Storage Models & Compression
這篇筆記會探討資料庫的儲存模型以及壓縮技術。
Database Workloads
在選擇儲存模型之前,我們必須先理解資料庫面臨的主要工作負載類型。

資料庫可以依據查詢複雜度以及讀寫比例來進行分類 :
- OLTP (Online Transaction Processing) : 大量、快速、簡短的交易。系統會注重低延遲以及高併發,譬如說電商的交易系統
- OLAP (Online Analytical Processing) : 主要用於複雜的查詢和分析,通常涉及大量的資料聚合和計算,常用於分析歷史數據以支援決策制定
- HTAP (Hybrid Transaction/Analytical Processing) : 同時支持 OLTP 和 OLAP 的工作負載
Storage Models
理解了負載類型後,我們就可以探討如何組織資料的物理儲存,以最高效地服務特定負載。
常見的儲存模型有以下幾種 :
- N-ary Storage Model (NSM) (row store)
- Decomposition Storage Model (DSM) (column store)
- Hybrid Storage Model (PAX)
N-ary Storage Model (NSM)
將同一筆 tuple 的所有屬性在 page 中連續儲存。這是最傳統、最直觀的儲存方式。

一般的 OLTP 應用場景中,我們會有大量針對單一 tuple 的查詢,我們可以直接透過 index 之後返還所有資料。
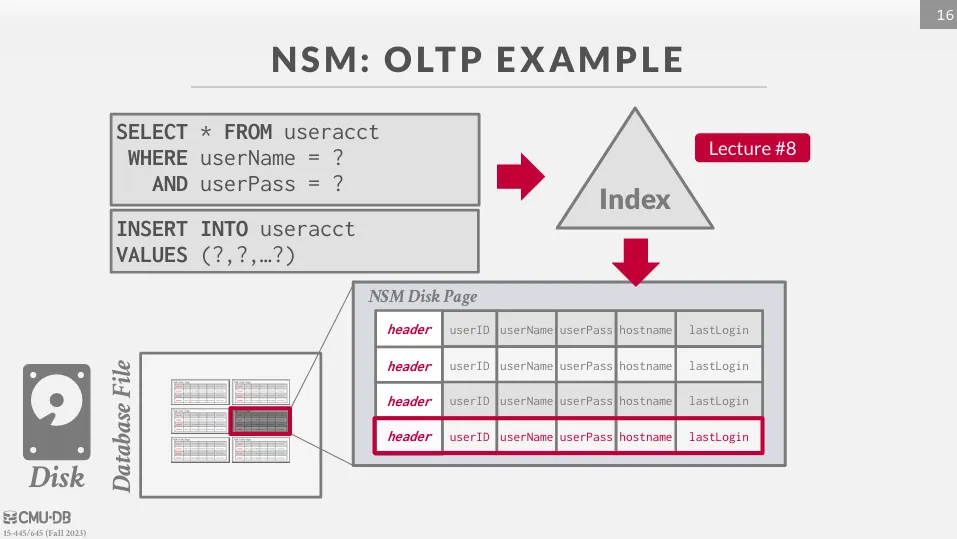
但對於 OLAP 應用場景,即使我們只需要一個 tuple 的部分屬性,我們也需要讀取整個 page。
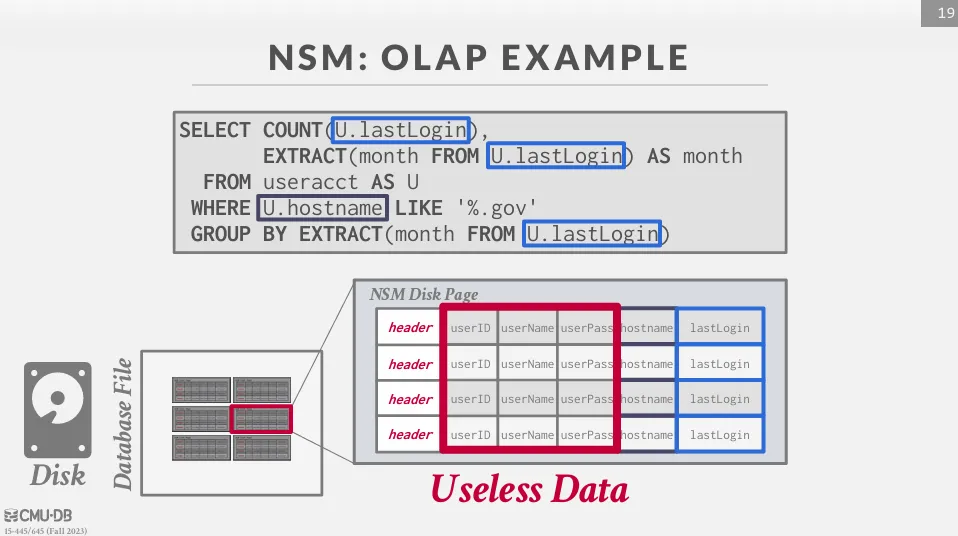
總結來說,NSM 的優缺點如下 :
- 優點
- 快速的 insert、update、delete
- 適合需要所有屬性的查詢
- 適合使用 index 的查詢
- 缺點
- 不適合需要 table 中大量 tuple 或是一部分屬性的查詢
- 記憶體使用效率較低 (需要讀取整個 page)
- 不適合進行壓縮 (因為 tuple 的屬性不在一起)
Decomposition Storage Model (DSM)
DSM 會將所有 tuple 的同一個屬性儲存在一起,這種儲存方式較為適合 OLAP 的應用場景。

