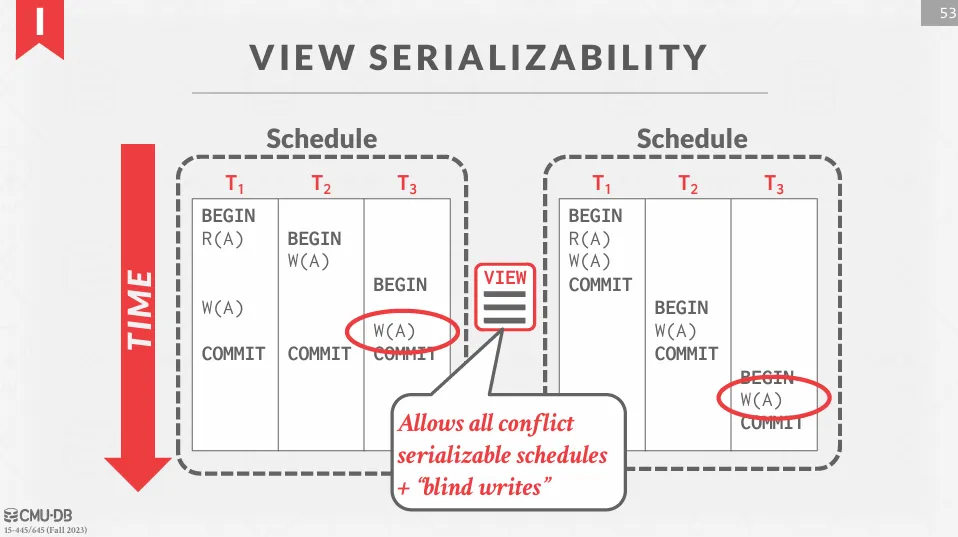
與 conflict serializability 相比,view serializability 是一種更寬鬆的標準,並允許盲寫 (blind write)。 盲寫指的是一個交易寫入一個值,但在寫之前沒有讀取過這個值。
給定兩個有相同交易集合的 scheduler 和 serial scheduler , 和 是 view equivalent 當且僅當每筆資料 滿足以下三個條件 :
- 初始讀一致 : 如果在 中,交易 的讀操作 是 的第一次讀取,則在 中, 的讀操作 也是 的第一次讀取
- 讀來源一致 : 如果在 中,交易 的讀操作 讀取了交易 的寫操作 所寫入的值,則在 中, 的讀操作 也讀取了 的寫操作 所寫入的值
- 最終寫一致 : 對每個資料 ,如果在 中,交易 是最後一個寫入 的交易,則在 中, 也是最後一個寫入 的交易
如果一個 scheduler 是 view equivalent 於某個 serial scheduler,則這個 scheduler 是 view serializable。
總體來說,view equivalent 不看重操作的順序,只看讀到誰的值以及最後寫入的是誰,因此 view serializable 的範圍比 conflict serializable 更大。 但這種方法沒有 DBMS 支持,因為判斷 view serializable 是 NP-complete 問題。
下面是一個符合 view serializable 但不符合 conflict serializable 的例子,在這個例子中,T2 就有一個盲寫。
ACID - Durability
所有已提交的資料都將永久保存 (存在硬碟上),而不會因為系統崩潰而遺失。