A Tour of Computer Systems
本書的第一章會透過一個簡單的 hello world 範例來簡單介紹程式的生命週期,從程式碼的撰寫、編譯、連結、載入到執行的過程,以及電腦系統的基本架構,並會在後續的章節中詳細介紹這些概念。
一個簡單的 hello world 程式碼如下 :
#include <stdio.h>
int main() {
printf("Hello World\n");
return 0;
}
這個程式的生命週期可以從 source file 的儲存開始說起,一般來說檔案都是以 0 跟 1 的二進位形式儲存在硬碟中,稱為 bits,8 個 bits 組成一個 byte,而 1 byte 可以表示 256 () 種不同的值。 我們有非常多不同的表示方法來表示這些字元,例如 ASCII 又或者是後來的 Unicode 等等。
在電腦的世界中,無論是什麼資料都是由一連串的 bits 所組成的,我們需要了解上下文來知道這些 bits 所代表的意義,如字串、整數、浮點數、指標等。
Compilation
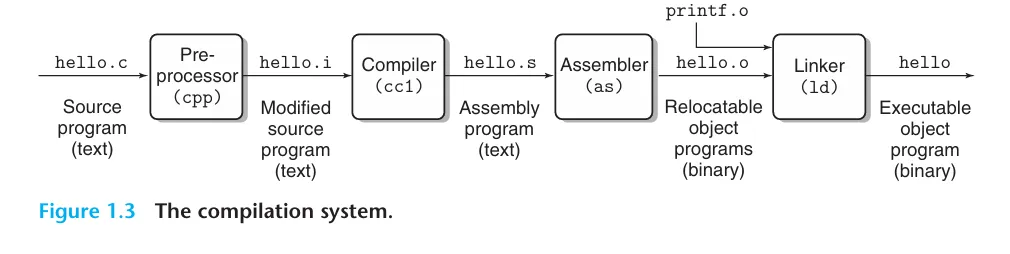
前面所提到的 hello.c 程式碼是一個由 C 語言寫成的高級程式語言,我們需要透過編譯器 (compiler) 來將它轉換成電腦可以理解的機器碼。
這個過程主要可以分為四個階段 :
- Preprocessing
- Compilation
- Assembly
- Linking
我們會在後續的章節中詳細介紹這些階段,這邊先簡單介紹每個階段的功能。
Preprocessing
在這個階段,編譯器會處理以 # 開頭的指令,例如 #include、#define 等等,並且移除註解,還會新增行號跟辨識檔案的方式以利除錯,最後產生一個 .i 的檔案。
gcc -E hello.c -o hello.i
Compilation
這個階段主要會包含語法分析、語意分析、優化等工作,並且產生對應的組合語言程式碼。
gcc -S hello.i -o hello.s
Assembly
在這個階段,組合語言程式碼會被轉換成機器碼 (machine code),也就是 CPU 可以直接執行的二進位指令,並且產生可重定位的目標檔案 (relocatable object program)。
可重定位的意思在於在這個階段產生的機器碼對於全域變數跟外部函式的位址還沒有被決定,它可以跟其他的 .o 檔案一起被連結成一個完整的可執行檔。
gcc -c hello.s -o hello.o
Linking
在這個階段,連結器 (linker) 會將多個目標檔案跟所需的函式庫結合在一起,並且解決所有的符號 (symbols) 以產生一個完整的可執行檔。
舉例來說,我們的 hello.c 程式碼中使用了 printf 函式,這個函式是定義在標準函式庫中的,所以我們需要把 printf.o 這個目標檔案跟 hello.o 一起連結,才能產生一個可以執行的檔案。
gcc hello.o -o hello