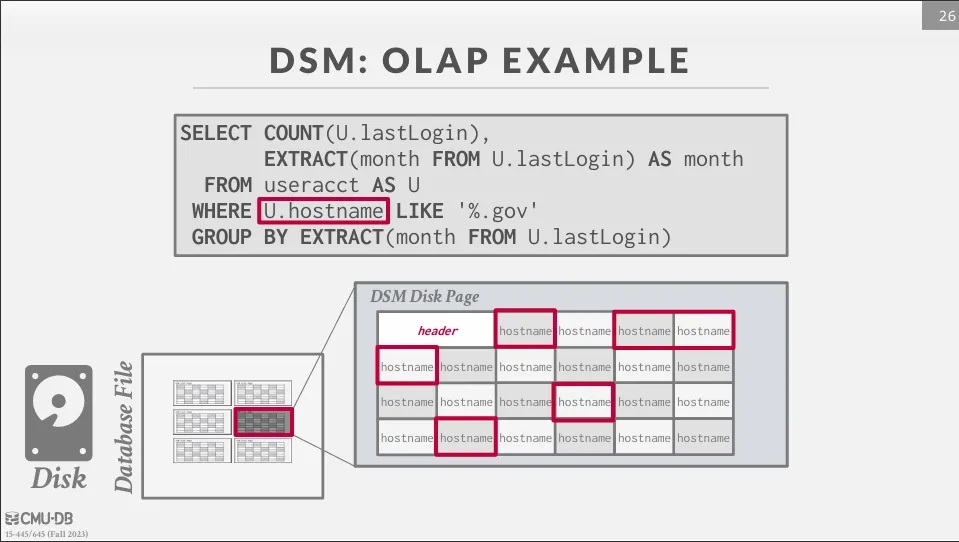
透過這種方式,我們就可以減少不必要的 I/O,只讀取我們需要的部分屬性,但這樣也會造成新的問題,例如要如何存取同一個 tuple 的不同屬性,通常這個問題有兩種解決方式 :
- Fixed-length Offsets : 每個屬性都是固定長度,透過 offset 來存取 (常見)
- Embedded Tuple Ids : 在每個屬性前都加上 tuple_id,透過 tuple_id 來存取
對 fixed-length offsets 來說,padding 會造成空間浪費,因此我們可以考慮使用接下來會介紹的 dictionary compression。

總結來說,DSM 的優缺點如下 :
- 優點
- 減少 OLAP 查詢的 I/O
- 記憶體使用效率較高
- 適合進行壓縮
- 缺點
- insert、update、delete 較慢
Partition Attributes Across (PAX)
PAX 是一種混合式的儲存模型,目標是將 column store 的優點 (處理速度) 和 row store 的優點 (空間) 結合在一起。
這種儲存方式會先將 tuple 分成幾個 group,在每個 group 中,資料會以 column store 的方式儲存,同時在 global header 中儲存每個 tuple 的 offset,且每個 group 也都有自己的 header 來儲存 metadata。

Compression
壓縮的核心目標是用 CPU 時間換取 I/O 時間。 由於 I/O 是資料庫中最耗時的操作,因此壓縮被廣泛的使用在 disk-oriented 的資料庫中。
在 DBMS 中,壓縮之後要可以達到以下目標 :
- 產生 fixed-length 的值 (DBMS 需要 follow word alignment)
- 只有當需要的時候才解壓縮 (late materialization)
- 無損壓縮
針對壓縮的粒度,大致分為以下幾種 :
- Block-level : 壓縮同一個表的部分 tuple
- Tuple-level : 壓縮整個 tuple (NSM only)
- Attribute-level : 壓縮一個 tuple 內的單一溢出 (overflow) 屬性,如 blob
- Column-level : 壓縮多個 tuple 儲存的一個或多個屬性 (DSM only)
Naive Compression (Block-level)
大多數的 DBMS 都會使用一般的壓縮算法,如 gzip、snappy、lz4、Zstd 等,主要考量的點是壓縮率和壓縮跟解壓縮的速度。
一個例子是 MySQL InnoDB 引擎的壓縮方法。 InnoDB 預設的 page size 是 16 KB,但它會將 page 壓縮並填充成 1、2、4、8 KB (其中之一) 再儲存在硬碟中。 當我們需要這筆資料時,InnoDB 會把被壓縮過後的 page 讀到 buffer pool 中,並且解壓縮成原本的 page。
但這樣的問題是,如果每次都要解壓縮整個 page,會造成 CPU 的浪費。 因此,InnoDB 會將修改的資料寫入到一個稱為 mod log 的地方,並且延遲更新 page,直到 page 被換出 buffer pool 時才會重新壓縮並寫回硬碟。
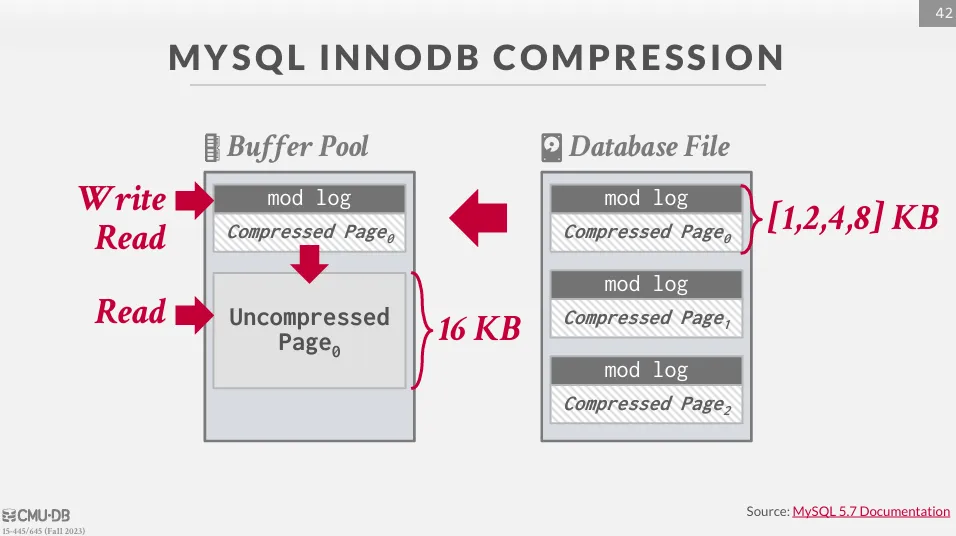
Naive Compression 的缺點在於,如果我們需要修改,我們就會需要解壓縮資料,這限制了壓縮的範圍,使得我們必須要資料分成較小的 block 來進行壓縮。 另一個問題是壓縮不會考慮資料的結構,也不會知道 query plan 如何訪問資料,因此 DBMS 不會知道要怎麼延遲解壓縮。
Columnar Compression (Column-level)
由於列式儲存中,同一欄位的資料是同質的,壓縮算法可以針對這些資料進行優化,讓 DBMS 可以在不完全解壓縮的情況下對資料進行操作。
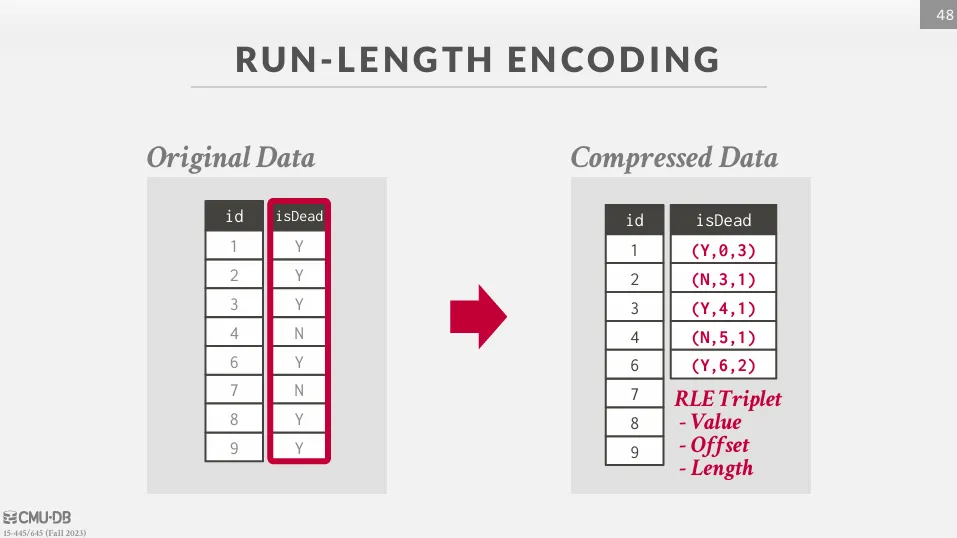
Run-Length Encoding (RLE)
將連續出現的相同值壓縮成 (值, 起始位置, 連續長度) 的三元組。 適用於低基數 (cardinality) 或已經排序過的 column。
Bit-Packing Encoding
如果整數的值小於給定類型的值的位數,我們可以將整數壓縮成較小的位數。