GNU (GNU's Not Unix) 是一個由 Richard Stallman 於 1984 年發起的專案,它是一個慈善機構,其目標是開發一個完整的、Unix-like 的作業系統,其原始碼可以不受限制地被修改或散佈,是現代自由軟體運動的基石。
GNU 專案開發了許多重要的軟體工具,包括 GNU Compiler Collection (GCC)、GNU Debugger (GDB)、GNU Emacs 等等,這些工具在現代軟體開發中扮演著重要的角色。
與 Linux Kernel 一起,GNU 工具組成了完整的作業系統,通常被稱為 GNU/Linux。
Hardware Organization
在了解了編譯的過程後,我們可以來看看這個程式是怎麼在電腦系統中被執行的,以及電腦系統的基本架構。
Devices
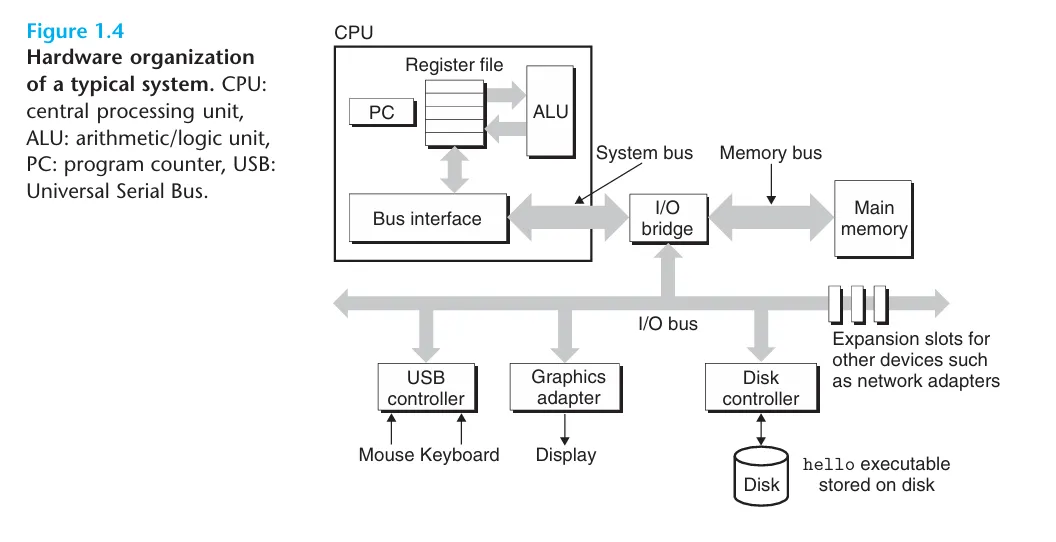
Bus
貫穿整個系統的一組電子管道,可以讓資料在各個元件之間傳輸。 通常是傳送固定大小的 byte,以 64 位元的系統來說,一次會傳送 8 個 byte (64 bits)。
I/O Devices
輸入輸出裝置,例如鍵盤、滑鼠、顯示器、網路卡、硬碟等等,每個設備都可以透過 controller 或是 adapter 來連接到 I/O bus 上,差別在於 controller 通常是內建在主機板上,而 adapter 則是透過擴充槽來連接的。
Memory
記憶體,通常是由 DRAM (Dynamic Random Access Memory) 組成,負責儲存程式碼跟資料,CPU 可以直接存取記憶體中的資料。
從邏輯上來說,記憶體可以被視為一個巨大的陣列,每個位置都有一個位址 (address)。
CPU
CPU (Central Processing Unit) 是系統的核心計算單元,負責依據 ISA (Instruction Set Architecture) 來執行記憶體中的指令。
其內部包含了很多重要的元件 :
- program counter (PC) : 一個 word 大小的暫存器,存放下一條要執行的指令的位址
- register file : 一組數量有限但極高速的暫存器,用來暫存運算過程中的資料
- arithmetic logic unit (ALU) : 執行算術與邏輯運算,例如加減乘除、AND、OR、NOT
- floating point unit (FPU) : 專門處理浮點數運算的單元
- memory management unit (MMU) : 進行虛擬位址到實體位址的轉換,實現了後面會提到的虛擬記憶體機制
How to Run a Program
在了解了簡單的硬體架構後,我們可以來看看之前寫的 hello world 程式是怎麼被執行的。
首先,當我們在終端機中輸入 ./hello 時,shell 會把這些字元逐一讀入 register 中,再放到記憶體內。
接著當我們按下 Enter 後,shell 會呼叫一系列的指令來把硬碟中的 hello 程式載入到記憶體中,這個技術稱為 DMA (Direct Memory Access),可以讓 I/O 裝置直接存取記憶體,而不需要經過 CPU。
當程式被載入到記憶體中後,CPU 就可以開始執行 main() 函數的內容,這些機器碼會把 Hello World! 從記憶體複製到 register 中,最後再傳給負責輸出到螢幕的 I/O 裝置。
Storage
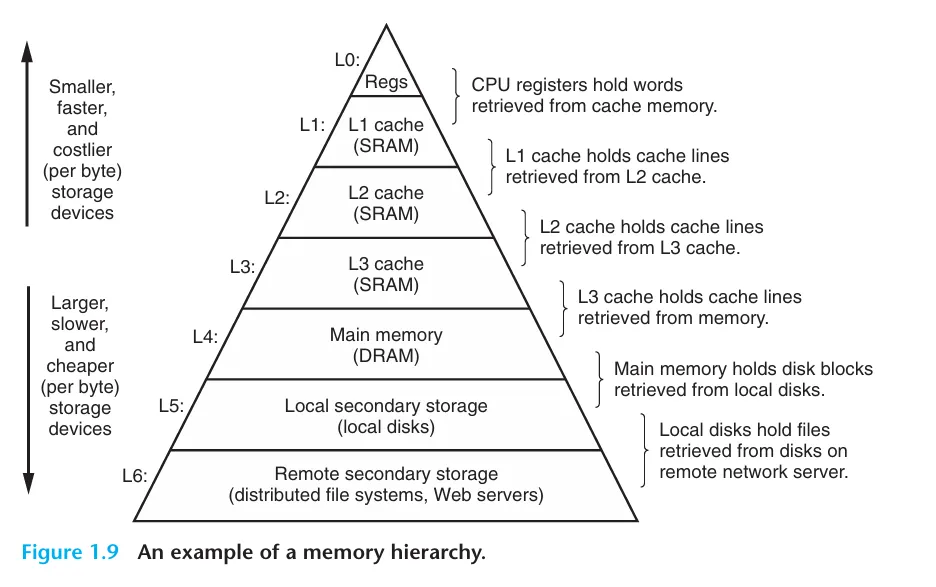
在執行的過程中,我們會花費大量時間在複製資料上,因此,我們設計了多層次的快取在各個元件之間,以減少資料傳輸的時間。
Operating System
回到一開始的程式執行過程,當 shell 在加載 hello 程式時,實際上它並沒有對硬體進行直接的存取,而是透過作業系統 (Operating System) 來進行。
作業系統是一個介於應用程式跟硬體之間的軟體層,所有軟體對硬體的存取都必須透過作業系統來進行。 它有兩個基本功能,分別是防止硬體被錯誤的程式碼破壞,以及向應用程式提供一個簡單且一致的介面來存取硬體。
通常來說,作業系統通過進程、虛擬記憶體、檔案系統的抽象化來達成這些目標。 其中檔案是對 I/O 裝置的抽象、進程是對 CPU 的抽象、虛擬記憶體是對記憶體的抽象。
在 1970-1980 年代,各家作業系統廠商各自發展出不同的系統介面,導致應用程式無法跨平台執行。 為了解決這個問題,IEEE 在 1988 年制定了一個標準,稱為 POSIX (Portable Operating System Interface),它定義了一組標準的作業系統介面,讓應用程式可以在不同的作業系統上執行。
Process
當 hello 程式被載入到記憶體中後,作業系統會提供一種假象,讓每個程式都以為自己是唯一在執行的程式,可以獨佔 CPU 跟記憶體,這個假象稱為進程 (process)。
進程是作業系統分配資源的基本單位,每個進程都有自己的虛擬地址空間、程式計數器、暫存器、堆疊等資源,彼此之間互不干擾。
當作業系統需要切換到另一個進程時,它會保存當前進程的狀態 (context),並載入下一個進程的狀態,這個過程稱為上下文切換 (context switch),如下圖所示。
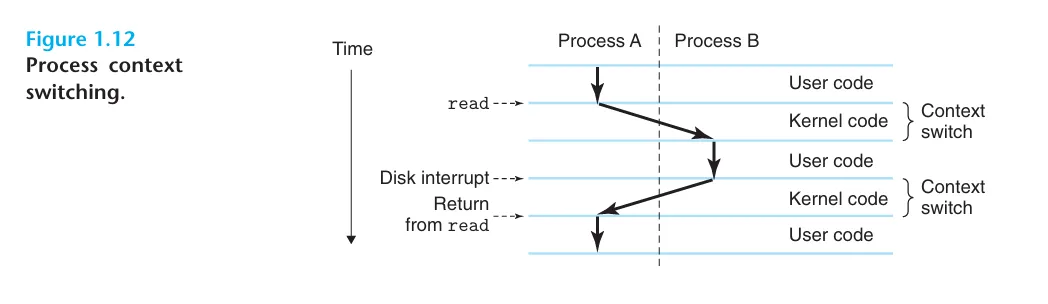
Process 的切換是由作業系統的 kernel 來管理的,它會執行一個 system call 來把控制權轉給 kernel,然後 kernel 就會執行被請求的服務,最後再把控制權還給 user program。
Thread
在現代系統中由於網路應用程式的興起,單一進程往往需要同時處理多個任務,例如同時處理多個使用者的請求,這時候我們可以使用線程 (thread) 來達成這個目標。
線程是進程內部的一個執行單位,擁有自己的程式計數器、暫存器,但是需要與同一個進程內的其他線程共享記憶體空間 (heap)。
Virtual Memory
虛擬記憶體同樣是作業系統提供的一種抽象,讓每個進程都以為自己擁有一個完整的、連續的記憶體空間,實際上這些記憶體空間是被分割成多個頁 (page),並且可以被映射到不同的實體記憶體位置。