Mostly Encoding
當大部分的值的位數小於最大的大小時,我們可以對大部分的值進行壓縮。

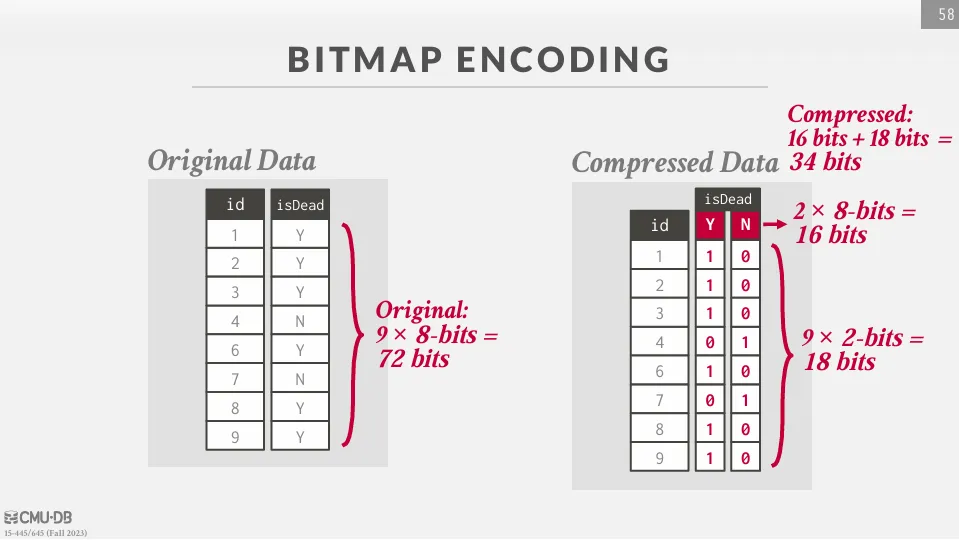
Bitmap Encoding
對於每個不同的值,我們可以建立一個 bitmap 來表示是否有這個值,不適合用在高 cardinality 的 column。
Delta Encoding
儲存相鄰值之間的差值,適合用在有序或變化平緩的欄位中,如時間戳、遞增 ID 等。 也可以搭配 RLE 使用。

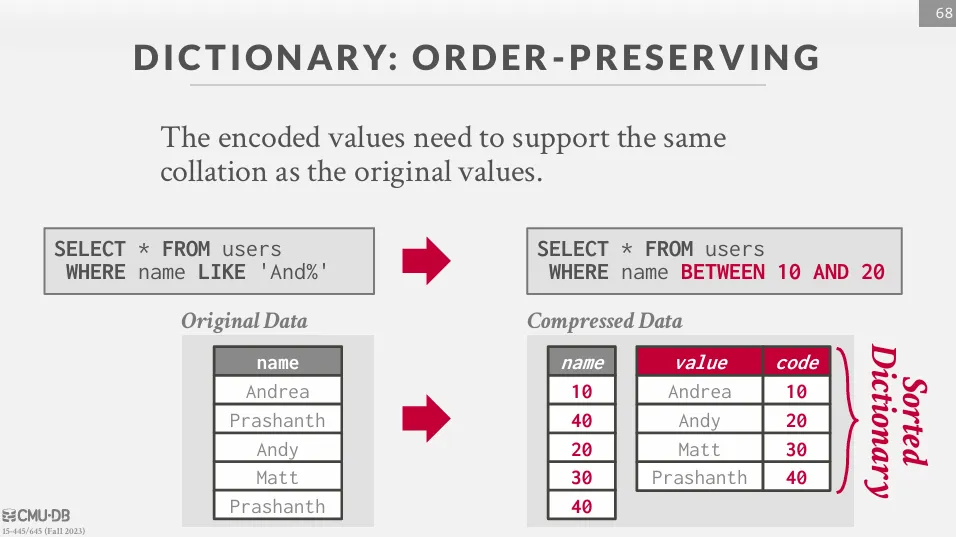
Dictionary Compression
最常見的壓縮方式,將常見的值轉換成一個較小且固定長度的值,並且維護一個 dictionary 來對應原本的值。 由於需要加解碼,因此無法使用 hash function 來對應原本的值,除此之外,最好還需要注意壓縮前跟壓縮後的順序一致性 (如排序、範圍查詢等等),這樣 DBMS 就可以在不完全解壓縮的情況下對資料進行比較操作。