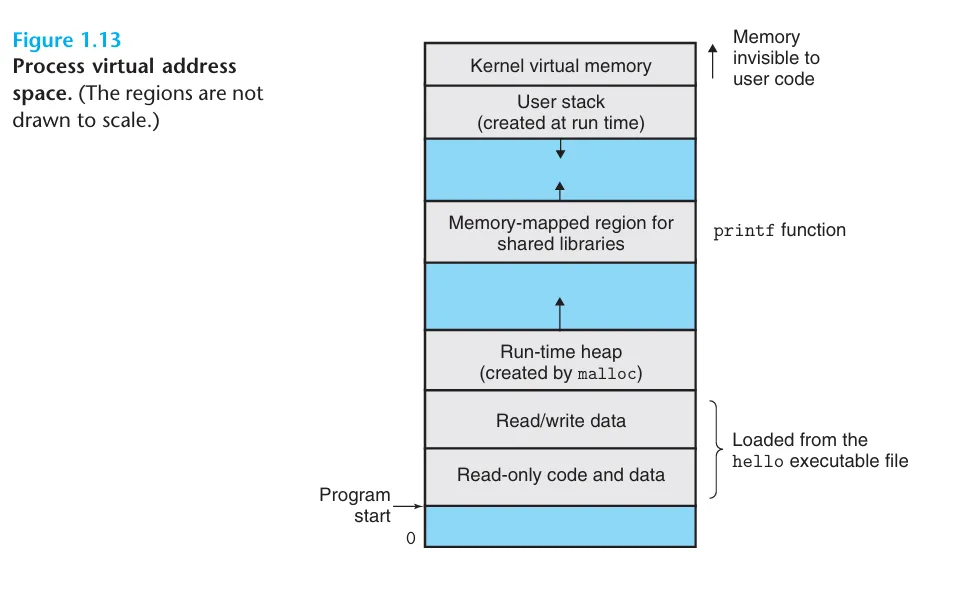
File
檔案系統可以讓應用程式可以以一種簡單且一致的方式來存取 I/O 裝置。 檔案系統會把 I/O 裝置抽象成一個巨大的位元組陣列,應用程式可以透過檔案描述符 (file descriptor) 來存取這些位元組。
Network
可以使用 ssh 或 telnet 等工具來遠端連接到其他的電腦系統,並且透過網路來傳輸資料。
Important Concepts
Amdahl's Law
Amdahl's Law 是一個用來描述系統加速比的定律,它指出當我們加速系統中的某個部分時,整個系統的加速比是受到該部分的重要性和加速比的影響。
其中, 是原本的執行時間, 是加速後的執行時間, 是被加速部分佔整個系統的比例, 是該部分的加速比。
假設系統的某個部分佔了 60% 的時間 (),如果我們把這個部分加速 3 倍 (),則整個系統的加速比為 。
Concurrency and Parallelism
Concurrency 是指在同一時間內有多個任務在進行,但不一定是同時執行的,可能是透過時間切片 (time slicing) 的方式來達成。
Parallelism 則是指在同一時間內有多個任務同時執行,通常是透過多核心或多處理器的方式來達成。
Thread-level Concurrency
早期的單核心處理器,即使支援多工,實際上依舊一次只能執行一條指令流程,透過快速切換不同的進程來達成多工的效果。
在這之後,開始出現了多核心的 CPU,每個核心都能獨立執行自己的控制流,並透過共享的快取階層和記憶體介面協同工作。
除了多核心,還有另一種技術叫做超執行緒 (Hyperthreading)。 與多核心不同,這種技術並不是複製完整的處理器,而是複製部分控制相關的硬體 (例如程式計數器與暫存器檔),並讓多個執行緒共享同一套運算單元。 其好處是當某一執行緒因為等待記憶體存取而停頓時,另一條執行緒仍能利用運算資源,避免核心閒置。
Instruction-level Parallelism
在早期的處理器中,一條指令往往需要數個甚至數十個 clock cycle 才能完成。 後來,工程師發現可以把指令的執行過程拆解成多個階段,並讓這些階段在不同指令之間重疊進行。 這就是管線化 (pipelining) 的概念,就像工廠生產線一樣,不同工人可以同時處理產品的不同部分,讓整體產能大幅提升。
SIMD
在最底層的地方,許多現代的處理器還支援單指令多資料 (Single Instruction, Multiple Data, SIMD) 的運算模式。 顧名思義,就是可以讓一條指令同時操作多組資料。
這對影像處理、音訊編碼、影片播放或科學運算等應用特別有效,因為這些應用往往需要對大量相似的資料重複執行相同的操作。
Abstraction
除了前面所提及的三個主要抽象 (檔案、進程、虛擬記憶體) 之外,我們還可以把虛擬機當成整個作業系統的抽象。